Redis-List专题
List类型是一个双端链表的结构,容量是2的32次方减1个元素,即40多亿个;
其主要功能有push、pop、获取元素等;一般应用在栈、队列、消息队列等场景。
1.高并发淘宝聚划算商品列表
### 一、需求分析:淘宝聚划算功能
https://ju.taobao.com/
这张页面的特点:
1.数据量少,才13页
2.高并发,请求量大。
### 二、高并发的淘宝聚划算实现技术方案
像聚划算这种高并发的功能,绝对不可能用数据库的!
一般的做法是先把数据库中的数据抽取到redis里面。采用定时器,来定时缓存。
这张页面的特点,数据量不多,才13页。最大的特点就要支持分页。
redis的 list数据结构天然支持这种高并发的分页查询功能。
具体的技术方案采用list 的lpush 和 lrange来实现。
```
## 先用定时器把数据刷新到list中
127.0.0.1:6379> lpush jhs p1 p2 p3 p4 p5 p6 p7 p8 p9 p10
(integer) 10
## 用lrange来实现分页
127.0.0.1:6379> lrange jhs 0 5
1) "p10"
2) "p9"
3) "p8"
4) "p7"
5) "p6"
6) "p5"
127.0.0.1:6379> lrange jhs 6 10
1) "p4"
2) "p3"
3) "p2"
4) "p1"
```
案例实战:SpringBoot+Redis实现淘宝聚划算功能
#### 步骤1:采用定时器把特价商品都刷入redis缓存中
```
@Service
@Slf4j
public class TaskService {
@Autowired
private RedisTemplate redisTemplate;
@PostConstruct
public void initJHS(){
log.info("启动定时器..........");
new Thread(()->runJhs()).start();
}
/**
* 模拟定时器,定时把数据库的特价商品,刷新到redis中
*/
public void runJhs() {
while (true){
//模拟从数据库读取100件特价商品,用于加载到聚划算的页面中
List list=this.products();
//采用redis list数据结构的lpush来实现存储
this.redisTemplate.delete(Constants.JHS_KEY);
//lpush命令
this.redisTemplate.opsForList().leftPushAll(Constants.JHS_KEY,list);
try {
//间隔一分钟 执行一遍
Thread.sleep(1000*60);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("runJhs定时刷新..............");
}
}
/**
* 模拟从数据库读取100件特价商品,用于加载到聚划算的页面中
*/
public List products() {
List list=new ArrayList<>();
for (int i = 0; i < 100; i++) {
Random rand = new Random();
int id= rand.nextInt(10000);
Product obj=new Product((long) id,"product"+i,i,"detail");
list.add(obj);
}
return list;
}
}
```
#### 步骤2:redis分页查询
```
/**
* 分页查询:在高并发的情况下,只能走redis查询,走db的话必定会把db打垮
*/
@GetMapping(value = "/find")
public List find(int page, int size) {
List list=null;
long start = (page - 1) * size;
long end = start + size - 1;
try {
//采用redis list数据结构的lrange命令实现分页查询
list = this.redisTemplate.opsForList().range(Constants.JHS_KEY, start, end);
if (CollectionUtils.isEmpty(list)) {
//TODO 走DB查询
}
log.info("查询结果:{}", list);
} catch (Exception ex) {
//这里的异常,一般是redis瘫痪 ,或 redis网络timeout
log.error("exception:", ex);
//TODO 走DB查询
}
return list;
}
```
2.解决缓存击穿的问题
什么是缓存击穿?
在高并发的系统中,大量的请求同时查询一个key时,如果这个key正好失效或删除,就会导致大量的请求都打到数据库上面去。这种现象我们称为缓存击穿。
当查询QPS=1000的时候,这时定时任务更新redis,先删除再添加就会出现缓存击穿,就会导致大量的请求都打到数据库上面去。
如何解决缓存击穿的问题?
