【调度算法】开放车间调度问题遗传算法
问题描述
开放车间调度问题可以描述为:有n个需要加工的工件,每个工件有m道工序,需要在m台不同的机器上进行加工,每道工序的加工时间都是已知的,但是每个工件的加工顺序是任意的;一台机器在同一个时刻只能加工一个工件,一个工件不能同时在两台机器上加工;每个工件在同一时刻也只能在某一台机器上加工;最终需要求得一组机器与工件的排列组合使加工完所有工件所用的时间最短,效率最高。
| 工件 | A | B | C | D | E | F | G | H | I |
|---|---|---|---|---|---|---|---|---|---|
| 工件编号 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 机器1加工时间 | 4 | 7 | 6 | 5 | 8 | 3 | 5 | 5 | 10 |
| 机器2加工时间 | 7 | 10 | 1 | 5 | 7 | 5 | 8 | 7 | 3 |
| 机器3加工时间 | 7 | 1 | 8 | 9 | 3 | 7 | 8 | 6 | 1 |
| 到达时间 | 3 | 2 | 4 | 5 | 3 | 2 | 1 | 8 | 6 |
| 交货期 | 46 | 35 | 49 | 41 | 40 | 48 | 49 | 37 | 36 |
设备数目:3
目标函数
最小化交货期总延时时间
编码说明
记机器数为m,从0开始编号为0,1,...,m-1,记工件数为n,同样从0开始编号。
遗传算法的编码方式我是参考的Genetic Algorithms for Open Shop Scheduling and Re-Scheduling这篇论文,论文中是用两位整数字符串来表示工件和所分配的机器的对应关系,如字符串'43'表示编号为3的工件被分配给了编号为4的机器进行加工,我觉得字符串跟整数之间的转换挺麻烦的,就换成了元组,即元组(4,3)表示编号为3的工件被分配给了编号为4的机器进行加工(其实这种编码方式我暂时看不出能有啥出类拔萃的效果,单纯因为它不是主流的编码方式,又比较好理解,所以做了一个尝试)。
另外,遗传算法中的cal_start_and_finish_time()函数,参考了GitHub上的https://github.com/0MarijaS/OpenShopScheduling,本来挺简单的一个东西,之前自己写一直写不明白,看了代码后才知道,我他喵一直都陷入了一个惯性思维里边,没把实际联系起来,可能也是编码习惯的问题吧。
运算结果
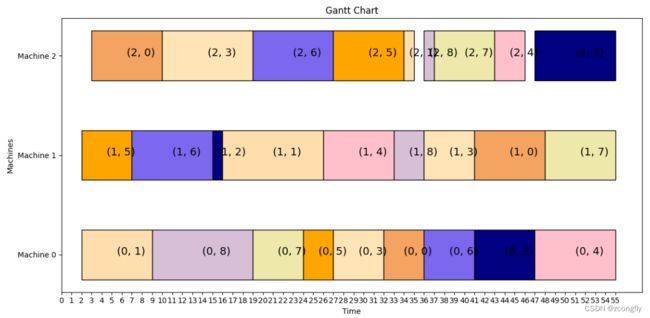
最佳调度顺序和分配: [(0, 1), (0, 8), (1, 5), (2, 0), (2, 3), (1, 6), (0, 7), (2, 6), (1, 2), (1, 1), (0, 5), (2, 5), (0, 3), (2, 1), (1, 4), (0, 0), (0, 6), (1, 8), (2, 8), (2, 7), (0, 2), (0, 4), (2, 2), (2, 4), (1, 3), (1, 0), (1, 7)]
最小交货期延时时间: 36

python代码
import random
import numpy as np
import matplotlib.pyplot as plt
import copy
# 定义遗传算法参数
POP_SIZE = 100 # 种群大小
MAX_GEN = 100 # 最大迭代次数
CROSSOVER_RATE = 0.7 # 交叉概率
MUTATION_RATE = 0.2 # 变异概率
def sort_by_id(id, sequence):
# 根据id对sequence进行排序
new_sequence = sequence[:]
for i in range(len(id)):
sequence[i] = new_sequence[id[i]]
# 随机生成初始种群,这里用一个元组表示工件和机器的分配关系,如元组(0,1)表示编号为1的工件在编号为0的机器上加工,工件和机器编码都是从0开始
def get_init_pop(pop_size):
pop = []
job = [(m, n) for m in range(machine_num) for n in range(len(job_id))]
for _ in range(pop_size):
random.shuffle(job)
pop.append(job[:])
return pop
# 检查工件是否能够插入排程好的机器的间隙
def check_job(start, limit, duration, job_activity):
if len(job_activity) == 0:
if start + duration <= limit:
return True, start
elif len(job_activity) == 1:
if job_activity[0][0] != 0 and job_activity[0][0] >= start + duration:
return True, start
else:
if job_activity[0][1] + duration <= limit:
return True, max(job_activity[0][1], start)
else:
end = start + duration
j = 0
while end <= limit and j < len(job_activity) - 1:
if job_activity[j][0] <= start < job_activity[j][1]:
start = job_activity[j][1]
end = start + duration
if start >= job_activity[j][1] and end <= job_activity[j + 1][0]:
return True, start
j += 1
return False, -1
def cal_start_and_finish_time(operations, pro_times, arr_times, machine_num):
