书生·浦语大模型实战营04课堂笔记
一、Finetune简介
1.LLM下游应用中,两种微调模式
一种是增量预训练:使用场景是让基座模型学习到一些新知识,如某个垂类领域的常识。其训练数据包括文章、书籍、代码等
另一种是指令跟随,其使用场景是让模型学会对话模板,根据人类指令进行对话。训练数据为高质量对话、问答数据。
2.指令跟随微调
2.1 原理
①一问一答的数据完成对话模板的角色构建;
②构建完成的数据输入到模型来计算损失;
③只对答案部分进行损失的计算
2.2 角色指定
指令跟随微调中包含多个角色,可以分为system、user、assistant三个角色。
system:给定上下文信息,比如:你是一个安全的AI助手/你是一位医生,你的回答是正确且耐心的
user:实际用户提出问题,比如:世界第一高峰是?
assistant:根据user的输入,结合system的上下文信息,做出回答,例如:珠穆朗玛峰。
不同的语言模型由不同的单位或组织发行,使用的对话模板也不相同.
LlaMa2以INST和方括号来包裹user,以双尖括号和SYS大写字符来包裹system角色内容。
InternLM的主要结构如下:
<|System|> System上下文开始
<|User|> User指令开始
<|Bot|>Assistant开始回答
注意:部署模型进行预测阶段,即真正和模型对话:不需要进行角色分配,用户输入内容默认被放到User部分,System部分由模板自动添加的。具体什么模板,在启动预测的时候,可以进行自定义
3.增量预训练
①增量预训练的数据不需要一文一答,他都是一个一个的陈述句,陈述事实;
②system和User的角色留空,增量预训练的数据放入到Assistant角色中,计算损失时,只计算Assistant部分的损失。
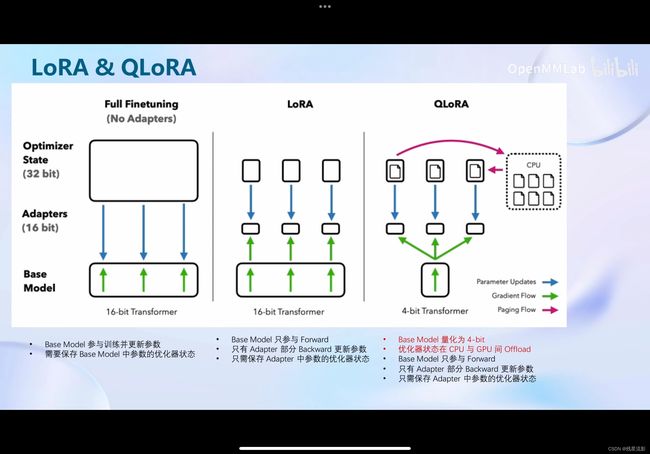
4.LORA&QLORA
4.1 LORA简介
①LORA全称:LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS;
②LLM的参数量主要集中在模型的Linear,训练这些参数时会消耗大量的显存。而LORA通过在原本的Linear旁,新增一个支路,包含两个连续的小Linear,新增的这个支路通常叫做Adapter。Adapter参数量远小于原本的Linear,能大幅降低显存
4.2 全参数微调、LORA和QLORA的区别
全参数微调:
①Base Model参数与训练并更新参数;②需要保存Base Model中参数的优化器状态
LORA:
①Base Model只参与Forward;②只有Adapter部分Backward更新参数;③只需要保存Adapter中参数的优化器状态
QLORA:
①Base Model 量化为4-bit;②优化器状态在CPU和GPU间Offload;③Base Model只参与Forward;④只有Adapter部分Backward更新参数;⑤只需要保存Adapter中参数的优化器状态。
详见下列示意图
二、xTuner简介
xtuner是一款打包好的大模型微调工具箱,支持从huggingface和modelspace加载数据。支持InternLM,llama,通义千问,百川,Mistral等多种语言大模型
三、8GB显卡玩转LLM
Flash Attention和DeepSpeed ZeRO是xTuner最重要的两个优化技巧:
Flash Attention:将Attention计算并行化,避免了计算过程中Attention ScoreNxN的显存占用
DeepSpeed ZeRO:①ZeROu优化,用过将训练过程中参数、梯度和优化器状态切片保存,能够在多GPU训练时显著节省显存;③除了将训练中间状态切片,DeepSpeed训练时使用FP16权重,相较于Pytorch的AMP训练,单GPU上也能大幅减少显存。
四、动手实战环节
1.快速上手
平台说明:Ubuntu + Anaconda + CUDA/CUDNN + 8GB nvidia显卡
2.安装依赖
1.使用InternStudio可以很简单创建环境
/root/share/install_conda_env_internlm_base.sh xtuner0.1.92.激活环境
conda activate xtuner0.1.9
3.创建并进入目录
mkdir xtuner019 && cd xtuner0194.拉取源码
git clone -b v0.1.9 https://github.com/InternLM/xtuner5.进入源码目录后,安装源码
pip install -e '.[all]'
安装完成后,准备在 oasst1 数据集上微调 internlm-7b-chat
3.微调
1.拷贝配置文件至当前目录
cd ~/ft-oasst1
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .2.模型下载
因为在InternStudio中已经由对应文件,我们这里可以直接拷贝
cp -r /root/share/temp/model_repos/internlm-chat-7b ~/ft-oasst1/不用 xtuner 默认的从 huggingface 拉取模型,而是提前从 ModelScope 下载模型到本地
# 创建一个目录,放模型文件,防止散落一地
mkdir ~/ft-oasst1/internlm-chat-7b
# 装一下拉取模型文件要用的库
pip install modelscope
# 从 modelscope 下载下载模型文件
cd ~/ft-oasst1
apt install git git-lfs -y
git lfs install
git lfs clone https://modelscope.cn/Shanghai_AI_Laboratory/internlm-chat-7b.git -b v1.0.33.数据集下载
InternStudio已经下载好的数据,我们直接拷贝
cd ~/ft-oasst1
# ...-guanaco 后面有个空格和英文句号啊
cp -r /root/share/temp/datasets/openassistant-guanaco .4.修改配置文件
cd ~/ft-oasst1