针对这种定时更新缓存的特定场景,解决缓存击穿一般是采用主从轮询的原理。
- 定时器更新原理
开辟2块缓存,A 和 B,定时器在更新缓存的时候,先更新B缓存,然后再更新A缓存,记得要按这个顺序。

- 查询原理
用户先查询缓存A,如果缓存A查询不到(例如,更新缓存的时候删除了),再查下缓存B
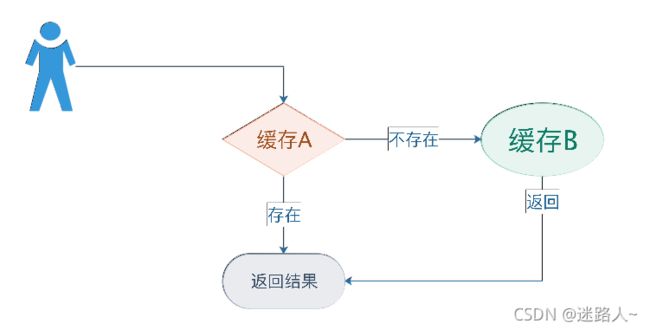
以上2个步骤,由原来的一块缓存,开辟出2块缓存,最终解决了缓存击穿的问题
淘宝聚划算的缓存击穿实现
```
@PostConstruct
public void initJHSAB(){
log.info("启动AB定时器..........");
new Thread(()->runJhsAB()).start();
}
```
```
public void runJhsAB() {
while (true){
//模拟从数据库读取100件 特价商品,用于加载到聚划算页面
List list=this.products();
//先更新B
this.redisTemplate.delete(Constants.JHS_KEY_B);
this.redisTemplate.opsForList().leftPushAll(Constants.JHS_KEY_B,list);
//再更新A
this.redisTemplate.delete(Constants.JHS_KEY_A);
this.redisTemplate.opsForList().leftPushAll(Constants.JHS_KEY_A,list);
try {
Thread.sleep(1000*60);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("重新刷新..............");
}
}
```
```
@GetMapping(value = "/findAB")
public List findAB(int page, int size) {
List list=null;
long start = (page - 1) * size;
long end = start + size - 1;
try {
//采用redis,list数据结构的lrange命令实现分页查询。
list = this.redisTemplate.opsForList().range(Constants.JHS_KEY_A, start, end);
//用户先查询缓存A,如果缓存A查询不到(例如,更新缓存的时候删除了),再查下缓存B
if (CollectionUtils.isEmpty(list)) {
this.redisTemplate.opsForList().range(Constants.JHS_KEY_B, start, end);
}
log.info("{}", list);
} catch (Exception ex) {
//这里的异常,一般是redis瘫痪 ,或 redis网络timeout
log.error("exception:", ex);
//TODO 走DB查询
}
return list;
}
``` 3.微信抢红包的技术实现原理
### 一、微信抢红包的并发场景分析
关于微信抢红包,每个人应该都用过,我们今天就来聊聊这个抢红包的技术实现。
像微信抢红包的高峰期一般是在年底公司开年会和春节2个时间段,高峰的并发量是在几千万以上。
高峰的抢红包有3大特点:
1. 包红包的人多:也就是创建红包的任务比较多,即红包系统是以单个红包的任务来区分,特点就是在高峰期红包任务多。
2. 抢红包的人更多:当你发红包出去后,是几十甚至几百人来抢你的红包,即单红包的请求并发量大。
3. 抢红包体验:当你发现红包时,要越快抢到越开心,所以要求抢红包的响应速度要快,一般1秒响应。
### 一、微信抢红包的技术实现原理
- 包红包
1.先把金额拆解为小金额的红包,例如 总金额100元,发20个,用户在点保存的时候,就自动拆解为20个随机小红包。
2.这里的存储就是个难题,多个金额(例如20个小金额的红包)如何存储?采用set? list? hash?
