基于Python的100+高质量爬虫开源项目(持续更新中)
前言
以下是项目所使用的框架,不同的项目所使用的框架或许有不同,但都万差不离:
Scrapy:一个快速的高级Web爬虫框架,可用于从网站中提取结构化数据。
BeautifulSoup:一个用于从HTML和XML文件中提取数据的Python库。
PySpider:一个轻量级,跨平台并基于事件的Python爬虫框架。
Tweepy:一个用于访问Twitter API的Python库,可用于采集Twitter数据。
Selenium:一个用于自动化Web浏览器的Python库,可用于模拟用户在网站上的操作。
如果有已更新的爬虫项目对大家的学习有帮助的话,可以点赞,打赏
如果有希望更新的爬虫也可以给博主提交,后续的更新中有可能就是你想学习的哦~
系列文章目录
注意:本系列所有的项目无论代码还是数据,仅供个人学习;毕业设计等参考使用,不允许直接使用在任何商业领域!如需要在商业领域使用请自行修改或定制!
本章为爬虫部分的讲解,如需要数据处理方面及机器学习等的应用案例,请关注博主的后续文章!
如需要完整代码的代码及数据,请在评论区留言~
| 哔哩哔哩 | QQ音乐 | 东方财富 | 中医资源 | 京东 | 今日头条 | 动漫人物 | 去哪儿 | 天气后报网 | 学习强国 |
| 拉勾网 | 新浪微博 | 汽车之家 | 淘宝网 | 知乎 | 网易云音乐 | 腾讯新闻 | 读书网 | 豆瓣电影 | 豌豆夹 |
| 起点中文网 | 4399小游戏 | 天天基金 | 抖音 | 豆瓣读书 | Steam | ||||
哔哩哔哩
网站介绍:
当我们谈起哔哩哔哩(Bilibili)时,很多人会想到它是一个弹幕视频网站,但事实上这个平台已经不仅仅是一个视频网站了。
哔哩哔哩成立于2009年,最初是一个以ACG(动漫、漫画、游戏)为主题的弹幕视频分享平台,它的独特之处就在于用户可以在视频上发表弹幕评论。这种弹幕形式让观众和内容创作者之间建立了更为紧密的联系,而当时的Bilibili也因此获得了众多ACG爱好者的追捧。
在经过多年的运营和发展之后,哔哩哔哩不仅成长为中国最具影响力的弹幕视频平台之一,还成为了拥有众多粉丝的文化娱乐社区。现在,哔哩哔哩已经涵盖了游戏、音乐、电影、综艺等多个领域,成为一个综合性的互联网文化平台,拥有亿万用户和众多的优质内容。
哔哩哔哩的用户文化也非常独特。在这个平台上,用户可以自由发表评论、发布视频、参与各种讨论活动,还可以和其他用户组成团队,打造属于自己的社群文化。而且,哔哩哔哩的用户群体年轻化程度比较高,这也促进了平台上各种潮流文化和年轻人的创新。
总体来说,哔哩哔哩不仅仅是一个视频网站,更是一个充满活力和自由的文化社区。未来,哔哩哔哩还将继续探索新的领域,为用户提供更好更有趣的内容和体验。
数据用途:
普通用途:大屏可视化、评论情绪分析等
进阶用途:喜好分析,推荐算法,趋势分析等
代码实现:
for key, value in paloads.items():
json_data = getVideoList(key, 1)
total = json_data['data']['total'] // 20 + 1
for page in range(1, total):
try:
json_data = getVideoList(key, page)
for video in json_data['data']['list']:
saveCSV(key, video)
progress_bar(key, page, total,video['title'])
except Exception as e:
print(e,json_data,paloads[key]['url'].format(page))
# 跳过错误,继续执行
continuefor index, row in video_list.iterrows():
try:
media_id = row['media_id']
url = 'https://www.bilibili.com/bangumi/media/md{}'.format(media_id)
response = requests.get(url)
jsonText = json.loads(re.search(r"window\.__INITIAL_STATE__=(.*?)};", response.text).group(1) + '}')
styless = jsonText['mediaInfo']['styles']
style = ''
for styles in styless:
style += styles['name'] + ' '
a = {
'media_id': [str(response.url).split('/md')[1]],
'actors': [jsonText['mediaInfo']['actors'].replace('\n', ' ').replace('、', ' ')],
'staff': [jsonText['mediaInfo']['staff'].replace('、', ' ')],
'introduction': [jsonText['mediaInfo']['evaluate']],
'season_version': [style],
'danmaku_count': [jsonText['mediaInfo']['stat']['danmakus']],
'play_count': [jsonText['mediaInfo']['stat']['views']],
'follow_count': [jsonText['mediaInfo']['stat']['favorites']],
'series_follow': [jsonText['mediaInfo']['stat']['series_follow']]
}
info_list = pd.DataFrame(a)
info_list.to_csv('dataset/bilibili_video_info.csv', index=False,mode='a',header=False)
progress_bar('视频信息爬取进度', index + 1, len(video_list), str(response.url).split('/md')[1])
except Exception as e:
print(e)
continuefor index, row in video_list.iterrows():
