基于WEKWS模型的语音唤醒关键词识别
一、模型描述
1.1 论文解读
本文所使用的模型网络结构继承自论文《Compact Feedforward Sequential Memory Networks for Small-footprint Keyword Spotting》,文中研究了将低秩矩阵分解与传统FSMN相结合的紧凑型前馈顺序记忆网络(cFSMN)用于远场关键字检测任务。此外,文中还分析了其结构参数的影响,为了降低计算成本,将多帧预测(MFP)应用到 cFSMN中;为了进一步提高建模能力,尝试在输出层之前插入小 DNN 层,以实现高级 MFP。最后通过检测误差权衡(DET)曲线下面积(AUC)来衡量模型的性能。
论文中并没有使用 HMM 系统而是使用单词作为建模单元,这样就为预先定义的关键词指定了模型。然而,在论文中,除了主关键字外,系统还应具有添加新关键字的灵活性,因此,文中沿用了传统的关键词/背景 HMM 结构,并使用 Senones(绑定的麦克风状态)作为建模单元。解码图由关键词和背景路径组成,每个关键词路径由一个关键词的 HMM 序列组成,添加一个关键词需要在图中添加一个关键词路径。背景路径是为非关键词语音、噪音和静音建立的,解码图中的维特比搜索通过标记传递分别在竞争的关键词路径和背景路径上运行,一旦活动标记到达关键字路径的末端,就会提取假设语段的声音信息。当关键词和背景路径得分的正则化比率超过预设阈值时,系统就会触发。在搜索过程中,每一帧的得分都会由AM预测。AM 的输入是声学特征,输出是关键词和背景模型的 HMM 状态的后验分布。没有使用语言模型。[1]

图1 cFSMN示意图
论文中研究了将低秩矩阵分解与传统FSMN相结合的紧凑型前馈顺序记忆网络(cFSMN)用于远场关键字检测任务。其主体为4层cFSMN结构,如下图所示,参数量约750K,适用于移动端设备运行。
论文中实验表明,与需要相同延迟和两倍计算成本的经过良好调谐的长短期记忆(LSTM)相比,cFSMN 在安静和嘈杂环境下记录的测试集上分别实现了 18.11% 和 29.21% 的 AUC 相对下降。应用高级 MFP 后,系统在安静和嘈杂测试集上的 AUC 相对于传统 cFSMN 分别降低了 0.48% 和 20.04%,而计算成本则相对降低了 46.58%。
1.2 模型详解
本文模型采用达摩院语音唤醒预训练模型,模型输入采用Fbank特征,训练阶段使用CTC-loss计算损失并更新参数,输出为基于char建模的中文全集token预测,token数共2599个。测试工具根据每一帧的预测数据进行后处理得到输入音频的实时检测结果。
模型训练采用"basetrain + finetune"的模式,basetrain过程使用大量内部移动端数据,在此基础上,使用1万条设备端录制安静场景“小云小云”数据进行微调,得到最终面向业务的模型。由于采用了中文char全量token建模,并使用充分数据进行basetrain,本模型支持基本的唤醒词/命令词自定义功能,但具体性能无法评估。
目前最新ModelScope版本已支持用户在basetrain模型基础上,使用其他关键词数据进行微调,得到新的语音唤醒模型。
二、WEKWS[2]模型基础
2.1 本地环境配置
环境要求相关包的版本如下:
pyyaml>=5.1
tensorboard
tensorboardX
matplotlib
onnxruntime
flake8==3.8.2
flake8-bugbear
flake8-comprehensions
flake8-executable
flake8-pyi==20.5.0
mccabe
pycodestyle==2.6.0
pyflakes==2.2.0
lmdb
scipy
tqdm
2.2 项目目录
执行项目之前要重新从github仓库下载新的可执行文件,防止出现在运行过程中与上次运行产生的文件发生冲突问题,项目运行前目录为图2所示。

图2 wekws训练前目录
我们需要先根据上述2.1所述,对相关的依赖包进行安装,防止因未安装包,导致后期训练过于繁琐,conf是模型的参数文件,然后运行path.sh脚本,将环境变量写入当前系统,最后运行run.sh对模型进行训练,训练完成后,我们将得到如下图3目录。

图3 wekws训练后目录
训练将会持续一百轮,一轮将会训练510次,每隔10次打印一次模型结果,每隔一轮再打印一次结果。最终得到每轮的运行日志保存在exp目录下,data文件是训练集文件。
2.3 脚本说明
脚本关键部分和功能的摘要如下:
2.3.1 下载和数据准备:
下载和提取数据集local/data_download.sh
[ -f ./path.sh ] && . ./path.sh
dl_dir=./data/local
. tools/parse_options.sh || exit 1;
data_dir=$dl_dir
file_name=speech_commands_v0.01.tar.gz
speech_command_dir=$data_dir/speech_commands_v1
audio_dir=$data_dir/speech_commands_v1/audio
url=http://download.tensorflow.org/data/$file_name
mkdir -p $data_dir
if [ ! -f $data_dir/$file_name ]; then
echo "downloading $url..."
