爬取携程景点评论数据【最新方法】,分析AJAX实现页数跳转的爬取方法
本文仅供技术学习使用,欢迎转载,转载请注明出处
因为朋友参加数学建模,需要景点数据,而我刚好懂一点点,就帮他写爬虫代码。在网上搜索到一些爬虫方法,但在获取景点ID时,发现现在携程的Request Payload参数发生变化,导致原本的一些参数,如翻页的请求Fetch,景点ID:viewid没有了,经过分析发现使用了poiID作为新的参数,故自己重新针对新的接口参数重新写了爬虫,同时对爬取通过ajax实现的翻页的数据进行总结,如有错误,还望包涵并指出!
PS:携程原本的接口参数还是能正常使用,也可以正常爬取。就是查不到那些借口参数
如果有人知道原因,或者找到viewid的方法,还望不吝赐教
爬取携程景点评论数据
- 分析过程
-
- 页数跳转两种方式
- 分析评论数据请求接口
- 分析评论返回数据
- 源码拆解
-
- 将需要爬取的景点信息写入数组
- 根据数组,修改请求参数,进行第一次请求
- 确定评论总页数
- 创建写入csv文件
- 通过循环遍历页数,爬取评论数据并保存
- 源码分享
分析过程
前言提到,携程的Request Payload参数发送了变化,需要重新分析接口参数和返回结果。
这里简单提一下为什么需要通过接口获取评论数据:
页数跳转两种方式
因为评论数过多,所有网页大多采用分页的形式展示,用户可以通过点击相应的页数跳转
而跳转页数目前有两种实现方式:
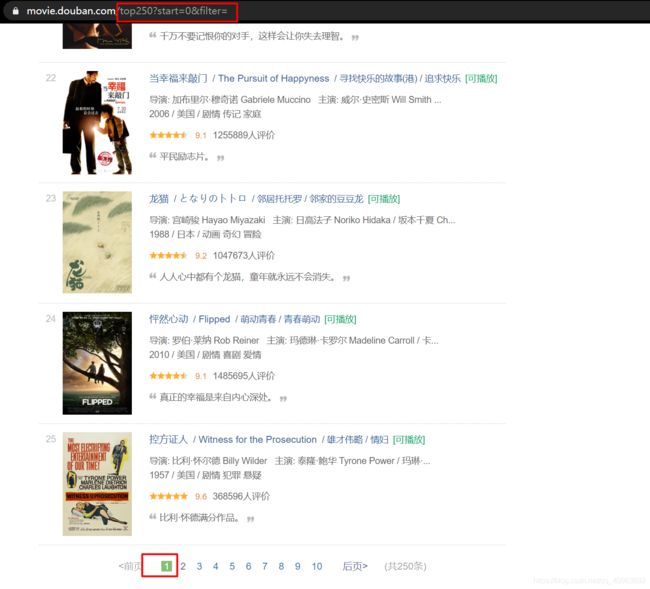
第一种是通过网址参数,如豆瓣网。常见的爬取豆瓣电影top250就是这种方式。
我们进入https://movie.douban.com/top250,查看页面数据。
第一页:
第二页:
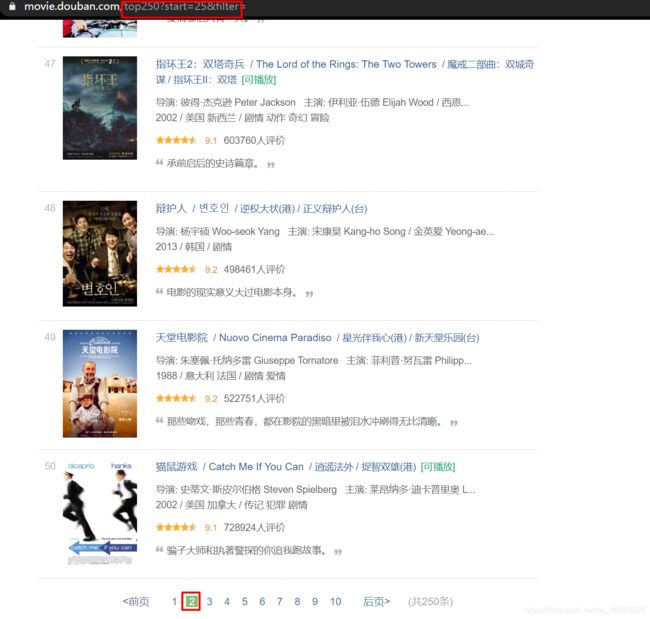
可以看到,这个网页是通过网址参数"start="的变化,跳转到不同的页面。
这样在爬取数据时,只需要变化网址参数就可以获取不同页数的数据,获取难度相对简单。
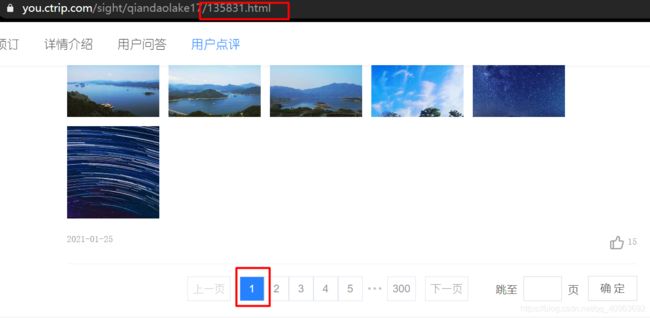
而第二种就是携程这样,通过ajax技术,动态加载评论数据
第一页:
第二页:
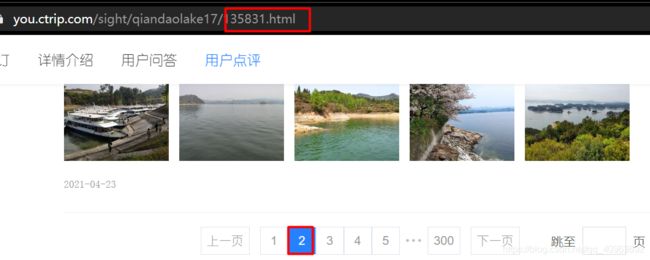
可以看到网址未发生变化,但数据已经加载进来。
对于这种方法,我们需要去查看它的调用接口,并使用固定参数去获取返回数据,获取难度相对增大。
言归正传,本文不对以上两种方式做赘述,只针对携程景点评论数据进行分析
分析评论数据请求接口