try:
media_id = row['media_id']
page = ''
while True:
json_data = getVideoList(media_id,page)
if json_data['data']['list'] == None:
break
for video in json_data['data']['list']:
saveCSV(video)
progress_bar('视频评论爬取进度', index + 1, len(video_list), video['content'])
page += 1
if page > 10:
break
except Exception as e:
continuefor index, row in video_list.iterrows():
url = row['cover_img']
media_id = row['media_id']
r = requests.get(url)
with open('output/images/{}.jpg'.format(media_id), 'wb') as f:
f.write(r.content)
print('正在下载第' + str(index) + '张图片'+'共'+str(len(video_list))+'张'+',图片名为:'+str(row['media_id']) + '.jpg')数据预览:


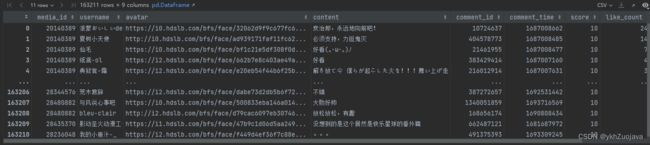

QQ音乐
网站介绍:
QQ音乐是一款中国大陆的在线音乐播放器,由腾讯公司推出,提供了海量的音乐资源,包括国内外最热门的歌曲、最新的音乐专辑、MV等。用户可以通过QQ音乐听歌、搜索歌曲、创建歌单、分享音乐等功能,同时还可以进行付费下载、在线听歌等操作。QQ音乐还拥有个性化推荐功能,根据用户的喜好和听歌历史,自动推荐精准的音乐,让用户更好地享受音乐的乐趣。
数据用途:
大屏可视化,喜好分析等
代码实现:
for url in urls:
html = requests.get(url['url']).text
html = BeautifulSoup(html, 'lxml')
song_list = html.find('ul', class_='songlist__list').find_all('li')
for song in song_list:
top_num = song.find('div', class_='songlist__number').text
song_name = song.find('span', class_='songlist__songname_txt').text
is_vip = song.find('i', class_='songlist__icon songlist__icon_vip sprite')
is_mv = song.find('a', class_='songlist__icon songlist__icon_mv sprite')
song_author = song.find('a', class_='playlist__author').text
song_time = song.find('div', class_='songlist__time').text
song_url = song.find('a', class_='songlist__cover')['href']
a = {
'top_name': [url['name']],
'top_num': [top_num],
'song_name': [song_name],
'is_vip': ['VIP' if is_vip else ''],
'is_mv': ['MV' if is_mv else ''],
'song_author': [song_author],
'song_time': [song_time],
'song_url': ['https://y.qq.com{}'.format(song_url)]
}
print(a)
top_list = pd.DataFrame(a)
top_list.to_csv('dataset/top_list.csv', index=False,mode='a',header=False)for singer in singer_list:
singer_name = singer.find_element(By.TAG_NAME,'a').text
singer_url = singer.find_element(By.TAG_NAME,'a').get_attribute('href')
singer_id = singer_url.split('/')[-1]
print(singer_name, singer_url, singer_id)
a = {
'singer_id': [singer_id],
'singer_name': [singer_name],
'singer_url': [singer_url]
}
df = pd.DataFrame(a)
df.to_csv('dataset/singer_list.csv', mode='a', header=False, index=False)for index,value in singer_list.iterrows():
try:
singer_info, song_list = getPage(value['singer_url'])
print('歌手:{},歌曲:{},歌曲数:{},进度:{}/{}'.format(value['singer_name'], singer_info['singer_song_num'],
len(song_list), index + 1, len(singer_list)))
singer_list.loc[singer_list['singer_id'] == value['singer_id'], 'singer_intro'] = singer_info['singer_intro']
singer_list.loc[singer_list['singer_id'] == value['singer_id'], 'singer_song_num'] = singer_info[
'singer_song_num']