# operations: list[tuple()] 一个列表,列表中元素为二元组(机器编号,工件编号)
jobs = [[] for _ in range(len(operations) // machine_num)]
solution = [[] for _ in range(machine_num)] # 封装一个有效的调度方案,(开始时间, 结束时间, 操作编号)
for operation in operations:
machine, job = operation[0], operation[1]
duration = pro_times[machine][job] # 定位加工时间
machine_activity = solution[machine] # 当前时刻当前机器是否正在加工
job_activity = jobs[job] # 当前时刻当前工件是否正在加工
# print(f'==========operation={operation}===========')
# print("job_activity=",job_activity)
# print("machine_activity=",machine_activity)
fit, start, limit = False, -1, float('inf')
if len(machine_activity) == 0: # 如果机器空闲
start = arr_times[operation[1]]
fit, start = check_job(start, limit, duration, job_activity)
elif len(machine_activity) == 1 and machine_activity[0][
0] > arr_times[operation[1]]: # 如果该机器只有一个操作,且该操作开始时间大于当前操作对应工件的到达时间,则判断一下当前操作是否可以排在该操作的前面
start = arr_times[operation[1]]
limit = machine_activity[0][0]
fit, start = check_job(start, limit, duration, job_activity)
elif len(machine_activity) == 1 and machine_activity[0][0] <= arr_times[
operation[1]]: # 如果该机器只有一个操作,且该操作开始时间小于等于当前操作对应工件的到达时间,则将当前操作排在该操作后边
start = max(arr_times[operation[1]], machine_activity[0][1])
fit, start = check_job(start, limit, duration, job_activity)
else: # 如果该机器有两个或两个以上的操作,则看下操作与操作之间是否存在足够的间隙可容纳当前操作
for i in range(len(machine_activity) - 1):
start = max(arr_times[operation[1]], machine_activity[i][1])
limit = machine_activity[i + 1][0]
options = []
if limit - start >= duration:
fit, start = check_job(start, limit, duration, job_activity)
if fit:
options.append((start, limit - (start + duration)))
if len(options) > 0:
options.sort(key=lambda x: x[1])
start = options[0][0]
fit = True
if fit and start + duration <= limit:
jobs[job].append((start, start + duration)) # (开始时间,结束时间)
solution[machine].append((start, start + duration, operation))
jobs[job].sort() # 升序排序(时间是从小到大排列)
solution[machine].sort()
else:
start = 0
if len(machine_activity) >= 1:
start = machine_activity[-1][1]
if len(job_activity) >= 1:
start = max(start, job_activity[-1][1])
jobs[job].append((start, start + duration))
solution[machine].append((start, start + duration, operation))
# print(jobs)
# print(solution)
return solution
# TODO: 开始时间和结束时间计算有问题,这个函数废了
# 将输入的一维job进行二维转换,计算start_time和finish_time
def cal_start_and_finish_time_failed(job):
# 按照输入的工序进行排序
sorted_job = sorted(job, key=lambda x: x[0]) # 按照设备排序
sorted_pro_time = [pro_times[j[0]][j[1]] for j in sorted_job] # 对应的加工时间
# 转换成二维列表
sorted_job = [sorted_job[i:i + len(job_id)] for i in range(0, len(sorted_job), len(job_id))]
sorted_pro_time = [sorted_pro_time[i:i + len(job_id)] for i in range(0, len(sorted_pro_time), len(job_id))]
# 对每台机器的总加工时间进行加和,用于排序
# 这里直接规定当各机器无法同时开工时,选择总加工时间最长的机器最先开工
start_seq = [i[0] for i in sorted(enumerate(pro_times), key=lambda x: sum(x[1]), reverse=True)] # 机器开始加工的顺序
