Android应用程序中使用 Gemini Pro AI开发——2年工作经验如何淘汰10年工作经验的Android开发?
Android应用程序中使用 Gemini Pro
- 前言(可略过)、使用 Gemini Pro 开发应用程序
- 正文、Android Studio 中构建Gemini API Starter 应用
-
- 第 1 步:在 AI 的新项目模板的基础上进行构建
- 第 2 步:生成 API 密钥
- 第 3 步:开始原型设计
- 正文补充、快速入门:使用 Gemini Pro 开始构建 AI 驱动的功能和 Android 应用。
-
- 设置项目
- 设置您的 API 密钥
- 保护您的 API 密钥
- 将 SDK 依赖项添加到项目中
- 初始化生成模型
- 实现常见用例
-
- 根据纯文本输入生成文本
- 根据文本和图片输入生成文本(多模式)
- 构建多轮对话(聊天)
- 使用流式传输实现更快速的互动
- 实现高级用例
-
- 计算令牌数
- 用于控制内容生成的选项
-
- 配置模型参数
- 使用安全设置
- 后续步骤

上周,谷歌推出了最强大的基础模型Gemini。 Gemini 是多模式的AI——它可以接受文本和图像输入。
谷歌为 Android 开发者引入了一种在设备上,利用最小模型Gemini Nano的方法。此功能可通过 AICore 在部分设备上使用,这是一项处理模型管理、运行时、安全功能等的系统服务,可简化开发人员的工作。
前言(可略过)、使用 Gemini Pro 开发应用程序
Gemini Pro 可通过 Gemini API 访问,它是我们在各种文本和图像推理任务中扩展的最佳模型。为了简化 Gemini Pro 的集成,您可以使用 Google AI SDK(适用于 Android 的客户端 SDK)。该 SDK 支持与 Android 应用直接集成,开发人员无需构建和管理自己的后端基础设施,从而降低了开发成本并提高了速度。
Google AI Studio 为开发者提供了一种简化的方式来集成 Gemini Pro 模型、制作提示、创建 API 密钥以及轻松地将想法转化为 AI 应用。在 Google AI Studio 中开发出提示后,您只需单击“获取代码”操作即可生成 Kotlin 代码片段,并立即开始使用适用于 Android 的 Google AI SDK 集成 Gemini。

我们还让开发者能够更轻松地在Android Studio 最新预览版中直接使用 Gemini API。我们推出了新项目模板,供开发者立即开始使用适用于 Android 的 Google AI SDK。您将受益于 Android Studio 增强的代码完成和 lint 检查器,有助于 API 密钥和安全性。

要利用 Android Studio 中的新模板,请通过 File > 启动一个新项目新的>新建项目并选择 Gemini API 入门模板。该模板提供了一个预配置的项目,其中包含使用 Gemini API 所需的代码。选择项目名称和位置后,系统会提示您在 Google AI Studio 中生成 API 密钥,并要求您在 Android Studio 中输入该密钥。 Android Studio 将通过 Gemini API 连接自动为您设置项目,从而简化您的工作流程。
或者,您可以导入生成式 AI 代码示例并通过 在 Android Studio 中进行设置文件>新的>导入示例,然后搜索“Generative AI Sample”。

至此,一个简单的示例就搭建完毕了。接下来是详细的Android Studio中的操作步骤。
正文、Android Studio 中构建Gemini API Starter 应用
本文档简要介绍了如何使用 Android Studio 构建使用 Google AI SDK 实现生成式 AI 的应用。该流程分为三个步骤。在开始之前,请确保您运行的是最新的预览版 Android Studio。
第 1 步:在 AI 的新项目模板的基础上进行构建
启动 Android Studio,然后依次选择 File > New Project 以打开一个新项目。选择新的 Gemini API 入门模板。

第 2 步:生成 API 密钥
在向导的下一步中,选择项目名称和位置后,请提供用于向 Gemini API 进行身份验证的 API 密钥。如果您没有 Gemini API 密钥,请点击向导中提供的链接转到 Google AI Studio 并请求新密钥。完成后,将新的 API 密钥复制回向导。 点击 Finish。