singer_list.loc[singer_list['singer_id'] == value['singer_id'], 'singer_album_num'] = singer_info[
'singer_album_num']
singer_list.loc[singer_list['singer_id'] == value['singer_id'], 'singer_mv_num'] = singer_info['singer_mv_num']
singer_list.loc[singer_list['singer_id'] == value['singer_id'], 'singer_fans_num'] = singer_info[
'singer_fans_num']
singer_list.to_csv('dataset/singer_list.csv', index=False)
song_list = pd.DataFrame(song_list)
song_list['singer_id'] = value['singer_id']
song_list = song_list[
['singer_id', 'singer_song_id', 'singer_song_name', 'singer_song_url', 'singer_song_album_name',
'singer_song_album_url', 'singer_song_time']]
song_list.to_csv('dataset/song_list.csv', mode='a', header=False, index=False)
except Exception as e:
print(e)
pass数据预览:



东方财富
网站介绍:
东方财富是中国领先的互联网金融信息及数据服务提供商。公司成立于1994年,总部位于中国上海市。东方财富提供股票、基金、债券、期货等多种金融产品的信息服务,涵盖了全球各地区的金融市场数据和研究报告。东方财富还提供投资咨询、金融科技解决方案等服务。目前,公司已经成为中国最大的金融信息服务平台之一,拥有超过6000万活跃用户。
数据用途:
可视化,预测,推荐,关键字等
代码实现:
def parse(self, response):
key = response.meta['key']
url = response.meta['url']
# 将响应数据转换为json数据
json_data = response.text
#去掉响应数据中的jQuery(和后面的),只保留()中的json数据
json_data = json_data[json_data.find('(')+1:json_data.rfind(')')]
#将json数据转换为字典
json_data = json.loads(json_data)
#获取数量总数
total_size = json_data['data']['total']
#获取当前页码
current_page = response.meta['page']
#获取每页数量
page_size = response.meta['page_size']
#计算总页数
total_page = math.ceil(total_size/page_size)
#获取当前页的数据
data = json_data['data']['diff']
#遍历当前页的数据
for item in data:
'''
f12:股票代码
f14:股票名称
f2:最新价
f3:涨跌幅
f4:涨跌额
f5:成交量
f6:成交额
f7:振幅
f8:换手率
f9:市盈率
f10:量比
f11:5分钟涨跌幅
f13:涨或跌 1涨 0跌
f15:最高价
f16:最低价
f17:今开价
f18:昨收价
f20:总市值(单位元)
f21:流通市值(单位元)
f22:涨速
f23:市净率
f24:60日涨跌幅
f25:年初至今涨跌幅
f26:上市时间
f115:市盈率(动态)
'''
sli = StockListItem()
#分类
sli['category'] = key
#获取股票代码
sli['code'] = item['f12']
#获取股票名称
sli['name'] = item['f14']
#获取最新价
sli['price'] = item['f2']
#获取涨跌幅
sli['change_percent'] = item['f3']
#获取涨跌额
sli['change_amount'] = item['f4']
#获取成交量
sli['volume'] = item['f5']
#获取成交额
sli['amount'] = item['f6']
#获取振幅
sli['amplitude'] = item['f7']
#获取换手率
sli['turnover_rate'] = item['f8']
#获取市盈率
sli['pe'] = item['f9']
#获取量比
sli['volume_ratio'] = item['f10']
#获取5分钟涨跌幅
sli['five_minute_change_percent'] = item['f11']
#获取涨或跌 1涨 0跌
sli['up_or_down'] = item['f13']
#获取最高价
sli['high_price'] = item['f15']
#获取最低价
sli['low_price'] = item['f16']
#获取今开价
sli['open_price'] = item['f17']
#获取昨收价
sli['close_price'] = item['f18']
#获取总市值(单位元)
sli['total_market_value'] = item['f20']
#获取流通市值(单位元)
sli['circulation_market_value'] = item['f21']
#获取涨速
sli['change_speed'] = item['f22']
#获取市净率
sli['pb'] = item['f23']
#获取60日涨跌幅
sli['sixty_day_change_percent'] = item['f24']
#获取年初至今涨跌幅
sli['year_to_date_change_percent'] = item['f25']
#获取上市时间
sli['listing_date'] = item['f26']
#获取市盈率(动态)
sli['dynamic_pe'] = item['f115']
