浅谈Flink架构及拓扑图
文章目录
- 01 引言
- 02 Flink架构
- 03 Flink拓扑结构
-
- 3.1 Flink的四层执行图
- 3.2 执行图细节
- 3.3 更多
01 引言
声明:本文是博主阅读云邪(Jark)博客整理后的笔记,如有侵权,可联系博主删除。
本文参考文章如下:
- https://wuchong.me/blog/2016/05/03/flink-internals-overview/
- https://wuchong.me/blog/2016/05/04/flink-internal-how-to-build-streamgraph/
- https://wuchong.me/blog/2016/05/10/flink-internals-how-to-build-jobgraph/
- https://developer.aliyun.com/article/225618#
02 Flink架构
无论是flink on yarn 还是flink on kubernetes等其它模式,最终Flink启动成功之后的架构图如下:

从上述架构图,可以看到主要分为如下三个模块(且三者均为独立的JVM进程):
| 模块 | 描述 |
|---|---|
| Client | 是一个用于管理Flink作业的客户端(提交、取消、监听状态以及采集指标),只要确保与JobManager环境联通即可 |
| JobManager | 接收来自Client的请求并生成执行计划,并以task为单元,调度到各个TaskManager去执行,同时协调task做checkpoint,以及接收来自TaskManager的状态、心跳、统计等 |
| TaskManager | 在启动的时候就设置好了槽位数(Slot),每个 slot 能启动一个 Task,Task 为线程,注意有可能不同的Job/Task混合在一个TaskManager进程中,因为Flink的任务调度是多线程模型的 |
我们注意到了,JobManager接收到Client的请求之后,会生成执行计划,也就是对应上图的Dataflow Graph,这一块在flink中比较核心,也是下面继续讲讲的Flink 拓扑结构。
03 Flink拓扑结构
我们上传Flink SDK里面的/examples/streaming/TopSpeedWindowing.jar至Flink集群之后,点击“show plan”可以看到执行计划图:

执行计划图如下:
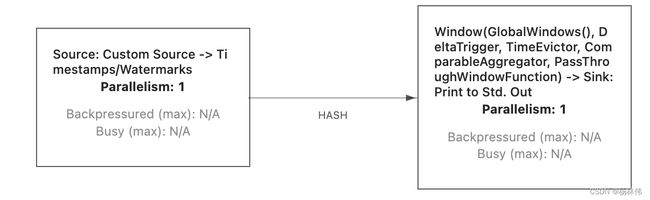
当然,也可以在TopSpeedWindow的主程序里,直接获取执行计划的json(ExecutionEnvironment.getExecutionPlan()),并复制json至https://wints.github.io/flink-web//visualizer/(官网的生成plan地址挂了,这里是博主另外找的),json如下:
{
"nodes" : [ {
"id" : 1,
"type" : "Source: Custom Source",
"pact" : "Data Source",
"contents" : "Source: Custom Source",
"parallelism" : 1
}, {
"id" : 2,
"type" : "Timestamps/Watermarks",
"pact" : "Operator",
"contents" : "Timestamps/Watermarks",
"parallelism" : 1,
"predecessors" : [ {
"id" : 1,
"ship_strategy" : "FORWARD",
"side" : "second"
} ]
}, {
"id" : 4,
"type" : "Window(GlobalWindows(), DeltaTrigger, TimeEvictor, ComparableAggregator, PassThroughWindowFunction)",
"pact" : "Operator",
"contents" : "Window(GlobalWindows(), DeltaTrigger, TimeEvictor, ComparableAggregator, PassThroughWindowFunction)",
"parallelism" : 10,
"predecessors" : [ {
"id" : 2,
"ship_strategy" : "HASH",
"side" : "second"
} ]
}, {
"id" : 5,
"type" : "Sink: Print to Std. Out",
"pact" : "Data Sink",
"contents" : "Sink: Print to Std. Out",
"parallelism" : 10,
"predecessors" : [ {
"id" : 4,
"ship_strategy" : "FORWARD",
"side" : "second"
} ]
} ]
}
执行图如下:

3.1 Flink的四层执行图
到这里,会有很多小伙伴会有疑问,咋这么多图呢?实际上可能更多,但是,Flink 按执行流程,执行图可以分为四层:StreamGraph → JobGraph → ExecutionGraph → 物理执行图。
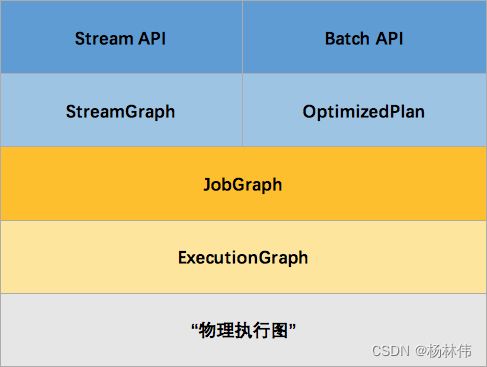
这里博主整理了每种“图”的概念,方便大家的理解:
| 图 | 概念 | 备注 |
|---|---|---|
| StreamGraph | 用户通过 Stream API 编写的代码生成的最初的图 | 用来表示程序的拓扑结构。这里还提下 OptimizedPlan,它是由 Batch API转换而来的,StreamGraph 是由Stream API 转换而来的,而Batch 和 Stream 的图结构和优化方法有很大的区别,所以分开了。 |
| JobGraph | StreamGraph经过优化后生成了JobGraph,提交给 JobManager的数据结构 |
主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗 |
| ExecutionGraph | JobManager 根据JobGraph 生成ExecutionGraph |
ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构 |
| 物理执行图 | JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager上部署 Task 后形成的“图”,并不是一个具体的数据结构 |
物理执行图就是最终分布式在各个机器上运行着的tasks了 |
3.2 执行图细节
Job的不同阶段都有不同的执行流程图,其目的都是为了解耦,细节流程图如下:
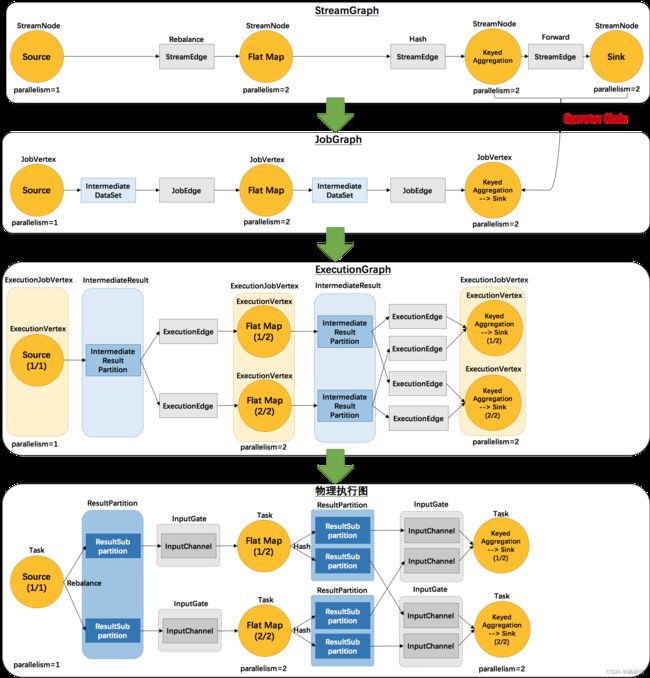
这里针对上述细节的流程图再做每一部分的名词解释。
StreamGraph:根据用户通过 Stream API 编写的代码生成的最初的图
| 名词 | 概念 |
|---|---|
| StreamNode | 用来代表 operator 的类,并具有所有相关的属性,如并发度、入边和出边等 |
| StreamEdge | 表示连接两个StreamNode的边 |
JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构
| 名词 | 概念 |
|---|---|
| JobVertex | 经过优化后符合条件的多个StreamNode可能会chain在一起生成一个JobVertex,即一个JobVertex包含一个或多个operator,JobVertex的输入是JobEdge,输出是IntermediateDataSet |
| IntermediateDataSet | 表示JobVertex的输出,即经过operator处理产生的数据集。producer是JobVertex,consumer是JobEdge |
| JobEdge | 代表了job graph中的一条数据传输通道。source 是 IntermediateDataSet,target 是 JobVertex。即数据通过JobEdge由IntermediateDataSet传递给目标JobVertex |
ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
| 名词 | 概念 |
|---|---|
| ExecutionJobVertex | 和JobGraph中的JobVertex一一对应。每一个ExecutionJobVertex都有和并发度一样多的 ExecutionVertex |
| ExecutionVertex | 表示ExecutionJobVertex的其中一个并发子任务,输入是ExecutionEdge,输出是IntermediateResultPartition |
| IntermediateResult | 和JobGraph中的IntermediateDataSet一一对应。一个IntermediateResult包含多个IntermediateResultPartition,其个数等于该operator的并发度 |
| IntermediateResultPartition | 表示ExecutionVertex的一个输出分区,producer是ExecutionVertex,consumer是若干个ExecutionEdge |
| ExecutionEdge | 表示ExecutionVertex的输入,source是IntermediateResultPartition,target是ExecutionVertex。source和target都只能是一个 |
| Execution | 是执行一个 ExecutionVertex 的一次尝试。当发生故障或者数据需要重算的情况下 ExecutionVertex 可能会有多个 ExecutionAttemptID。一个 Execution 通过 ExecutionAttemptID 来唯一标识。JM和TM之间关于 task 的部署和 task status 的更新都是通过 ExecutionAttemptID 来确定消息接受者。 |
物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
| 名词 | 概念 |
|---|---|
| Task | Execution被调度后在分配的 TaskManager 中启动对应的 Task。Task 包裹了具有用户执行逻辑的 operator |
| ResultPartition | 代表由一个Task的生成的数据,和ExecutionGraph中的IntermediateResultPartition一一对应 |
| ResultSubpartition | 是ResultPartition的一个子分区。每个ResultPartition包含多个ResultSubpartition,其数目要由下游消费 Task 数和 DistributionPattern 来决定 |
| InputGate | 代表Task的输入封装,和JobGraph中JobEdge一一对应。每个InputGate消费了一个或多个的ResultPartition |
| InputChannel | 每个InputGate会包含一个以上的InputChannel,和ExecutionGraph中的ExecutionEdge一一对应,也和ResultSubpartition一对一地相连,即一个InputChannel接收一个ResultSubpartition的输出 |
3.3 更多
本文仅仅是浅显的谈了Flink架构和拓扑,如果想对每一种“图”有一个更清晰的认识,可以参考:
- 《如何生成 StreamGraph?》
https://wuchong.me/blog/2016/05/04/flink-internal-how-to-build-streamgraph/ - 《如何生成 JobGraph?》
https://wuchong.me/blog/2016/05/10/flink-internals-how-to-build-jobgraph/ - 《如何生成ExecutionGraph及物理执行图?》:
https://developer.aliyun.com/article/225618#