第 3 步:开始原型设计
Android Studio 会自动为您设置一个连接到 Gemini API 的项目,从而简化您的工作流程。点击 Run 即可在 Android 模拟器中查看代码的实际运行情况。 该应用附带一条硬编码提示,要求模型“为我总结以下文本”。您可以直接在代码中修改或展开提示,以修改其功能。
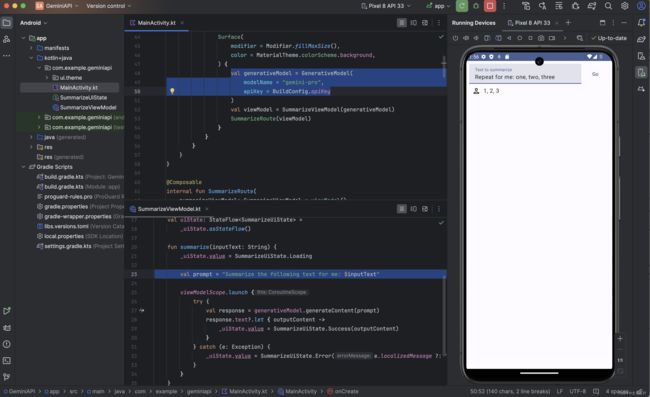
如需详细了解如何创建提示,请参阅 下面的快速入门模块中的:实现常见用例等。
正文补充、快速入门:使用 Gemini Pro 开始构建 AI 驱动的功能和 Android 应用。
设置项目
在调用 Gemini API 之前,您需要设置 Android 项目,其中包括设置 API 密钥、将 SDK 依赖项添加到 Android 项目,以及初始化模型。
设置您的 API 密钥
您需要 API 密钥才能使用 Gemini API。如果您还没有密钥,请在 Google AI Studio 中创建一个。
保护您的 API 密钥
强烈建议您不要将 API 密钥签入版本控制系统。您应将其存储在 local.properties 文件中(该文件位于项目的根目录中,但不在版本控制范围内),然后使用 Android 版 Secrets Gradle 插件以 build 配置变量的形式读取 API 密钥。
// Access your API key as a Build Configuration variable
val apiKey = BuildConfig.apiKey
本快速入门中的所有代码段均采用此最佳实践。此外,如果您想查看 Secrets Gradle 插件的实现,可以查看此 SDK 的示例应用,或者使用 Android Studio Iguana 的最新预览版,它具有 Gemini API Starter 模板(包含 local.properties 文件,旨在帮助您开始使用)
将 SDK 依赖项添加到项目中
1、在您的模块(应用级)Gradle 配置文件(如 //build.gradle.kts)中,添加 Google AI SDK for Android 的依赖项:
dependencies {
// ... other androidx dependencies
// add the dependency for the Google AI client SDK for Android
implementation("com.google.ai.client.generativeai:generativeai:0.1.1")
}
2、将您的 Android 项目与 Gradle 文件同步。
初始化生成模型
在进行任何 API 调用之前,您需要先初始化 GenerativeModel 对象:
val generativeModel = GenerativeModel(
// Use a model that's applicable for your use case (see "Implement basic use cases" below)
modelName = "MODEL_NAME",
// Access your API key as a Build Configuration variable (see "Set up your API key" above)
apiKey = BuildConfig.apiKey
)
指定模型时,请注意以下事项:
您需要使用特定于您的用例的模型(例如,gemini-pro-vision 适用于多模态输入);如需了解每个用例的推荐模型,请参阅本指南的下一部分。
实现常见用例
现在您的项目已设置完毕,您可以探索如何使用 Gemini API 来实现不同的用例:
- 根据纯文本输入生成文本
- 从文本和图片输入生成文本(多模式)
- 构建多轮对话(聊天)
- 使用流式传输加快互动速度
根据纯文本输入生成文本
当提示输入仅包含文本时,请将 gemini-pro 模型与 generateContent 结合使用以生成文本输出:
请注意,generateContent() 是一个挂起函数,需要从协程作用域中调用。如果您不熟悉协程,请参阅 Android 上的 Kotlin 协程。
kotlin
val generativeModel = GenerativeModel(
// For text-only input, use the gemini-pro model
modelName = "gemini-pro",
// Access your API key as a Build Configuration variable (see "Set up your API key" above)
apiKey = BuildConfig.apiKey
)
val prompt = "Write a story about a magic backpack."
val response = generativeModel.generateContent(prompt)
print(response.text)
根据文本和图片输入生成文本(多模式)
Gemini 提供了一个多模态模型 (gemini-pro-vision),因此您可以同时输入文本和图片。请务必查看提示的图片要求。
当提示输入同时包含文本和图片时,请将 gemini-pro-vision 模型与 generateContent 结合使用以生成文本输出:
val generativeModel = GenerativeModel(
// For text-and-images input (multimodal), use the gemini-pro-vision model
modelName = "gemini-pro-vision",
// Access your API key as a Build Configuration variable (see "Set up your API key" above)
apiKey = BuildConfig.apiKey
)
val image1: Bitmap = // ...
val image2: Bitmap = // ...
val inputContent = content {
image(image1)
image(image2)
text("What's different between these pictures?")
}
val response = generativeModel.generateContent(inputContent)
print(response.text)
构建多轮对话(聊天)
借助 Gemini,您可以构建多轮自由对话。该 SDK 通过管理对话状态简化了流程,因此与 generateContent 不同,您无需自行存储对话历史记录。
如需构建多轮对话(如聊天),请使用 gemini-pro 模型,并通过调用 startChat() 来初始化聊天。然后,使用 sendMessage() 发送一条新用户消息,此消息还会将该消息和响应附加到聊天记录中。
与对话内容关联的 role 有两个可能的选项:
user:提供提示的角色。这是 sendMessage 调用的默认值。
model:提供响应的角色。在使用现有 history 调用 startChat() 时,可以使用此角色。
注意 :gemini-pro-vision 模型(适用于文本和图片输入)尚未针对多轮对话进行优化。请务必针对聊天用例使用 gemini-pro 和纯文字输入。
val generativeModel = GenerativeModel(
// For text-only input, use the gemini-pro model
modelName = "gemini-pro",
// Access your API key as a Build Configuration variable (see "Set up your API key" above)