yield sli
# 打印key,数量总数,当前页码,每页数量,总页数
if current_page < total_page:
print({
'分类': key,
'数量总数': total_size,
'当前页码': current_page,
'每页数据量': page_size,
'总页数': total_page,
})
#如果当前页码小于总页数,继续发送请求
current_page += 1
yield scrapy.Request(
url=url.format(current_page,page_size,key),
callback=self.parse,
meta={'page':current_page,'page_size':page_size,'key':key,'url':url}
) def parse(self, response):
code = response.meta['code']
name = response.meta['name']
category = response.meta['category']
json_data = json.loads(response.text)['dstx']
data = json_data['data']
for item in data:
sni = StockNoticeItem()
sni['code'] = code
sni['name'] = name
sni['category'] = category
sni['event_type'] = item[0]['EVENT_TYPE']
sni['level1_content'] = item[0]['LEVEL1_CONTENT']
sni['level2_content'] = item[0]['LEVEL2_CONTENT']
sni['notice_date'] = item[0]['NOTICE_DATE']
sni['specific_eventtype'] = item[0]['SPECIFIC_EVENTTYPE']
yield sni
hasNext = json_data['hasNext']
if hasNext==1:
pageIndex = response.meta['pageIndex']
url = self.paloads['getDate'].format(code, pageIndex+1)
yield scrapy.Request(url=url, callback=self.parse,
meta={'code': code, 'name': name, 'category': category, 'pageIndex': pageIndex+1})
pass def parse(self, response):
code = response.meta['code']
name = response.meta['name']
category = response.meta['category']
json_data = json.loads(response.text)
json_data = json_data['data']
date = ''
for item in json_data:
date = date + str(item['REPORT_DATE']).split(' ')[0] +','
date = date[:-1]
url = self.paloads['getInfo'].format(date,response.meta['code'])
yield scrapy.Request(url=url, callback=self.parse_info, meta={'code':code,'name':name,'category':category})
pass def parse(self, response):
# 去掉响应数据中的jQuery(和后面的),只保留()中的json数据
json_data = response.text[response.text.find('(') + 1:response.text.rfind(')')]
json_data = json.loads(json_data)
print(json_data['data'])
# code
code = json_data['data']['code']
# name
name = json_data['data']['name']
# klines
klines = json_data['data']['klines']
for kline in klines:
skli = StockKLineItem()
# 代码
skli['code'] = code
# 名称
skli['name'] = name
# 日期
skli['date'] = kline.split(',')[0]
# 开盘价
skli['open'] = kline.split(',')[1]
# 收盘价
skli['close'] = kline.split(',')[2]
# 最高价
skli['high'] = kline.split(',')[3]
# 最低价
skli['low'] = kline.split(',')[4]
# 成交量
skli['volume'] = kline.split(',')[5]
# 成交额
skli['amount'] = kline.split(',')[6]
# 振幅
skli['amplitude'] = kline.split(',')[7]
# 涨跌幅
skli['change_percent'] = kline.split(',')[8]
# 涨跌额
skli['change_amount'] = kline.split(',')[9]
# 换手率
skli['turnover_rate'] = kline.split(',')[10]
print('当前正在爬取的股票代码为:{},名字:,日期:{}'.format(code,skli['name'],skli['date']))
yield skli
pass数据预览:




中医资源网
网站介绍:
中医资源网是一个集中医相关信息、知识、资源的网站,包含中医药相关的疾病诊疗、中药方剂、针灸推拿、养生保健、文化传承等多个方面内容。用户可以在网站上查找中医病案、中药方剂、针灸推拿技术、中医养生保健、中医文化传承等方面的资料,也可以参加在线教育培训,学习中医相关专业知识和技能。中医资源网的宗旨是传承和发扬中医药文化,推广中医药知识和技术,提高公众的健康意识和健康素养,促进中医药事业的发展。