我们在携程景点评论页面按’F12’进入元素检测,点击’Network’查看网络资源。因为我们需要的是评论页数变化时的请求数据,为了防止其他数据干扰,我们先清空所有数据,再点击第二页,加载数据,可以看到此时所有网络请求资源被嗅探到。等数据不再变化时,停止监听,此时看到的就是请求评论第二页的所有数据。
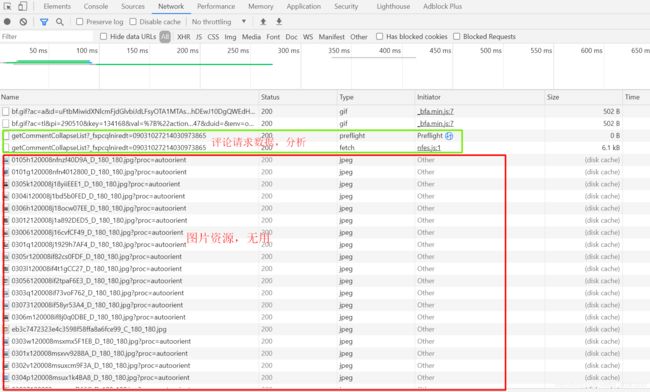
从图上可以看到,这些数据里一部分是图片资源,因为我们需要的是用户评论数据,所以不用管。另外两个文件是评论请求数据,从文件名:getCommentCollapseList 也可以判断处理。
再看文件类型Type,一个是preflight request(预检请求),这个是为了确保数据安全,详细的可以了解这篇文章(侵删)
另一个就是我们的主角,Fetch API。我们点击这个文件,可以查看Hearders里的内容
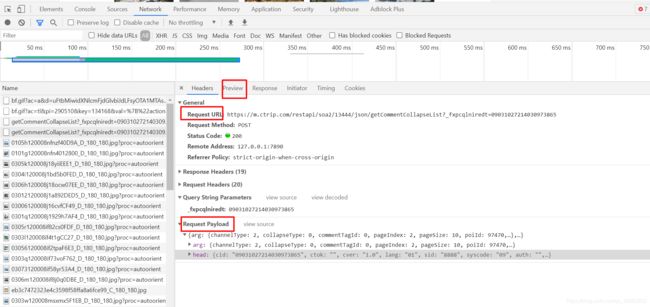
在这些里面,我们需要关注的是Request URL:和Request Payload
Request URL:https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList
可以推测这个是请求的地址,而且是通用接口网址,评论信息都是通过这个网址获取的
Request Payload,这是一种请求方式,我们只需要关注它的具体参数,把它拿出来
"arg":{
"channelType":2,
"collapseType":0,
"commentTagId":0,
"pageIndex":2,
"pageSize":10,
"poiId":97470,
"sourceType":1,
"sortType":3,
"starType":0
},
"head":{
"cid":"09031027214030973865",
"ctok":"",
"cver":"1.0",
"lang":"01",
"sid":"8888",
"syscode":"09",
"auth":"",
"xsid":"",
"extension":[]
}
我们可以看到这是个JSON格式,但我们不清楚每个参数的具体含义,这时候先别急,有一个简单的方法,那就是先打开一个新的景点,用同样的方法获取这些参数,通过简单的对比法,确定变化的参数。而这个参数,很有可能就是不同景点的区别。
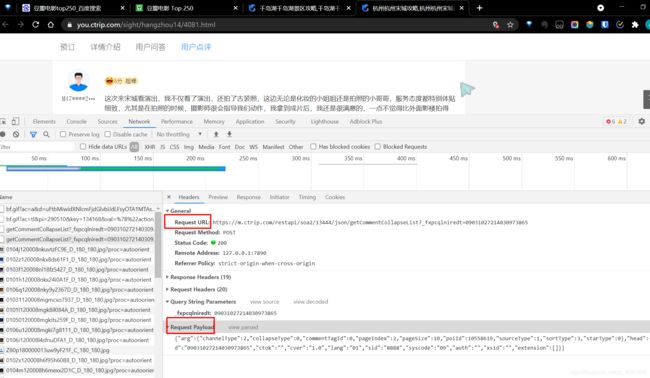
我们重新打开”宋城“的网页,如法炮制,查看请求参数。
可以看到Request URL不变,进而印证我们之前的猜测。
再拿出Request Payload
"arg":{
"channelType":2,
"collapseType"