wget -O $data_dir/$file_name $url
else
echo "$file_name exist in $data_dir, skip download it"
fi
if [ ! -f $speech_command_dir/.extracted ]; then
mkdir -p $audio_dir
tar -xzvf $data_dir/$file_name -C $audio_dir
touch $speech_command_dir/.extracted
else
echo "$speech_command_dir/.exatracted exist in $speech_command_dir, skip exatraction"
fi
exit 0拆分数据集local/split_dataset.py
我们定义了一个名为move_files的函数,用于将指定文件夹中的文件根据给定的文件列表移动到目标文件夹中。首先打开给定的文件列表,并逐行读取文件路径,然后,通过使用os.path.dirname函数获取每个文件路径的目录,并使用os.path.join函数将目录与目标文件夹合并得到目标文件夹的路径。如果目标文件夹不存在,则使用os.mkdir函数创建目标文件夹。最后,使用shutil.move函数将源文件夹中的文件移动到目标文件夹中。在源代码的最后,还通过argparse模块解析命令行参数,并使用move_files函数将音频文件夹中的文件移动到测试文件夹和验证文件夹中,并将音频文件夹重命名为训练文件夹。
def move_files(src_folder, to_folder, list_file):
with open(list_file) as f:
for line in f.readlines():
line = line.rstrip()
dirname = os.path.dirname(line)
dest = os.path.join(to_folder, dirname)
if not os.path.exists(dest):
os.mkdir(dest)
shutil.move(os.path.join(src_folder, line), dest)
if __name__ == '__main__':
'''Splits the google speech commands into train, validation and test set'''
parser = argparse.ArgumentParser(
description='Split google command dataset.')
parser.add_argument(
'root',
type=str,
help='the path to the root folder of the google commands dataset')
args = parser.parse_args()
audio_folder = os.path.join(args.root, 'audio')
validation_path = os.path.join(audio_folder, 'validation_list.txt')
test_path = os.path.join(audio_folder, 'testing_list.txt')
valid_folder = os.path.join(args.root, 'valid')
test_folder = os.path.join(args.root, 'test')
train_folder = os.path.join(args.root, 'train')
os.mkdir(valid_folder)
os.mkdir(test_folder)
move_files(audio_folder, test_folder, test_path)
move_files(audio_folder, valid_folder, validation_path)
os.rename(audio_folder, train_folder)
2.3.2 Kaldi 格式文件准备:
准备用于训练、测试和验证集的 Kaldi 格式文件准备Kaldi格式文件,包括创建目录、生成wav.scp和utt2spk文本文件,wav.scputt2spktext用于计算 CMVN 并格式化数据集:
if [ ${stage} -le -1 ] && [ ${stop_stage} -ge -1 ]; then
echo "Download and extract all datasets"
local/data_download.sh --dl_dir $download_dir
python local/split_dataset.py $download_dir/speech_commands_v1
fi
if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; then
echo "Start preparing Kaldi format files"
for x in train test valid;
do
data=data/$x
mkdir -p $data
# make wav.scp utt2spk text file
find $speech_command_dir/$x -name *.wav | grep -v "_background_noise_" > $data/wav.list
python local/prepare_speech_command.py --wav_list=$data/wav.list --data_dir=$data
