【遥感专题系列】影像信息提取之——面向对象的影像分类技术
“同物异谱,同谱异物”会对影像分类产生的影响,加上高分辨率影像的光谱信息不是很丰富,还有经常伴有光谱相互影响的现象,这对基于像素的分类方法提出了一种挑战,面向对象的影像分类技术可以一定程度减少上述影响。
本专题以ENVI中的面向对象的特征提取FX工具为例,对这种技术和处理流程做一个简单的介绍。
本专题包括以下内容:
- 面向对象分类技术概述
- ENVI FX简介
- ENVI FX操作说明
1、面向对象分类技术概述
面向对象分类技术集合临近像元为对象用来识别感兴趣的光谱要素,充分利用高分辨率的全色和多光谱数据的空间,纹理,和光谱信息来分割和分类的特点,以高精度的分类结果或者矢量输出。它主要分成两部分过程:对象构建和对象的分类。
影像对象构建主要用了影像分割技术,常用分割方法包括基于多尺度的、基于灰度的、纹理的、基于知识的及基于分水岭的等分割算法。比较常用的就是多尺度分割算法,这种方法综合遥感图像的光谱特征和形状特征,计算图像中每个波段的光谱异质性与形状异质性的综合特征值,然后根据各个波段所占的权重,计算图像所有波段的加权值,当分割出对象或基元的光谱和形状综合加权值小于某个指定的阈值时,进行重复迭代运算,直到所有分割对象的综合加权值大于指定阈值即完成图像的多尺度分割操作。
影像对象的分类,目前常用的方法是“监督分类”和“基于规则(知识)分类”。这里的监督分类和我们常说的监督分类是有区别的,它分类时和样本的对比参数更多,不仅仅是光谱信息,还包括空间、纹理等对象属性信息。基于规则(知识)分类也是根据影像对象的属性和阈值来设定规则进行分类。
表1为三大类分类方法的一个大概的对比。
| 类型 |
基本原理 |
影像的最小单元 |
适用数据源 |
缺 陷 |
| 传统基于光谱的分类方法 |
地物的光谱信息特征 |
单个的影像像元 |
中低分辨率多光谱和高光谱影像 |
丰富的空间信息利用率几乎为零 |
| 基于专家知识决策树 |
根据光谱特征、空间关系和其他上下文关系归类像元 |
单个的影像像元 |
多源数据 |
知识获取比较复杂 |
| 面向对象的分类方法 |
几何信息、结构信息以及光谱信息 |
一个个影像对象 |
中高分辨率多光谱和全色影像 |
速度比较慢 |
表1 传统基于光谱、基于专家知识决策树与基于面向对象的影像分类对比表
2、ENVI FX简介
全名叫“面向对象空间特征提取模块—Feature Extraction”,基于影像空间以及影像光谱特征,即面向对象,从高分辨率全色或者多光谱数据中提取信息,该模块可以提取各种特征地物如车辆、建筑、道路、桥、河流、湖泊以及田地等。该模块可以在操作过程中随时预览影像分割效果。该项技术对于高光谱数据有很好的处理效果,对全色数据一样适用。对于高分辨率全色数据,这种基于目标的提取方法能更好的提取各种具有特征类型的地物。一个目标物体是一个关于大小、光谱以及纹理(亮度、颜色等)的感兴趣区域。
可应用于:
- 从影像中尤其是大幅影像中查找和提取特征。
- 添加新的矢量层到地理数据库
- 输出用于分析的分类影像
- 替代手工数字化过程
具有易于操作(向导操作流程),随时预览效果和修改参数,保存参数易于下次使用和与同事共享,可以将不同数据源加入ENVI FX中(DEMs、LiDAR datasets、shapefiles、地面实测数据)以提高精度、交互式计算和评估输出的特征要素、提供注记工具可以标识结果中感兴趣的特征要素和对象等特点。
3、ENVI FX操作说明
ENVI FX的操作可分为两个部分:发现对象(Find Object)和特征提取(Extract features),如图1所示。
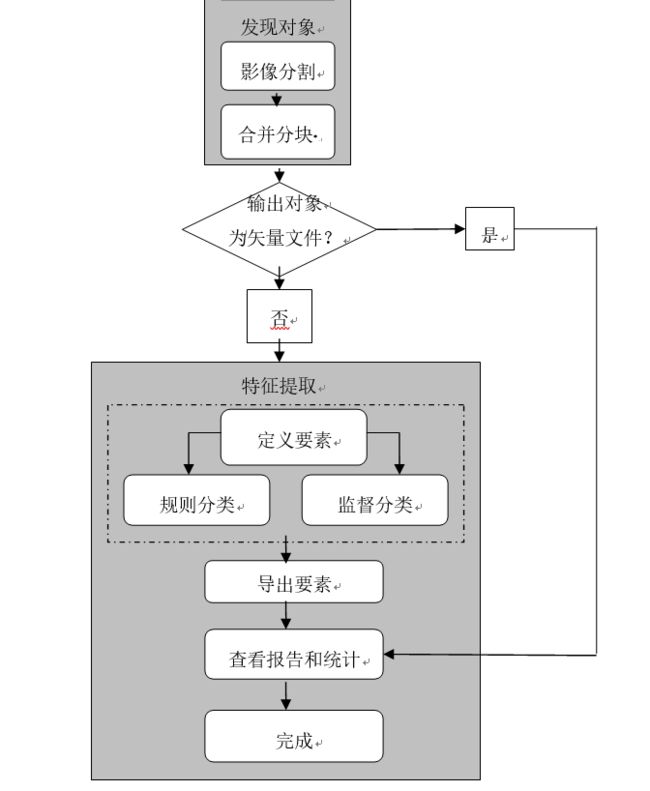
图1 FX操作流程示意图
下面在ENVI5.x下的FX工具,以0.6米的QB图像为例,介绍向对象信息提取的流程。下面我们。
3.1 基于规则的面向对象信息提取
该方法的工具为Toolbox /Feature Extraction/ Rule Based Feature Extraction Workflow
第一步:准备工作
根据数据源和特征提取类型等情况,可以有选择地对数据做一些预处理工作。
- 空间分辨率的调整
如果您的数据空间分辨率非常高,覆盖范围非常大,而提取的特征地物面积较大(如云、大片林地等)。可以降低分辨率,提供精度和运算速度。可利用Toolbox/Raster Management/Resize Data工具实现。
- 光谱分辨率的调整
如果您处理的是高光谱数据,可以将不用的波段除去。可利用Toolbox/Raster Management/Layer Stacking工具实现。
ENVI5.6版本后改为/Raster Management/Build Layer Stack
- 多源数据组合
当您有其他辅助数据时候,可以将这些数据和待处理数据组合成新的多波段数据文件,这些辅助数据可以是DEM, lidar 影像, 和SAR 影像。当计算对象属性时候,会生成这些辅助数据的属性信息,可以提高信息提取精度。可利用Toolbox/Raster Management/Layer Stacking工具实现。
ENVI5.6版本后改为/Raster Management/Build Layer Stack
- 空间滤波
如果您的数据包含一些噪声,可以选择ENVI的滤波功能做一些预处理。
这里直接在ENVI中打开qb_colorado.dat图像文件。
第二步:发现对象
- 启动Rule Based FX工具
在Toolbox中,找到Feature Extraction,选择/Feature Extraction/Rule Based Feature Extraction Workflow,打开工作流的面板,选择待分类的影像qb_colorado.dat,此外还有三个面板可切换:在Input Mask面板可输入掩膜文件,在Ancillary Data面板可输入其他多源数据文件,切换到Custom Bands面板,有两个自定义波段,包括归一化植被指数或者波段比值、HSI颜色空间,这些辅助波段可以提高图像分割的精度,如植被信息的提取等自定义的属性,在Normalized Difference和Color Space属性上打钩,如下图所示,点击Next;