- 抢红包
高并发的抢红包时核心的关键技术,就是控制各个小红包的原子性。
例如 20个红包在500人的群里被抢,20个红包被抢走一个的同时要不红包的库存减1,即剩下19个。
在整个过程中抢走一个 和 红包库存减1个 是一个原子操作。
那数据类型符合 "抢走一个 和 红包库存减1个 是一个原子操作" 采用set? list? hash?
list比较适合?????
list的pop操作弹出一个元素的同时会自动从队列里面剔除该元素,它是一个原子性操作。
### 二、案例实战:SpringBoot+Redis实现微信抢红包
@RestController
@Slf4j
@RequestMapping(value = "/red")
public class RedpacketController {
@Autowired
private RedisTemplate redisTemplate;
static final String RED_PACKET_CONSUME_KEY="redpacket:consume:";
static final String RED_PACKET_KEY="redpacket:";
static final String ID_KEY = "id:generator:redpacket";
/**
* 抢红包接口
*/
@GetMapping(value = "/rob")
public int rob(long redid,long userid) {
//第一步:验证该用户是否抢过
Object packet=this.redisTemplate.opsForHash().get(RED_PACKET_CONSUME_KEY+redid,String.valueOf(userid));
if(packet==null){
//第二步:从list队列,弹出一个红包
Object obj=this.redisTemplate.opsForList().leftPop(RED_PACKET_KEY+redid);
if(obj!=null){
//第三步:抢到红包存起来
this.redisTemplate.opsForHash().put(RED_PACKET_CONSUME_KEY+redid,String.valueOf(userid),obj);
log.info("用户={}抢到{}",userid,obj);
//TODO 异步把数据落地到数据库上
return (Integer) obj;
}
//-1 代表抢完
return -1;
}
//-2 该用户代表已抢
return -2;
}
/**
* 包红包的接口
*/
@GetMapping(value = "/set")
public long setRedpacket(int total, int count) {
//拆解红包
Integer[] packet= this.splitRedPacket(total,count);
//为红包生成全局唯一id
long n=this.incrementId();
//采用list存储红包
String key=RED_PACKET_KEY+n;
this.redisTemplate.opsForList().leftPushAll(key,packet);
//设置3天过期
this.redisTemplate.expire(key,3, TimeUnit.DAYS);
log.info("拆解红包{}={}",key,packet);
return n;
}
/**
* 生成全局唯一id
* @return
*/
public Long incrementId() {
long n=this.redisTemplate.opsForValue().increment(ID_KEY);
return n;
}
/**
* 拆解红包
* 1.红包金额要被全部拆解完
* 2.红包金额不能差太离谱
*/
public Integer[] splitRedPacket(int total, int count) {
int use = 0;
Integer[] array = new Integer[count];
Random random = new Random();
for (int i = 0; i < count; i++) {
if (i == count - 1)
array[i] = total - use;
else {
// 2 红包随机金额浮动系数
int avg = (total - use) * 2 / (count - i);
array[i] = 1 + random.nextInt(avg - 1);
}
use = use + array[i];
}
return array;
}
}
4.高并发微信文章PV




为什么需要二级缓存?
答:因为一级缓存是jvm内存,
##### 步骤1:模拟大量PV请求
public class InitPVTask {
@Autowired
private RedisTemplate redisTemplate;
@PostConstruct
public void initPV(){
log.info("启动模拟大量PV请求 定时器..........");
new Thread(()->runArticlePV()).start();
}
/**
* 模拟大量PV请求
*/
public void runArticlePV() {
while (true){
this.batchAddArticle();
try {
//5秒执行一次
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
/**
* 对1000篇文章,进行模拟请求PV
*/
public void batchAddArticle() {
for (int i = 0; i < 1000; i++) {
this.addPV(new Integer(i));
}
}
/**
*那如何切割时间块呢? 如何把当前的时间切入时间块中?