数据用途:
可视化,问答机器人,推荐
代码实现:
def parse(self, response):
# 获取拼音索引
pinyin = response.meta['pinyin']
# 获取所有的药品
# 使用xpath定位id为"DataList1"的table
table = response.xpath('//*[@id="DataList1"]')
# 使用xpath定位table下的所有tr
trs = table.xpath('./tr')
# 遍历trs
for tr in trs:
# 使用xpath定位tr下的所有td
tds = tr.xpath('./td')
# 遍历tds
for td in tds:
# 取出td中第二个a标签的文本,链接
name = td.xpath('./a[2]/text()').extract_first()
link = td.xpath('./a[2]/@href').extract_first()
link = 'http://www.tcmdoc.cn/shujuku/zhongyao/{}'.format(link)
zhongyao = ZhongyaoItem()
zhongyao['name'] = name
zhongyao['link'] = link
zhongyao['pinYin_index'] = pinyin
zhongyao['image_urls'] = ''
zhongyao['pinYin_name'] = ''
zhongyao['alias'] = ''
zhongyao['source'] = ''
zhongyao['habitat'] = ''
zhongyao['taste'] = ''
zhongyao['function'] = ''
zhongyao['dosage'] = ''
zhongyao['excerpt'] = ''
zhongyao['character'] = ''
zhongyao['processing'] = ''
zhongyao['protomorph'] = ''
zhongyao['remarks'] = ''
yield scrapy.Request(url=link, callback=self.parse_detail,meta={'zhongyao':zhongyao})
pass数据预览:
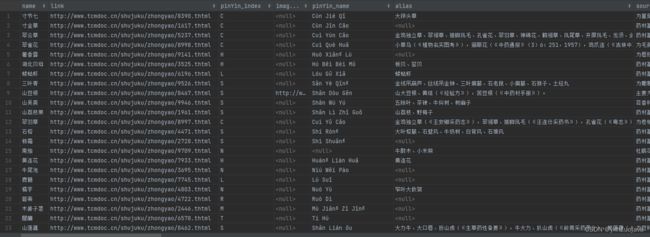
京东
网站介绍:
京东网,简称京东,是中国最大的综合性电子商务公司之一,成立于2004年,总部位于北京市。京东商城提供一站式的电子商务解决方案,包括在线购物、客户服务、物流配送等业务,为消费者提供优质的商品选择和购物体验。京东商城的产品包括家电、手机、电脑数码、服装、家居、母婴、食品等多个品类,同时也提供海外购、团购、超市等服务。京东商城以“诚信、共赢、客户为先、追求卓越”为核心价值观,致力于成为全球领先的电子商务企业。
数据用途:
可视化,推荐,预测
代码实现:
def parse(self, response):
keyword = response.meta['keyword']
print('>>>>>>>>>>>>>>>>>keyword:', keyword)
# 使用xpath解析数据,定位到id为J_goodsList的div标签,然后再定位到所有的li标签
li_list = response.xpath('//div[@id="J_goodsList"]/ul/li')
for li in li_list:
item = JdGoodsItem()
# 使用xpath解析数据,定位到id为J_goodsList的div标签,然后再定位到所有的li标签
item['keyword'] = keyword['keyword']
item['title'] = li.xpath('./div/div[@class="p-name p-name-type-2"]/a/em/text()').extract_first()
# 去掉特殊字符
try:
item['title'] = item['title'].replace('\n', '').replace('\r', '').replace('\t', '').replace(' ', '')
except:
pass
try:
item['link'] = 'https:' + li.xpath('./div/div[@class="p-name p-name-type-2"]/a/@href').extract_first()
except:
item['link'] = ''
item['price'] = li.xpath('./div/div[@class="p-price"]/strong/i/text()').extract_first()
item['shop'] = li.xpath('./div/div[@class="p-shop"]/span/a/text()').extract_first()
item['commit'] = li.xpath('./div/div[@class="p-commit"]/strong/a/text()').extract_first()
item['shop_id'] = item['link'].split('/')[-1].split('.')[0]
# 去掉+号,并把单位 万替换 -> 0000
try:
item['commit'] = item['commit'].replace('+', '').replace('万', '0000')
except:
pass
item['img'] = li.xpath('./div/div[@class="p-img"]/a/img/@src').extract_first()
yield item
# 下一页
if keyword['now_page'] < keyword['max_page']:
keyword['now_page'] += 2
new_url = format(self.next_url % (keyword['keyword'], keyword['now_page'], keyword['now_page'] * keyword['page_size']))