done
fi
2.3.3 计算CMVN
如果stage小于等于1且stop_stage大于等于1,则执行计算CMVN和格式化数据集的脚本。该脚本使用compute_cmvn_stats.py计算训练数据集的CMVN统计信息,并将结果保存在data/train/global_cmvn中。然后,脚本使用tools/wav_to_duration.sh将数据集的音频文件转换为持续时间,并使用tools/make_list.py生成数据列表。
if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
echo "Compute CMVN and Format datasets"
tools/compute_cmvn_stats.py --num_workers 16 --train_config $config \
--in_scp data/train/wav.scp \
--out_cmvn data/train/global_cmvn
for x in train valid test; do
tools/wav_to_duration.sh --nj 8 data/$x/wav.scp data/$x/wav.dur
tools/make_list.py data/$x/wav.scp data/$x/text \
data/$x/wav.dur data/$x/data.list
done
fi
2.3.4 训练关键字检测模型
使用torchrun执行wekws/bin/train.py脚本,传递以下参数: --gpus $gpus:使用哪些GPU进行训练 --config $config:配置文件的路径 --train_data data/train/data.list:训练数据的路径 --cv_data data/valid/data.list:验证数据的路径 --model_dir $dir:模型保存的目录 --num_workers 8:用于训练的数据并行性 --num_keywords $num_keywords:关键词的数量--min_duration 50:音频文件的最小持续时间(单位:毫秒) $cmvn_opts:包含CMVN选项的字符串 ${checkpoint:+--checkpoint $checkpoint}:可选的检查点路径参数 最终结果是开始训练。
if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then
echo "Start training ..."
mkdir -p $dir
cmvn_opts=
$norm_mean && cmvn_opts="--cmvn_file data/train/global_cmvn"
$norm_var && cmvn_opts="$cmvn_opts --norm_var"
num_gpus=$(echo $gpus | awk -F ',' '{print NF}')
torchrun --standalone --nnodes=1 --nproc_per_node=$num_gpus \
wekws/bin/train.py --gpus $gpus \
--config $config \
--train_data data/train/data.list \
--cv_data data/valid/data.list \
--model_dir $dir \
--num_workers 8 \
--num_keywords $num_keywords \
--min_duration 50 \
$cmvn_opts \
${checkpoint:+--checkpoint $checkpoint}
fi
2.3.5 模型评估
调用average_model.py脚本将得分检查点、目录和平均数作为参数传递给它,并指定使用val_best作为源路径。然后,创建结果目录,调用compute_accuracy.py脚本进行测试。
if [ ${stage} -le 3 ] && [ ${stop_stage} -ge 3 ]; then
# Do model average
python wekws/bin/average_model.py \
--dst_model $score_checkpoint \
--src_path $dir \
--num ${num_average} \
--val_best
# Testing
result_dir=$dir/test_$(basename $score_checkpoint)
mkdir -p $result_dir
python wekws/bin/compute_accuracy.py --gpu 3 \
--config $dir/config.yaml \
--test_data data/test/data.list \
--batch_size 256 \
--num_workers 8 \
--checkpoint $score_checkpoint
fi2.3.6 模型保存
执行以下操作:将score_checkpoint的后缀从".pt"替换为".zip",并将结果赋给jit_model变量;将score_checkpoint的后缀从".pt"替换为".onnx",并将结果赋给onnx_model变量。然后,调用export_jit.py脚本,传递相应的参数,将结果保存在dir/$jit_model文件中。接着,调用export_onnx.py脚本,传递相应的参数,将结果保存在dir/$onnx_model文件中。
if [ ${stage} -le 4 ] && [ ${stop_stage} -ge 4 ]; then