apiKey = BuildConfig.apiKey
)
val chat = generativeModel.startChat(
history = listOf(
content(role = "user") { text("Hello, I have 2 dogs in my house.") },
content(role = "model") { text("Great to meet you. What would you like to know?") }
)
)
chat.sendMessage("How many paws are in my house?")
使用流式传输实现更快速的互动
默认情况下,模型会在完成整个生成过程后返回响应。通过不等待整个结果,而是使用流式传输来处理部分结果,您可以实现更快的互动。
以下示例展示了如何使用 generateContentStream 实现流式传输,以根据文本和图像输入提示生成文本。
val generativeModel = GenerativeModel(
// For text-and-image input (multimodal), use the gemini-pro-vision model
modelName = "gemini-pro-vision",
// Access your API key as a Build Configuration variable (see "Set up your API key" above)
apiKey = BuildConfig.apiKey
)
val image1: Bitmap = // ...
val image2: Bitmap = // ...
val inputContent = content {
image(image1)
image(image2)
text("What's the difference between these pictures?")
}
var fullResponse = ""
generativeModel.generateContentStream(inputContent).collect { chunk ->
print(chunk.text)
fullResponse += chunk.text
}
您可以在纯文本输入和聊天用例中使用类似方法:
// Use streaming with text-only input
generativeModel.generateContentStream(inputContent).collect { chunk ->
print(chunk.text)
}
// Use streaming with multi-turn conversations (like chat)
val chat = generativeModel.startChat()
chat.sendMessageStream(inputContent).collect { chunk ->
print(chunk.text)
}
实现高级用例
本快速入门的上一部分中介绍的常见用例可帮助您熟悉 Gemini API。本部分介绍了一些可能被视为更高级的用例。
计算令牌数
使用长提示时,在向模型发送任何内容之前统计令牌数可能很有用。以下示例展示了如何针对各种用例使用 countTokens():
// For text-only input
val (totalTokens) = generativeModel.countTokens("Write a story about a magic backpack.")
// For text-and-image input (multi-modal)
val multiModalContent = content {
image(image1)
image(image2)
text("What's the difference between these pictures?")
}
val (totalTokens) = generativeModel.countTokens(multiModalContent)
// For multi-turn conversations (like chat)
val history = chat.history
val messageContent = content { text("This is the message I intend to send")}
val (totalTokens) = generativeModel.countTokens(*history.toTypedArray(), messageContent)
用于控制内容生成的选项
您可以通过配置模型参数和使用安全设置来控制内容生成。、
配置模型参数
您发送到模型的每个提示都包含用于控制模型如何生成回答的参数值。对于不同的参数值,模型会生成不同的结果。详细了解模型参数。
val config = generationConfig {
temperature = 0.9f
topK = 16
topP = 0.1f
maxOutputTokens = 200
stopSequences = listOf("red")
}
val generativeModel = GenerativeModel(
modelName = "MODEL_NAME",
apiKey = BuildConfig.apiKey,
generationConfig = config
)
使用安全设置
您可以使用安全设置来调整收到可能被视为有害的响应的可能性。默认情况下,安全设置会在所有维度上屏蔽概率中等和/或高可能属于不安全内容的内容。详细了解安全设置。
下面是设置一项安全设置的具体方法:
val generativeModel = GenerativeModel(
modelName = "MODEL_NAME",
apiKey = BuildConfig.apiKey,
safetySettings = listOf(
SafetySetting(HarmCategory.HARASSMENT, BlockThreshold.ONLY_HIGH)
)
)
您还可以设定多个安全设置:
val harassmentSafety = SafetySetting(HarmCategory.HARASSMENT, BlockThreshold.ONLY_HIGH)
val hateSpeechSafety = SafetySetting(HarmCategory.HATE_SPEECH, BlockThreshold.MEDIUM_AND_ABOVE)
val generativeModel = GenerativeModel(
modelName = "MODEL_NAME",
apiKey = BuildConfig.apiKey,
safetySettings = listOf(harassmentSafety, hateSpeechSafety)
)
后续步骤
提示设计是创建提示以从语言模型引出所需回复的过程。编写结构合理的提示对于确保语言模型提供准确、高质量的响应至关重要。了解提示撰写的最佳做法。
Gemini 提供了多种模型变体,以满足不同用例的需求,例如输入类型和复杂度、聊天或其他对话框语言任务的实现,以及大小限制。了解可用的 Gemini 模型。
Gemini 提供用于请求提高速率限制的选项。Genmini Pro 模型的速率限制为每分钟 60 个请求 (RPM)。
借助本快速入门中介绍的适用于 Android 的客户端 SDK,您可以访问在 Google 服务器上运行的 Genmini Pro 模型。对于涉及处理敏感数据、实现离线可用性的用例,或者需要为常用用户流节省费用,您可能需要考虑访问在设备上运行的 Gemini Nano。如需了解详情,请参阅 Android(设备端)快速入门。