vim internlm_chat_7b_qlora_oasst1_e3_copy.py减号代表删除,加号代表增加
# 修改模型为本地路径
- pretrained_model_name_or_path = 'internlm/internlm-chat-7b'
+ pretrained_model_name_or_path = './internlm-chat-7b'
# 修改训练数据集为本地路径
- data_path = 'timdettmers/openassistant-guanaco'
+ data_path = './openassistant-guanaco'5.开始微调
xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py应为ssh连接的特性,很容易断开连接,我们这里使用tmux进行操作
首先更新apt
然后使用apt安装tmux
安装完成后,使用tmux new -s finetune 创建一个新sesstion,进入后我们将bash命令重新运行,这样就不会终端了
![]()

同时按CTRL+B 松开后再按D,会重新回到终端页面中
这里输入 tmux attach -t finetune会重新回到创建的tmux的session
![]()
6.完成训练
训练结果如下图所示
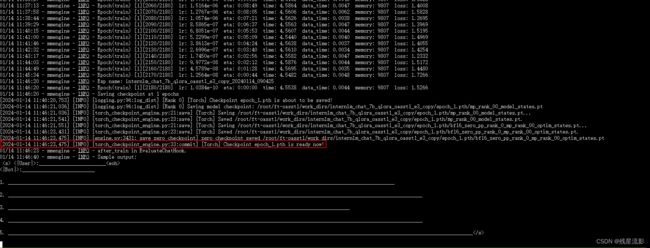
7.将得到的 PTH 模型转换为 HuggingFace 模型
mkdir hf
export MKL_SERVICE_FORCE_INTEL=1使用xtuner转换
xtuner convert pth_to_hf ./internlm_chat_7b_qlora_oasst1_e3_copy.py ./work_dirs/internlm_chat_7b_qlora_oasst1_e3_copy/epoch_1.pth ./hf
转换完成
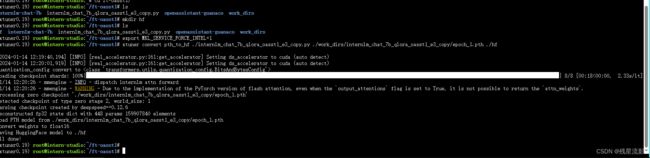
4.部署与微调
1.将 HuggingFace adapter 合并到大语言模型
运用以下命令合并
xtuner convert merge ./internlm-chat-7b ./hf ./merged --max-shard-size 2GB![]()
2.与合并之后的模型对话
# 加载 Adapter 模型对话(Float 16)
xtuner chat ./merged --prompt-template internlm_chat
# 4 bit 量化加载
# xtuner chat ./merged --bits 4 --prompt-template internlm_chatfloat16模式下,输出答案会“一个一个单词蹦出来”,速度较慢;4bit量化输出答案会有些损失,但生成结果很快。
以下是4bit量化后的数据,生成速度比之前快很多
五、自定义微调
1.概述
以 Medication QA 数据集为例
基于 InternLM-chat-7B 模型,用 MedQA 数据集进行微调,往医学领域对齐。
| 问题 | 答案 |
|---|---|
| What are ketorolac eye drops?(什么是酮咯酸滴眼液?) | Ophthalmic ketorolac is used to treat itchy eyes caused by allergies. It also is used to treat swelling and redness (inflammation) that can occur after cataract surgery. Ketorolac is in a class of medications called nonsteroidal anti-inflammatory drugs (NSAIDs). It works by stopping the release of substances that cause allergy symptoms and inflammation. |
| What medicines raise blood sugar? (什么药物会升高血糖?) | Some medicines for conditions other than diabetes can raise your blood sugar level. This is a concern when you have diabetes. Make sure every doctor you see knows about all of the medicines, vitamins, or herbal supplements you take. This means anything you take with or without a prescription. Examples include: Barbiturates. Thiazide diuretics. Corticosteroids. Birth control pills (oral contraceptives) and progesterone. Catecholamines. Decongestants that contain beta-adrenergic agents, such as pseudoephedrine. The B vitamin niacin. The risk of high blood sugar from niacin lowers after you have taken it for a few months. The antipsychotic medicine olanzapine (Zyprexa). |
2.将数据转为 XTuner 的数据格式
[{
"conversation":[
{
"system": "xxx",
"input": "xxx",
"output": "xxx"
}
]
},
{
"conversation":[
{
"system": "xxx",
"input": "xxx",
"output": "xxx"
}
]
}]3.开始微调
新建一个文件夹来玩“微调自定义数据集”
mkdir ~/ft-medqa && cd ~/ft-medqa把前面下载好的internlm-chat-7b模型文件夹拷贝过来。