yield scrapy.Request(new_url, callback=self.parse, meta={'keyword': keyword})
else:
# 下一个关键字
if len(self.keywords) > 0:
self.keywords.pop(0)
if len(self.keywords) > 0:
key = self.keywords[0]
yield scrapy.Request(self.url % key['keyword'], callback=self.parse, meta={'keyword': key}) def parse(self, response):
# 去掉所有的html标签
print(response.text)
# TODO 这里有个问题,就是返回的数据是html,但是返回的数据中又包含了html标签,所以需要去掉
text = response.text.replace('', '').replace('', '')
print(text)
json_data = json.loads(text)
for i in json_data['comments']:
print({
'shop_id': response.meta['id'],
'content': i['content'],
'creationTime': i['creationTime'],
'nickname': i['nickname'],
'score': i['score'],
})
item = JdGoodsCommitItem()
item['shop_id'] = response.meta['id']
item['content'] = i['content']
item['creationTime'] = i['creationTime']
item['nickname'] = i['nickname']
item['score'] = i['score']
yield item
maxPage = json_data['maxPage']
# TODO maxPage > 5 时,强制设置为2,如果你想要全部的评论,可以把这个注释去掉
if maxPage > 2:
maxPage = 2
page = response.meta['page']
if page < maxPage:
page += 1
yield scrapy.Request(url=self.comment_url.format(page=page, id=response.meta['id']), callback=self.parse, meta={'page': page, 'id': response.meta['id']})
pass
数据预览:



今日头条
网站介绍:
今日头条是中国的一家新闻平台,提供国内外新闻、科技、娱乐、美食等丰富内容,为用户推荐个性化的阅读。它是一家基于算法推荐的信息聚合平台,旨在为用户提供个性化的流媒体信息服务。
数据用途:
可视化,关键字分析,情绪分析
代码实现:
def parse(self, response):
# 定位 class="feed-card-wrapper feed-card-article-wrapper" 的div
article_lists = response.xpath('//div[@class="feed-card-wrapper feed-card-article-wrapper"]')
video_lists = response.xpath('//div[@class="feed-card-wrapper feed-card-video-wrapper"]')
wtt_lists = response.xpath('//div[@class="feed-card-wrapper feed-card-wtt-wrapper"]')
# self.parse_article(article_lists)
print('文章列表>>>>>>>', len(article_lists))
for list in article_lists:
# class="feed-card-article-l" 的div
article = list.xpath('./div/div[@class="feed-card-article-l"]')
link = article.xpath('./a/@href').extract_first()
content = article.xpath('./a/text()').extract_first()
author = article.xpath('.//div[@class="feed-card-footer-cmp-author"]/a/text()').extract_first()
author_link = article.xpath('.//div[@class="feed-card-footer-cmp-author"]/a/@href').extract_first()
item = TouTiaoItem()
item['type'] = 'article'
item['class_type'] = response.meta['type']
item['link'] = link
item['content'] = content
item['author'] = author
item['author_link'] = author_link
yield item
print('视频列表>>>>>>>', len(video_lists))
for list in video_lists:
# class="feed-card-article-l" 的div
if list.xpath('./div[@class="feed-card-video-multi"]'):
video = list.xpath('./div[@class="feed-card-video-multi"]/ul/li')
for v in video:
link = v.xpath('.//div[@class="feed-video-item"]/div/a/@href').extract_first()
content = v.xpath('.//div[@class="feed-video-item"]/div/a/@title').extract_first()