start_time = [[] for _ in range(len(sorted_job))]
finish_time = [[] for _ in range(len(sorted_job))]
# 第一台开工的机器的第一个工件的start_time和finish_time
start_time[start_seq[0]].append(arr_times[sorted_job[start_seq[0]][0][1]])
finish_time[start_seq[0]].append(start_time[start_seq[0]][0] + sorted_pro_time[start_seq[0]][0])
# 单独先把第一个开工的机器的start_time和finish_time计算出来
for j in range(1, len(pro_times[0])):
start_time[start_seq[0]].append(
max(finish_time[start_seq[0]][-1], arr_times[sorted_job[start_seq[0]][j][1]]))
finish_time[start_seq[0]].append(start_time[start_seq[0]][j] + sorted_pro_time[start_seq[0]][j])
# 计算每台机器的第一个工件的开始加工时间
for i in range(1, len(start_seq)):
# 一个工件不能同时在两台机器加工
start_time[start_seq[i]].append(-1)
for k in range(i):
if sorted_job[start_seq[i]][0][1] == sorted_job[start_seq[k]][0][1]:
start_time[start_seq[i]][-1] = finish_time[start_seq[k]][0]
elif k == i - 1 and start_time[start_seq[i]][-1] == -1:
start_time[start_seq[i]][-1] = arr_times[sorted_job[start_seq[i]][0][1]]
finish_time[start_seq[i]].append(start_time[start_seq[i]][0] + sorted_pro_time[start_seq[i]][0])
# 计算其他行列
for i in range(1, len(start_seq)):
for j in range(1, len(pro_times[0])):
start_time[start_seq[i]].append(-1)
for k in range(i):
# 写着写着突然发现不对,还是需要判断前边两台机器上正在加工的工件是不是当前机器即将要加工的工件
# 感觉这里把自己绕进去了,实际上,当某个工件在当前机器上的加工时间特别大,可能是其在别的机器上加工时间的几倍或者是别的工件加工时间之和的时候,这个if判断还要向前或者向后搜索很多轮
# 但是如果真有这样一道工序存在,应该不需要什么算法直接可以看出结果,所以这里只搜索相邻的两轮
# TODO: but,逻辑还是欠严谨,这是一段失败的代码,或许证明这思路就不行?先到这里吧,麻了
if finish_time[start_seq[i]][j - 1] <= finish_time[start_seq[k]][j - 1]:
if sorted_job[start_seq[i]][j][1] == sorted_job[start_seq[k]][j - 1][1]:
start_time[start_seq[i]][-1] = max(finish_time[start_seq[i]][-1],
finish_time[start_seq[k]][j - 1])
elif k == i - 1 and start_time[start_seq[i]][-1] == -1:
start_time[start_seq[i]][-1] = max(finish_time[start_seq[i]][-1],
arr_times[sorted_job[start_seq[i]][j][1]])
elif finish_time[start_seq[k]][j - 1] < finish_time[start_seq[i]][j - 1] <= finish_time[start_seq[k]][
j]:
if sorted_job[start_seq[i]][j][1] == sorted_job[start_seq[k]][j][1]:
start_time[start_seq[i]][-1] = max(finish_time[start_seq[i]][-1], finish_time[start_seq[k]][j])
elif k == i - 1 and start_time[start_seq[i]][-1] == -1:
start_time[start_seq[i]][-1] = max(finish_time[start_seq[i]][-1],
arr_times[sorted_job[start_seq[i]][j][1]])
else:
start_time[start_seq[i]][-1] = max(finish_time[start_seq[i]][-1],
arr_times[sorted_job[start_seq[i]][j][1]])
finish_time[start_seq[i]].append(start_time[start_seq[i]][j] + sorted_pro_time[start_seq[i]][j])
return sorted_job, sorted_pro_time, start_time, finish_time
# 计算染色体的适应度(makespan) 以最小化交货期延时为目标函数,这里计算的是交货期总延时时间
def fitness(job):
solution = cal_start_and_finish_time(job, pro_times, arr_times,