* 例如,我们要计算“小时块”,先把当前的时间转换为为毫秒的时间戳,然后除以一个小时,
* 即当前时间T/1000*60*60=小时key,然后用这个小时序号作为key。
* 例如:
* 2020-01-12 15:30:00=1578814200000毫秒 转换小时key=1578814200000/1000*60*60=438560
* 2020-01-12 15:59:00=1578815940000毫秒 转换小时key=1578815940000/1000*60*60=438560
* 2020-01-12 16:30:00=1578817800000毫秒 转换小时key=1578817800000/1000*60*60=438561
* 剩下的以此类推
*
* 每一次PV操作时,先计算当前时间是那个时间块,然后存储Map中。
*/
public void addPV(Integer id) {
//生成环境:时间块为5分钟
//long m5=System.currentTimeMillis()/(1000*60*5);
//为了方便测试 改为1分钟 时间块
long m1=System.currentTimeMillis()/(1000*60*1);
Map mMap=Constants.PV_MAP.get(m1);
if (CollectionUtils.isEmpty(mMap)){
mMap=new ConcurrentHashMap();
mMap.put(id,new Integer(1));
//<1分钟的时间块,Map<文章Id,访问量>>
Constants.PV_MAP.put(m1, mMap);
}else {
//通过文章id 取出浏览量
Integer value=mMap.get(id);
if (value==null){
mMap.put(id,new Integer(1));
}else{
mMap.put(id,value+1);
}
}
}
}
##### 步骤2:一级缓存定时器消费
```
public class OneCacheTask {
@Autowired
private RedisTemplate redisTemplate;
@PostConstruct
public void cacheTask(){
log.info("启动定时器:一级缓存消费..........");
new Thread(()->runCache()).start();
}
/**
* 一级缓存定时器消费
* 定时器,定时(5分钟)从jvm的map把时间块的阅读pv取出来,
* 然后push到reids的list数据结构中,list的存储的书为Map<文章id,访问量PV>即每个时间块的pv数据
*/
public void runCache() {
while (true){
this.consumePV();
try {
//间隔1.5分钟 执行一遍
Thread.sleep(90000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("消费一级缓存,定时刷新..............");
}
}
public void consumePV(){
//为了方便测试 改为1分钟 时间块
long m1=System.currentTimeMillis()/(1000*60*1);
Iterator iterator= Constants.PV_MAP.keySet().iterator();
while (iterator.hasNext()){
//取出map的时间块
Long key=iterator.next();
//小于当前的分钟时间块key ,就消费
if (key map=Constants.PV_MAP.get(key);
//push到reids的list数据结构中,list的存储的书为Map<文章id,访问量PV>即每个时间块的pv数据
this.redisTemplate.opsForList().leftPush(Constants.CACHE_PV_LIST,map);
//后remove
Constants.PV_MAP.remove(key);
log.info("push进{}",map);
}
}
}
}
```
##### 步骤3:二级缓存定时器消费
```
public class TwoCacheTask {
@Autowired
private RedisTemplate redisTemplate;
@PostConstruct
public void cacheTask(){
log.info("启动定时器:二级缓存消费..........");
new Thread(()->runCache()).start();
}
/**
* 二级缓存定时器消费
* 定时器,定时(6分钟),从redis的list数据结构pop弹出Map<文章id,访问量PV>,弹出来做了2件事:
* 第一件事:先把Map<文章id,访问量PV>,保存到数据库
* 第二件事:再把Map<文章id,访问量PV>,同步到redis缓存的计数器incr。
*/
public void runCache() {
while (true){
while (this.pop()){
}
try {
//间隔2分钟 执行一遍
Thread.sleep(1000*60*2);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("消费二级缓存,定时刷新..............");
}
}
public boolean pop(){
//从redis的list数据结构pop弹出Map<文章id,访问量PV>
ListOperations> operations= this.redisTemplate.opsForList();
Map map= operations.rightPop(Constants.CACHE_PV_LIST);
log.info("弹出pop={}",map);
if (CollectionUtils.isEmpty(map)){
return false;
}
// 第一步:先存入数据库
// TODO: 插入数据库
//第二步:同步redis缓存
for (Map.Entry entry:map.entrySet()){
// log.info("key={},value={}",entry.getKey(),entry.getValue());
String key=Constants.CACHE_ARTICLE+entry.getKey();
//调用redis的increment命令
long n=this.redisTemplate.opsForValue().increment(key,entry.getValue());
// log.info("key={},pv={}",key, n);
}
return true;
}
}
```
##### 步骤4:查看浏览量
```
@GetMapping(value = "/view")
public String view(Integer id) {
String key= Constants.CACHE_ARTICLE+id;
//调用redis的get命令
String n=this.stringRedisTemplate.opsForValue().get(key);
log.info("key={},阅读量为{}",key, n);
return n;
}
```