超级菜鸟怎么学习数据分析?
如果你有python入门基础,在考虑数据分析岗,这篇文章将带你了解:数据分析人才的薪资水平,数据人应该掌握的技术栈。
首先来看看,我在搜索数据分析招聘时,各大厂开出的薪资:

那各大厂在数据领域,偏好哪些岗位呢?
主要集中在大数据分析师、数据管理专家、大数据算法工程师、数据产品经理这些岗位,在各个大厂的招聘需求中最常见到,而且开出的薪资待遇非常诱人。
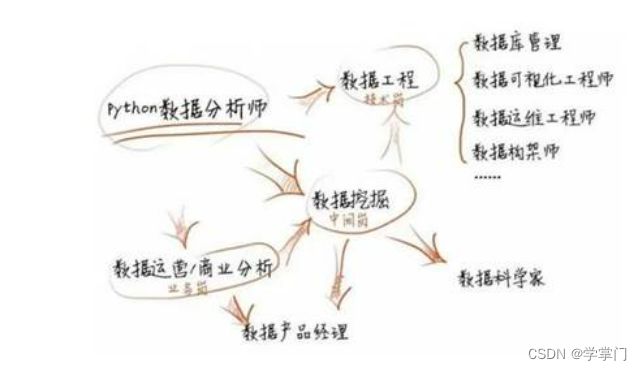
如今大数据工程师人才高度稀缺,在工作年限相同的前提下,大数据工程师的薪资普遍更高,待遇涨幅也高于其他岗位,现在入局大数据,是个不错的选择。
各大互联网公司都在高价抢夺数据人才,为了谋求长期发展、获取高薪,很多人也在考虑转行大数据领域。作为专业性极强的一个领域,转行如何学?学习重点在哪里?
我很早之前就认同一个观点:一个优秀的数据人应该是思维、业务、分析和工程能力的综合体,谈思维、业务等能力很多人可能觉得飘在空中。确实,在我一开始接触数据行业的时候,我也有这样的感觉,为什么那些大佬老是跟我吹产品Sense、业务感等等。
我们就抛开这些,就说工程能力,再具体一点,说说数据人应该掌握的技术栈。
1.关于精通python
虽然入行几年,但我仍不敢说自己精通Pytho。我只是熟悉Python语法,相关的函数、模块和包以及一些面向对象的写法等等。
想要成为合格的数据人,我觉得更重要的是去思考哪些问题可以利用Python扩展而来的一些程序库处理,比如遇到大型矩阵的数值计算问题,你就应该想到Numpy来解决。
同理我会问,那Pandas呢?其实Pandas和SQL几乎是一致的数据处理方式,都只是提供了快速便捷地处理数据的函数和方法,这也是Python为什么会经常会被认为可以高效应用于数据分析原因之一了。
2.再说下数据架构
有些小伙伴应该是了解HiveSQL的,但如果要他说说Hive这类的问题,可能就有困难了,这样其实是学不扎实的表现。
简单来说,Hive是一个基于Hadoop的开源数据仓库工具,用于存(HDFS)和处理(MapReduce)海量结构化数据。使用MapReduce计算,HDFS储存。
虽然很多数据分析岗位不必精通Hadoop、MapReduce、HDFS,但是不代表不需要了解和学习,基础是要打好的,而且Storm、Hbase、Flume、Spark、SparkSQL等等都是需要数据分析、数据挖掘、数据算法等岗位去学习和了解的。
如果你想从事数据开发,那以上提到的技术栈是你应该熟练掌握的。(我个人建议是没有项目经历和工作经验的不要轻易转数据分析,因为真的HC少,可以考虑数据开发,很吃香,工资也高,竞争相对算法和分析来说要小)
3.有必要学点数据挖掘模型
某些业务场景的任务是不能用对比、交叉等分析解决的,例如分类、预测、文本挖掘等。
我之前提到说数据分析一般可以分成定量和定性的分析,定量的大家都比较清楚,也比较常见,但是定性的会去研究用户的主动反馈意见,而这些一般都是文本,当数据量较大的时候,肯定不是一条条自己去分析用户的情感、观点等维度,这时候完全可以利用文本挖掘的方法快速准确的抽取出用户观点、主题和情感分析等等。
看到现在越来越多的人入行/转行互联网,我来说说我对这个领域的理解吧。
从业人员(除了高层)一般年龄在45岁以下,思维活跃、年轻,不像传统行业等级森严,工作起来是比较愉悦的。任何人能入行这个领域,是因为互联网对于没有资源和背景的普通人是很包容的,比如它创造的很多新的工作机会,有些岗位之前是没有的,因此不强求专业对口、要多少年的经验等等,对于没有资历的普通人来说,互联网很友好。
最重要的一点是,互联网行业能和你适合的行业相结合,比如互联网+金融、互联网+餐饮,互联网成为了一种业务模式,贯穿到了很多行业,在此基础上去赚钱。
未来,互联网会越来越渗透到各个行业,未来10年也必定是人工智能、万物互联的时代。这也是我为什么看准python的原因,因为python的优势,就是对数据的处理。如果你也跟我一样看好互联网,看准python,那就利用好现在的时间,有效率的学习。我一直相信,生活会回报每一个为目标努力的人。
文章来源:网络 版权归原作者所有
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系小编,我们将立即处理