图2 输入数据和属性参数选择
- 影像分割、合并
FX根据临近像素亮度、纹理、颜色等对影像进行分割,它使用了一种基于边缘的分割算法,这种算法计算很快,并且只需一个输入参数,就能产生多尺度分割结果。通过不同尺度上边界的差异控制,从而产生从细到粗的多尺度分割。
选择高尺度影像分割将会分出很少的图斑,选择一个低尺度影像分割将会分割出更多的图斑,分割效果的好坏一定程度决定了分类效果的精确度,我们可以通过preview预览分割效果,选择一个理想的分割阀值,尽可能好地分割出边缘特征。有两个图像分割算法供选择:
- Edge, 基于边缘检测,需要结合合并算法可以达到最佳效果;
- Intensity: 基于亮度,这种算法非常适合于微小梯度变化(如DEM)、电磁场图像等,不需要合并算法即可达到较好的效果。
调整滑块阀值对影像进行分割,这里设定阈值为40。
注:按钮
![]()
是用来选择分割波段的,默认为Base Image所有波段。
影像分割时,由于阈值过低,一些特征会被错分,一个特征也有可能被分成很多部分。我们可以通过合并来解决这些问题。合并算法也有两个供选择:
- Full Lambda Schedule,合并存在于大块、纹理性较强的区域,如树林、云等,该方法在结合光谱和空间信息的基础上迭代合并邻近的小斑块;
- Fast Lambda: 合并具有类似的颜色和边界大小相邻节段。设定一定阈值,预览效果。
这里我们设置的阈值为90,点Next进入下一步。
Texture Kernal Size:纹理内核的大小,如果数据区域较大而纹理差异较小,可以把这个参数设置大一点。默认是3,最大是19。
注:这一步是可选项,如果不需要可以按照默认的0直接跳过。