machine_num)
finish_time = [[ft[1] for ft in sub] for sub in solution]
# 按照输入的工序进行排序
sorted_job = sorted(job, key=lambda x: x[0]) # 按照设备排序
# 转换成二维列表
sorted_job = [sorted_job[i:i + len(job_id)] for i in range(0, len(sorted_job), len(job_id))]
# 计算适应度,目标函数是最小化总延货期
max_finish_time = [] # 记录每个工件在各机器上的最后的完工时间
for k in range(len(job_id)):
# 定位,定位到sorted_job中所有元组的第二个元素为i的索引
indices = [(i, j) for i, row in enumerate(sorted_job) for j, (x, y) in enumerate(row) if y == k]
max_ft = 0
for id in indices:
max_ft = finish_time[id[0]][id[1]] if finish_time[id[0]][id[1]] > max_ft else max_ft
max_finish_time.append(max_ft)
delay_time = [max(mf - d, 0) for mf, d in zip(max_finish_time, deadlines)] # 总延货期
# print("sorted_job=",sorted_job)
# print("sorted_pro_time=",sorted_pro_time)
# print("finish_time=",finish_time)
# print("delay_time=",delay_time)
# print("sum(delay_time)=",sum(delay_time))
return sum(delay_time)
# 选择父代,这里选择POP_SIZE/2个作为父代
def selection(pop):
fitness_values = [1 / fitness(job) for job in pop] # 以最小化交货期总延时为目标函数,这里把最小化问题转变为最大化问题
total_fitness = sum(fitness_values)
prob = [fitness_value / total_fitness for fitness_value in fitness_values] # 轮盘赌,这里是每个适应度值被选中的概率
# 按概率分布prob从区间[0,len(pop))中随机抽取size个元素,不允许重复抽取,即轮盘赌选择
selected_indices = np.random.choice(len(pop), size=POP_SIZE // 2, p=prob, replace=False)
return [pop[i] for i in selected_indices]
# 交叉操作 这里是单点交叉
def crossover(job_p1, job_p2):
cross_point = random.randint(1, len(job_p1) - 1)
job_c1 = job_p1[:cross_point] + [gene for gene in job_p2 if gene not in job_p1[:cross_point]]
job_c2 = job_p2[:cross_point] + [gene for gene in job_p1 if gene not in job_p2[:cross_point]]
return job_c1, job_c2
# 变异操作,因为元组是不可变类型,这里采取的变异方式是随机交换两个点
def mutation(job):
while True:
index1 = random.randint(0, len(job) - 1)
index2 = random.randint(0, len(job) - 1)
if index1 != index2:
break
temp = job[index1]
job[index1] = job[index2]
job[index2] = temp
return job
# 主遗传算法循环
# 以最小化延迟交货时间为目标函数
def GA(): # 工件加工顺序是否为无序
best_job = [(m, n) for m in range(machine_num) for n in range(len(job_id))] # 初始化最佳个体
best_makespan = fitness(best_job) # 获得最佳个体的适应度值
# 创建一个空列表来存储每代的适应度值
fitness_history = [best_makespan]
pop = get_init_pop(POP_SIZE)
for _ in range(1, MAX_GEN + 1):
pop = selection(pop) # 选择
new_population = []
while len(new_population) < POP_SIZE:
parent1, parent2 = random.sample(pop, 2) # 不重复抽样2个
if random.random() < CROSSOVER_RATE:
child1, child2 = crossover(parent1, parent2) # 交叉
new_population.extend([child1, child2])
else:
new_population.extend([parent1, parent2])
pop = [mutation(job) if random.random() < MUTATION_RATE else job for job in new_population] # 变异
best_gen_job = min(pop, key=lambda x: fitness(x))
best_gen_makespan = fitness(best_gen_job) # 每一次迭代获得最佳个体的适应度值