cp -r ~/ft-oasst1/internlm-chat-7b .将自定义数据集转移
git clone https://github.com/InternLM/tutorial
cp ~/tutorial/xtuner/MedQA2019-structured-train.jsonl .4.准备配置文件
# 复制配置文件到当前目录
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
# 改个文件名
mv internlm_chat_7b_qlora_oasst1_e3_copy.py internlm_chat_7b_qlora_medqa2019_e3.py
# 修改配置文件内容
vim internlm_chat_7b_qlora_medqa2019_e3.py# 修改import部分
- from xtuner.dataset.map_fns import oasst1_map_fn, template_map_fn_factory
+ from xtuner.dataset.map_fns import template_map_fn_factory
# 修改模型为本地路径
- pretrained_model_name_or_path = 'internlm/internlm-chat-7b'
+ pretrained_model_name_or_path = './internlm-chat-7b'
# 修改训练数据为 MedQA2019-structured-train.jsonl 路径
- data_path = 'timdettmers/openassistant-guanaco'
+ data_path = 'MedQA2019-structured-train.jsonl'
# 修改 train_dataset 对象
train_dataset = dict(
type=process_hf_dataset,
- dataset=dict(type=load_dataset, path=data_path),
+ dataset=dict(type=load_dataset, path='json', data_files=dict(train=data_path)),
tokenizer=tokenizer,
max_length=max_length,
- dataset_map_fn=alpaca_map_fn,
+ dataset_map_fn=None,
template_map_fn=dict(
type=template_map_fn_factory, template=prompt_template),
remove_unused_columns=True,
shuffle_before_pack=True,
pack_to_max_length=pack_to_max_length)5.训练
xtuner train internlm_chat_7b_qlora_medqa2019_e3.py --deepspeed deepspeed_zero2 同样的按照上面步骤将其转换为huggingface模型,再拼接即可
同样的按照上面步骤将其转换为huggingface模型,再拼接即可
部署与测试同上
六、用 MS-Agent 数据集 赋予 LLM 以 Agent 能力
1.概述
MSAgent 数据集每条样本包含一个对话列表(conversations),其里面包含了 system、user、assistant 三种字段。其中:
-
system: 表示给模型前置的人设输入,其中有告诉模型如何调用插件以及生成请求
-
user: 表示用户的输入 prompt,分为两种,通用生成的prompt和调用插件需求的 prompt
-
assistant: 为模型的回复。其中会包括插件调用代码和执行代码,调用代码是要 LLM 生成的,而执行代码是调用服务来生成结果的。
2.微调
从国内的 ModelScope 平台下载 MS-Agent 数据集
# 准备工作
mkdir ~/ft-msagent && cd ~/ft-msagent
cp -r ~/ft-oasst1/internlm-chat-7b .
# 查看配置文件
xtuner list-cfg | grep msagent
# 复制配置文件到当前目录
xtuner copy-cfg internlm_7b_qlora_msagent_react_e3_gpu8 .
# 修改配置文件中的模型为本地路径
vim ./internlm_7b_qlora_msagent_react_e3_gpu8_copy.py 3.开始微调:训练
xtuner train ./internlm_7b_qlora_msagent_react_e3_gpu8_copy.py --deepspeed deepspeed_zero24.使用
由于 msagent 的训练非常费时,大家如果想尽快把这个教程跟完,可以直接从 modelScope 拉取咱们已经微调好了的 Adapter。如下演示。
下载adapter
cd ~/ft-msagent
apt install git git-lfs
git lfs install
git lfs clone https://www.modelscope.cn/xtuner/internlm-7b-qlora-msagent-react.git添加环境变量
export SERPER_API_KEY=abcdefg
# 其中abcdefg为apikey启动xtuner
xtuner chat ./internlm-chat-7b --adapter internlm-7b-qlora-msagent-react --lagent如果出现错误:
xtuner chat 增加 --lagent 参数后,报错 TypeError: transfomers.modelsauto.auto factory. BaseAutoModelClass.from pretrained() got multiple values for keyword argument "trust remote code"
注释掉已安装包中的代码:
vim /root/xtuner019/xtuner/xtuner/tools/chat.py