jit_model=$(basename $score_checkpoint | sed -e 's:.pt$:.zip:g')
onnx_model=$(basename $score_checkpoint | sed -e 's:.pt$:.onnx:g')
python wekws/bin/export_jit.py \
--config $dir/config.yaml \
--checkpoint $score_checkpoint \
--jit_model $dir/$jit_model
python wekws/bin/export_onnx.py \
--config $dir/config.yaml \
--checkpoint $score_checkpoint \
--onnx_model $dir/$onnx_model
fi
2.4 模型评价结果
我们通过绘制准确率和损失率曲线来进一步更加直观的观察模型的训练效果,得到第2轮的训练结果如下。

图4 准确率、损失率曲线
三、服务器环境配置
3.1 使用方式和范围
3.1.1运行环境
现阶段模型只能在Linux-x86_64系统上运行,不支持Mac和Windows系统,模型训练需要用户服务器配置GPU卡,CPU训练暂不支持,本文因本地GPU显存太小,将模型布置在服务器上进行训练。
3.1.2 工具介绍
本文使用附带的kwsbp工具(Linux-x86_64)集进行直接推理,分别测试正样本及负样本集合,综合选取最优工作点。
3.1.3使用范围
移动端设备,Android/iOS型号、版本均不限,使用环境不限,数据集采集音频为16K单通道。
3.2 依赖包安装
依次执行下述命令,在服务器上安装模型的依赖包,配置所需的环境。
!pip install modelscope
!pip install SentencePiece
!pip install --upgrade pip
!sudo apt-get install build-essential
!sudo apt-get install build-essential
!sudo apt-get install libffi-dev
!sudo apt-get install python3-dev
!pip install tokenizers --no-build-isolation
!pip install --upgrade setuptools wheel
!sudo apt-get update
!pip install transformers
!pip install kwsbp -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
!sudo apt-get install kwsbp -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
四、模型测试与演示[3]
4.1 模型推理
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
kwsbp_16k_pipline = pipeline(
task=Tasks.keyword_spotting,
model='damo/speech_charctc_kws_phone-xiaoyun')
kws_result = kwsbp_16k_pipline(audio_in='https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/KWS/pos_testset/kws_xiaoyunxiaoyun.wav')
print(kws_result)
上述代码运行结果如下:
{'kws_type': 'pcm', 'kws_list': [{'keyword': '小云小云', 'offset': 1.89, 'length': 0.51, 'confidence': 0.995018, 'type': 'wakeup'}], 'wav_count': 1}
2023-12-13 07:10:28,218 - modelscope - INFO - PyTorch version 2.1.0+cu118 Found.
2023-12-13 07:10:28,223 - modelscope - INFO - TensorFlow version 2.14.0 Found.
2023-12-13 07:10:28,225 - modelscope - INFO - Loading ast index from /root/.cache/modelscope/ast_indexer
2023-12-13 07:10:28,227 - modelscope - INFO - No valid ast index found from /root/.cache/modelscope/ast_indexer, generating ast index from prebuilt!
2023-12-13 07:10:28,294 - modelscope - INFO - Loading done! Current index file version is 1.10.0, with md5 26bcfc6fb89b2a0a03e3bb75a9f00e95 and a total number of 946 components indexed
2023-12-13 07:10:36,186 - modelscope - WARNING - Model revision not specified, use revision: v1.1.3