图3 图像分割、合并
这时候FX生成一个Region Means 影像自动加载图层列表中,并在窗口中显示,它是分割后的结果,每一块被填充上该块影像的平均光谱值。接着进行下一步操作。
目前,已经完成了发现对象的操作过程,接下来是特征的提取。
第三步:根据规则进行特征提取
在规则分类界面。每一个分类有若干个规则(Rule)组成,每一个规则有若干个属性表达式来描述。规则与规则之间是与的关系,属性表达式之间是并的关系。
同一类地物可以由不同规则来描述,比如水体,水体可以是人工池塘、湖泊、河流,也可以是自然湖泊、河流等,描述规则就不一样,需要多条规则来描述。每条规则又有若干个属性来描述,如下是对水的一个描述:
- 面积大于500像素
- 延长线小于5
- NDVI小于25
对道路的描述:
- 延长线大于9
- 紧密度小于3
- 标准差小于20
这里以提取居住房屋为例来说明规则分类的操作过程。
首先分析影像中容易跟居住房屋错分的地物有:道路、森林、草地以及房屋旁边的水泥地。
点击按钮
![]()
,新建一个类别,在右侧Class properties下修改好类别的相应属性。

图4 规则分类面板
- 第一条属性描述,划分植被覆盖和非覆盖区。
在默认的属性Spectral Mean上单击,激活属性,右边出现属性选择面板,如图所示。选择Spectral,Band下面选择Normalized Difference。在第一步自定义波段中选择的波段是红色和近红外波段,所以在此计算的是NDVI。把Show Attribute Image勾上,可以看到计算的属性图像。
通过拖动滑条或者手动输入确定阈值。在阈值范围内的在预览窗口里显示为红色,在Advanced面板,有三个类别归属的算法:算法有二进制、线性和二次多项式。选择二进制方法时,权重为0或者1,即完全不匹配和完全匹配两个选项;当选择线性和二次多项式时,可通过Tolerance设置匹配程度,值越大,其他分割块归属这一类的可能性就越大。这里选择类别归属算法为Liner,分类阈值Tolerance为默认的5,如下图

图5 对象属性面板

图6 归属类别算法和阈值设置
- 第二条属性描述,剔除道路干扰
居住房屋和道路的最大区别是房屋是近似矩形,我们可以设置Rectangular fit属性。在Rule上右键选择Add Attibute按钮,新建一个规则,在右侧Type中选择Spatial,在Name中选择Rectangular fit。设置值的范围是0.5~1,其他参数为默认值。
注:预览窗口默认是该属性的结果,点击All Classes,可预览几个属性共同作用的结果。
同样的方法设置
Type:Spatial;Name:Area——Area>45
Type:Spatial;Name:Elongation——Elongation<3
- 第三条属性描述,剔除水泥地干扰
水泥地反射率比较高,居住房屋反射率较低,所以我们可以设置波段的象元值。
Type:spectral;Name:Spectral Mean,Band:GREEN——Spectral Mean (GREEN)<650。
点击All Classes,最终的rule规则和预览图如下图所示。
注:单击
![]()
按钮,打开“房屋.rul”,可以导入预先设置的规则。
图7 房屋提取规则与结果
第四步:输出结果
特征提取结果输出,可以选择以下结果输出:矢量结果及属性、分类图像及分割后的图像、还有高级输出包括属性图像和置信度图像、辅助数据包括规则图像及统计输出,如下图所示。

图8 输出结果
这里我们选择矢量文件及属性数据一块输出,规则图像及统计结果输出。点击Finish按钮完成输出。可以查看房屋信息提取的结果和矢量属性表
类似的思路可以提取道路、林地、草地等分类,这里就不一一例举。
3.2 基于样本的面向对象的分类
该方法的工具为Toolbox /Feature Extraction/Example Based Feature Extraction Workflow。
在Toolbox中找打该工具,双击打开流程化的面板,前面两步和第一种方法的前两步完全一致,选择数据和发现对象,在此不一一赘述。我们直接看特征提取这部分:基于样本的图像分类。
第三步:基于样本的图像分类
经过图像分割和合并之后,进入到监督分类的界面,如下图所示:

图9监督分类界面
- 选择样本
对默认的一个类别,在右侧的Class Properties中,修改显示颜色、名称等信息。

图10 修改类别属性信息
在分割图上选择一些样本,为了方便样本的选择,可以在左侧图层管理中将Region Means图层关闭掉,显示原图,选择一定数量的样本,如果错选样本,可以在这个样本上点击左键删除。
一个类别的样本选择完成之后,新增类别,用同样的方法修改类别属性和选择样本。在选择样本的过程中,可以随时预览结果。可以把样本保存为shp文件以备下次使用。点击按钮可以将真实数据的ShapeFile矢量文件作为训练样本。
这里我们建立5个类别:道路、房屋、草地、林地、水泥地,分别选择一定数量的样本,如下图所示。

图11 选择样本
- 设置样本属性
切换到Attributes Selection选项。默认是所有的属性都被选择,这些选择样本的属性将被用于后面的监督分类。可以根据提取的实际地物特性选择一定的属性。这里按照默认全选。

图12 样本属性选择
- 选择分类方法
切换到Algorithm选项。FX提供了三种分类方法:K邻近法(K Nearest Neighbor)、支持向量机(Support Vector Machine ,SVM)和主成分分析法(Principal Components Analysis ,PCA)。

图13 分类方法
K邻近分类方法依据待分类数据与训练区元素在N维空间的欧几里得距离来对影像进行分类,N由分类时目标物属性数目来确定。相对传统的最邻近方法,K近邻法产生更小的敏感异常和噪声数据集,从而得到更准确地分类结果,它自己会确定像素最可能属于哪一类。
在K参数里键入一个整数,默认值是1,K参数是分类时要考虑的临近元素的数目,是一个经验值,不同的值生成的分类结果差别也会很大。K参数设置为多少依赖于数据组以及您选择的样本。值大一点能够降低分类噪声,但是可能会产生不正确的分类结果,一般值设到3-7之间就比较好。
支持向量机是一种来源统计学习理论的分类方法。选择这一项,需要定义一系列参数:
a)Kernel Type下拉列表里选项有 Linear,Polynomial,Radial Basis,以及 Sigmoid。
- 如果选择Polynomial,设置一个核心多项式(Degree of Kernel Polynomial)的次数用于SVM,最小值是1,最大值是6。
- 如果选择Polynomial or Sigmoid,使用向量机规则需要为Kernel指定 the Bias ,默认值是1。
- 如果选择是 Polynomial、Radial Basis、Sigmoid,需要设置Gamma in Kernel Function参数。这个值是一个大于零的浮点型数据。默认值是输入图像波段数的倒数。
b)为SVM规则指定the Penalty参数,这个值是一个大于零的浮点型数据。这个参数控制了样本错误与分类刚性延伸之间的平衡, 默认值是100。
Allow Unclassified是允许有未分类这一个类别,将不满足条件的斑块分到该类,默认是允许有未分类的类别。
Threshold 为分类设置概率域值,如果一个像素计算得到所有的规则概率小于该值,该像素将不被分类,范围是0~100,默认是5。
主成分分析是比较在主成分空间的每个分割对象和样本,将得分最高的归为这一类。
这里我们选择K邻近法,K参数设置为5,点击Next,输出结果。
最终结果的输出方法和基于规则的一样。
3.3 直接输出矢量
该方法的工具为Toolbox/Feature Extraction/Segment Only Feature Extraction Workflow。
操作方法参考前面的第一和第二步骤,第三步直接选择路径输出分割栅格结果和矢量结果。
从以上的实际操作可以看到,ENVI FX扩展模块操作具有易于操作(向导操作流程),随时预览效果和修改参数。
4、小结
基于像元的分类方法,依据主要是利用像元的光谱特征,大多应用在中低分辨率遥感图像。而高分辨率遥感图像的细节信息丰富,图像的局部异质性大,传统的基于像元的分类方法易受高分辨率影像局部异质性大的影响和干扰。而面向对象分类方法可以高分辨率图像丰富的光谱、形状、结构、纹理、相关布局以及图像中地物之间的上下文信息,可以结合专家知识进行分类,可以显著提高分类精度,而且使分类后的图像含有丰富的语义信息,便于解译和理解。对高分辨率影像来说,还是一种非常有效的信息提取方法,具有很好的应用前景。