# print(job_id)
# print(best_gen_job)
# print(best_gen_makespan,best_makespan,best_gen_makespan < best_makespan)
if best_gen_makespan < best_makespan: # 更新最小fitness值
best_makespan = best_gen_makespan
best_job = copy.deepcopy(best_gen_job)
fitness_history.append(best_makespan) # 把本次迭代结果保存到fitness_history中(用于绘迭代曲线)
# print(best_job)
# print(best_makespan)
# print('==========================')
# 绘制迭代曲线图
plt.plot(range(MAX_GEN + 1), fitness_history)
plt.xlabel('Generation')
plt.ylabel('Fitness Value')
plt.title('Genetic Algorithm Convergence')
plt.show()
return best_job, best_makespan
def plot_gantt(operations):
solution = cal_start_and_finish_time(operations, pro_times, arr_times, machine_num)
# 准备一系列颜色
colors = ['blue', 'yellow', 'orange', 'green', 'palegoldenrod', 'purple', 'pink', 'Thistle', 'Magenta', 'SlateBlue', 'RoyalBlue', 'Cyan', 'Aqua', 'floralwhite', 'ghostwhite', 'goldenrod', 'mediumslateblue', 'navajowhite', 'moccasin', 'white', 'navy', 'sandybrown', 'moccasin']
# colors = ['r', 'g', 'b', 'm', 'c', 'y', 'w', 'o', 'p']
job_colors = random.sample(colors, len(job_id))
start_times = [[-1 for _ in range(len(solution[0]))] for _ in range(len(solution))]
end_times = [[-1 for _ in range(len(solution[0]))] for _ in range(len(solution))]
job_decodes = [[-1 for _ in range(len(solution[0]))] for _ in range(len(solution))]
for i in range(len(solution)):
for j in range(len(solution[0])):
start_times[i][j] = solution[i][j][0]
end_times[i][j] = solution[i][j][1]
job_decodes[i][j] = solution[i][j][2] # (机器编号, 工件编号)
# 创建图表和子图
plt.figure(figsize=(12, 6))
# 绘制工序的甘特图
for i in range(len(start_times)):
for j in range(len(start_times[i])):
plt.barh(i, end_times[i][j] - start_times[i][j], height=0.5, left=start_times[i][j],
color=job_colors[job_decodes[i][j][1]], edgecolor='black')
plt.text(x=(start_times[i][j] + end_times[i][j]) / 2, y=i, s=job_decodes[i][j], fontsize=14)
# 设置纵坐标轴刻度为机器编号
machines = [f'Machine {i}' for i in range(len(start_times))]
plt.yticks(range(len(machines)), machines)
# 设置横坐标轴刻度为时间
# start = min([min(row) for row in start_times])
start = 0
end = max([max(row) for row in end_times])
plt.xticks(range(start, end + 1))
plt.xlabel('Time')
# 图表样式设置
plt.ylabel('Machines')
plt.title('Gantt Chart')
# plt.grid(axis='x')
# 自动调整图表布局
plt.tight_layout()
# 显示图表
plt.show()
if __name__ == '__main__':
# n个工件,每个工件都需要到m台不同机器上各加工一次,加工顺序任意,每台机器上的加工时间已知
job_id = [0, 1, 2, 3, 4, 5, 6, 7, 8] # 工件编号
pro_times = [[4, 7, 6, 5, 8, 3, 5, 5, 10],
[7, 10, 1, 5, 7, 5, 8, 7, 3],
[7, 1, 8, 9, 3, 7, 8, 6, 1]] # 加工时间
arr_times = [3, 2, 4, 5, 3, 2, 1, 8, 6] # 到达时间
deadlines = [46, 35, 49, 41, 40, 48, 49, 37, 36] # 交货期
machine_num = 3 # 3台完全相同的并行机,编号为0,1,2
best_job, best_makespan = GA()
print("最佳调度顺序和分配:", best_job)
print("最小交货期延时时间:", best_makespan)
plot_gantt(best_job)