Downloading: 100%|██████████| 172k/172k [00:00<00:00, 906kB/s]
Downloading: 100%|██████████| 175k/175k [00:00<00:00, 903kB/s]
…
为了解释上述输出内容,对各参数的描述如下表:
| 参数 |
描述 |
数值 |
| kws_type |
录音格式 |
pcm |
| kws_list |
关键词列表 |
{…} |
| keyword |
关键词 |
小云小云 |
| offset |
偏移量 |
1.89 |
| length |
长度 |
0.51 |
| confidence |
置信度 |
0.995018 |
| type |
录音类型 |
wakeup |
| wav_count |
音频数量 |
1 |
表1 各参数描述表
从上述得到的结果我们可以看到,关键词“小云小云”的置信度为0.995018,表示该识别结果非常可靠。
4.2 模型分词能力测试
为了测试此预训练模型的分词能力,我们使用下述语句“今天天气不错,适合出去游玩”对模型进行测试,测试代码如下:
from modelscope.pipelines import pipeline
word_segmentation = pipeline('word-segmentation',model='damo/nlp_structbert_word-segmentation_chinese-base')
word_segmentation('今天天气不错,适合出去游玩')
输出结果如下:
{'output': ['今天', '天气', '不错', ',', '适合', '出去', '游玩']}
根据上述分词结果,可以看出模型的分词能力比较准确,能够正确地将输入的文本分成一个个的词语,接下来本文将对预训练模型进行训练。
五、模型训练
5.1 训练环境配置
首先根据环境安装文档,新建conda环境并安装Python、深度学习框架以及modelscope语音领域依赖包:
$ conda create -n modelscope python=3.7
$ conda activate modelscope
$ pip install torch torchvision torchaudio
$ pip install "modelscope[audio]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
$ pip install tensorboardX
!pip install kaldiio
!pip install modelscope
5.2 加载数据集
5.1.2 kaldi列表
kaldi列表如下所示:
(1)音频列表为“索引+路径”,中间以Tab分隔。
(2)标注列表为“索引+标注”,中间以Tab分隔,标注是否分词均可。
应注意音频数据集要求采集音频为16K单通道,
音频与标注的索引顺序无关联,但集合应当一致,训练时会自动丢弃无法同时索引到路径和标注的数据,各个文件内容如下所示。
|--example_kws
|---wav # 存放.wav格式音频数据集的文件夹
|---cv_wav.scp # 存储测试集音频文件路径和标签的文本文件
|---merge_trans.txt # 存储音频文件的文本转录结果的文本文件
|---merge_wav.scp # 存储待合并音频文件路径的文本文件
|---test_wav.scp # 存储测试集音频文件路径的文本文件
|---train_wav.scp # 存储训练集音频文件路径的文本文件
部分脚本文件内容如下:
$ cat wav.scp
kws_pos_example1 /home/admin/data/test/audios/kws_pos_example1.wav
kws_pos_example2 /home/admin/data/test/audios/kws_pos_example2.wav
...
kws_neg_example1 /home/admin/data/test/audios/kws_neg_example1.wav
kws_neg_example2 /home/admin/data/test/audios/kws_neg_example2.wav
...
$ cat trans.txt
kws_pos_example1 小 云 小 云
kws_pos_example2 小 云 小 云
...
kws_neg_example1 帮 我 导航 一下 回 临江 路 一百零八 还要 几个 小时
kws_neg_example2 明天 的 天气 怎么样
...
由于我们的建模方式及算法的局限性,需要中文的训练音频及全内容标注,与训练中文ASR模型应相同。训练数据需包含一定数量对应关键词和非关键词样本,我们建议关键词数据在25小时以上,混合负样本比例在1:2到1:10之间,实际性能与训练数据量、数据质量、场景匹配度、正负样本比例等诸多因素有关,需要具体分析和调整。
5.3 训练流程
1、手动创建一个本地工作目录,然后配置到work_dir,用于保存所有训练过程产生的文件
2、获取小云模型库中的配置文件,包含训练参数信息,模型ID确保为“damo/speech_charctc_kws_phone-xiaoyun”
3、初始化一个近场唤醒训练器,trainer tag为“speech_kws_fsmn_char_ctc_nearfield”
4、配置准备好的训练数据列表(kaldi风格),音频列表分为train/cv,标注合为一个文件,然后启动训练。
5、配置唤醒词,多个请使用英文“,”分隔;配置测试目录和测试数据列表(kaldi风格),然后启动测试,最终在测试目录生成测试结果文件——score.txt
5.4 模型训练