author_link = v.xpath('.//div[@class="footer"]//div[@class="feed-card-footer-cmp-author"]/a/@href').extract_first()
author = v.xpath('.//div[@class="footer"]//div[@class="feed-card-footer-cmp-author"]/a/text()').extract_first()
item = TouTiaoItem()
item['type'] = 'video'
item['class_type'] = response.meta['type']
item['link'] = link
item['content'] = content
item['author'] = author
item['author_link'] = author_link
yield item
elif list.xpath('./div[@class="feed-card-video-single"]'):
video = list.xpath('./div[@class="feed-card-video-single"]')
link = video.xpath('./div[@class="r-content"]/div[@class="feed-video-item"]/div[@class="feed-card-cover"]/a/@href').extract_first()
content = video.xpath('./div[@class="r-content"]/div[@class="feed-video-item"]/div[@class="feed-card-cover"]/a/@title').extract_first()
author = video.xpath('.//div[@class="footer"]//div[@class="feed-card-footer-cmp-author"]/a/text()').extract_first()
author_link = video.xpath('.//div[@class="footer"]//div[@class="feed-card-footer-cmp-author"]/a/@href').extract_first()
item = TouTiaoItem()
item['type'] = 'video'
item['class_type'] = response.meta['type']
item['link'] = link
item['content'] = content
item['author'] = author
item['author_link'] = author_link
yield item
print('wtt列表>>>>>>>', len(wtt_lists))
for list in wtt_lists:
if list.xpath('./div[@class="feed-card-wtt multi-covers"]'):
wtt = list.xpath('./div[@class="feed-card-wtt multi-covers"]')
author_link = wtt.xpath('./div[@class="feed-card-wtt-l"]//div[@class="feed-card-wtt-user-info"]/a/@href').extract_first()
author = wtt.xpath('./div[@class="feed-card-wtt-l"]//div[@class="feed-card-wtt-user-info"]/a/@title').extract_first()
link = wtt.xpath('./div[@class="feed-card-wtt-l"]/p/a/@href').extract_first()
content = wtt.xpath('./div[@class="feed-card-wtt-l"]/p/a/text()').extract_first()
item = TouTiaoItem()
item['type'] = 'wtt'
item['class_type'] = response.meta['type']
item['link'] = link
item['content'] = content
item['author'] = author
item['author_link'] = author_link
yield item
elif list.xpath('./div[@class="feed-card-wtt single-cover"]'):
wtt = list.xpath('./div[@class="feed-card-wtt single-cover"]')
author_link = wtt.xpath('./div[@class="feed-card-wtt-l"]//div[@class="feed-card-wtt-user-info"]/a/@href').extract_first()
author = wtt.xpath('./div[@class="feed-card-wtt-l"]//div[@class="feed-card-wtt-user-info"]/a/@title').extract_first()
link = wtt.xpath('./div[@class="feed-card-wtt-l"]/p/a/@href').extract_first()
content = wtt.xpath('./div[@class="feed-card-wtt-l"]/p/a/text()').extract_first()
item = TouTiaoItem()
item['type'] = 'wtt'
item['class_type'] = response.meta['type']
item['link'] = link
item['content'] = content
item['author'] = author
item['author_link'] = author_link
yield item
pass数据预览:



如果觉得这篇文章对你有帮助,请一键三连哦~