训练代码保存文件,如example_kws.py,通过命令行启动训练:
! PYTHONPATH=. torchrun --standalone --nnodes=1 --nproc_per_node=2 example_kws.py# coding = utf-8
import os
from modelscope.utils.hub import read_config
from modelscope.utils.hub import snapshot_download
from modelscope.metainfo import Trainers
from modelscope.trainers import build_trainer
enable_training = True # 是否启用训练
enable_testing = True # 是否启用测试
enable_training = True # 是否启用训练
enable_testing = True # 是否启用测试
# s1
work_dir = './test_kws_training' # 工作目录
# s2
# 模型ID
model_id = 'damo/speech_charctc_kws_phone-xiaoyun'
# 下载模型快照到的工作目录
model_dir = snapshot_download(model_id)
# 读取模型元数据
configs = read_config(model_id) # 读取配置文件
# 更新一些配置
configs.train.max_epochs = 10 # 训练的最大轮数
configs.preprocessor.batch_conf.batch_size = 256 # 批大小
configs.train.dataloader.workers_per_gpu = 4 # 每个GPU的训练数据加载器的工作进程数
configs.evaluation.dataloader.workers_per_gpu = 4 # 每个GPU的测试数据加载器的工作进程数
# 将配置保存到文件中
config_file = os.path.join(work_dir, 'config.json') # 配置文件路径
configs.dump(config_file) # 将配置保存到文件
# s3
# 构建训练器
kwargs = dict(
model=model_id, # 模型ID
work_dir=work_dir, # 工作目录
cfg_file=config_file, # 配置文件路径
seed=666, # 随机种子
)
trainer = build_trainer(
Trainers.speech_kws_fsmn_char_ctc_nearfield, default_args=kwargs) # 构建训练器
# s4
# 训练数据路径
train_scp = '/content/drive/MyDrive/Colab_Notebooks/ModelScope/example_kws/train_wav.scp'
# 交叉验证数据路径
cv_scp = '/content/drive/MyDrive/Colab_Notebooks/ModelScope/example_kws/cv_wav.scp'
# 测试数据路径
test_scp = '/content/drive/MyDrive/Colab_Notebooks/ModelScope/example_kws/test_wav.scp'
# 标签文件路径
trans_file = '/content/drive/MyDrive/Colab_Notebooks/ModelScope/example_kws/merge_trans.txt'
# 训练检查点路径
train_checkpoint = ''
# 测试检查点路径
test_checkpoint = ''
if enable_training: # 如果启用训练
kwargs = dict(
train_data=train_scp, # 训练数据文件路径
cv_data=cv_scp, # 交叉验证数据文件路径
trans_data=trans_file, # 转录文件路径
checkpoint=train_checkpoint, # 检查点路径
tensorboard_dir='tb_test', # TensorBoard日志目录
need_dump=True, # 是否需要保存模型
)
try:
# 训练模型
trainer.train(**kwargs) # 训练模型
except Exception as e:
print(f"Error during training: {e}")
rank = int(os.environ['RANK']) # 进程排名
world_size = int(os.environ['WORLD_SIZE']) # 总进程数
if world_size > 1 and rank != 0:# 如果总进程数大于1且排名不为0
enable_testing = False# 禁用测试
# s5
if enable_testing:# 如果启用测试
# 关键词
keywords = '小云小云'
# 测试结果保存目录
test_dir = os.path.join(work_dir, 'test_dir')
# 测试配置
kwargs = dict(
test_dir=test_dir, # 测试结果目录
test_data=test_scp, # 测试数据文件路径
trans_data=trans_file, # 转录文件路径
average_num=10, # 平均次数
gpu=0, # GPU ID
keywords=keywords, # 关键词
batch_size=256, # 批大小
)
# 评估模型
#print(f"test_checkpoint: {test_checkpoint}")
#print(f"kwargs: {kwargs}")
trainer.evaluate(test_checkpoint, None, **kwargs)
print(f"Test results are saved in {test_dir}/score.txt")
world_size = int(os.environ['WORLD_SIZE']) # 总进程数
if world_size > 1 and rank != 0:# 如果总进程数大于1且排名不为0
enable_testing = False# 禁用测试
# s5
if enable_testing:# 如果启用测试
# 关键词
keywords = '小云小云'
# 测试结果保存目录
test_dir = os.path.join(work_dir, 'test_dir')
# 测试配置
kwargs = dict(
test_dir=test_dir, # 测试结果目录
test_data=test_scp, # 测试数据文件路径
trans_data=trans_file, # 转录文件路径
average_num=10, # 平均次数
gpu=0, # GPU ID
keywords=keywords, # 关键词
batch_size=256, # 批大小
)
# 评估模型
#print(f"test_checkpoint: {test_checkpoint}")
#print(f"kwargs: {kwargs}")
trainer.evaluate(test_checkpoint, None, **kwargs)
print(f"Test results are saved in {test_dir}/score.txt")
5.5 模型评价
查看运行输出的日志文件score.txt文件如下:
20200707_spk57db_storenoise52db_40cm_xiaoyun_sox_50 detected 小云小云 0.935
20200707_spk57db_storenoise52db_40cm_xiaoyun_sox_38 detected 小云小云 0.992
fd59df10517f4a92ab9b1d31cd94c0b9_362d4ab870bf4722962fa4d087d8062f rejected
20200707_spk57db_storenoise52db_40cm_xiaoyun_sox_48 detected 小云小云 0.841
20200707_spk57db_storenoise52db_40cm_xiaoyun_sox_6 detected 小云小云 0.991
fd59df10517f4a92ab9b1d31cd94c0b9_ad1f518a7bdc4f57b355fb1aaddcd9c6 rejected
20200707_spk57db_storenoise52db_40cm_xiaoyun_sox_37 detected 小云小云 0.982
20200707_spk57db_storenoise52db_40cm_xiaoyun_sox_41 detected 小云小云 0.988
fd59df10517f4a92ab9b1d31cd94c0b9_e5c46479973a41a8b3ba04010a69d4c6 rejected
20200707_spk57db_storenoise52db_40cm_xiaoyun_sox_30 detected 小云小云 0.819
fd59df10517f4a92ab9b1d31cd94c0b9_0b448e3108604646a9828403fa722dc1 rejected
我们通过上述文件进一步统计并画出Det曲线如下图5。
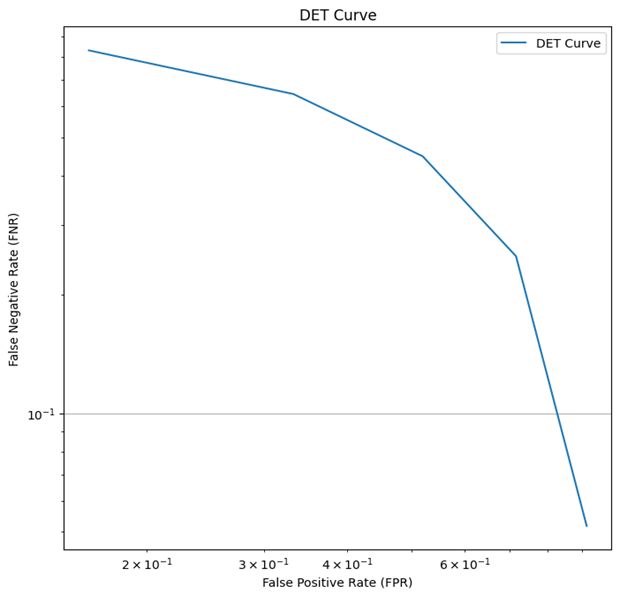
图5 Det曲线
六、总结
综上所述,本文最终通过wekws模型和百度的预训练模型对论文Compact Feedforward Sequential Memory Networks for Small-footprint Keyword Spotting进行了复现,并且在其基础上尝试更换新的数据集的操作,最终根据开源数据集,basetrain使用内部移动端ASR数据5000+小时;finetune使用1万条众包安静场景"小云小云"数据以及约20万条移动端ASR数据进行训练。最终得到的结果为:模型在自建9个场景各50句的正样本集(共450条)测试,唤醒率为93.11%;在自建的移动端负样本集上测试,误唤醒为40小时0次。但是考虑到正负样本测试集覆盖场景不够全面,可能有特定场合/特定人群唤醒率偏低或误唤醒偏高问题。
参考文献:
[1]Chen, M., Zhang, S., Lei, M., Liu, Y., Yao, H., Gao, J. (2018) Compact Feedforward Sequential Memory Networks for Small-footprint Keyword Spotting. Proc. Interspeech 2018, 2663-2667.
[2]wenet-e2e/wekws: Production First and Production Ready End-to-End Keyword Spotting Toolkit (github.com)
[3]CTC语音唤醒-移动端-单麦-16k-小云小云 · 模型库 (modelscope.cn)