通用人工智能的能力评估框架-Levels of AGI Operationalizing Progress on the Path to AGI
通用人工智能的能力评估框架-Levels of AGI: Operationalizing Progress on the Path to AGI
- 译自’Levels of AGI: Operationalizing Progress on the Path to AGI’,有所删节.
- 笔者能力有限,敬请勘误。
摘要
Google DeepMind提出一种针对通用人工智能 (Artificial General Intelligence, 简称AGI) 框架,该框架用于评估AGI的模型及早期版本的能力和表现。该分类框架详细阐述了AGI性能、适用范围及自治力(autonomy) 的不同层次。Google希望该框架能和自动驾驶技术等级框架一样有用,为AGI提供一套通用语言便于对AGI进行模型比较、风险评估及跟踪其发展进展。
Google分析了目前AGI的定义,提炼出兼具深度(能力-performance)与广度(适用性)的6大原则作为AIG评估框架的分类体系。
原始信息

- 地址:arxiv.org/pdf/2311.02…
引言
通用人工智能(Artificial General Intelligence, 简称:AGI) 是计算研究中重要又有争议的一个概念,它用于描述在大部分至少可以拥有与人类一样能力的人工智能系统。 得益于机器学习(Machine Learning ,ML) 模型的飞速发展,AGI的概念已经从哲学争论走到具体实践。目前有人认为AGI已出现在近代的大语言模型中(large language models,LLMs) ,有人预言AI将在10年人赶超人类,甚至有人直言现有的LLMs就是AGI。
关于AGI的定义100个AI领域的专家有会有到100种不同但又有联系的答案,事实上AGI概念的重要性源于它与AI的目标、预测与风险相关。
对许多领域的人来说,达到人类水平的“智能"是隐而不言的唯一目标。1955的达特茅斯人工智能会议(Dartmouth Artificial Intelligence Conference) 为研究AI技术的企业开创了人工智能的领域, 这些公司的使命宣言中包含了诸如“确保变革性的人工智能帮助到人类与社会"和"确保通用人工智能的目标是造福人类"等条款。
AGI的概念与它是否走向拥有更强、更接近或超越人类的通用性有关。 AGI通常是和"涌现"的概念交织在一块。这些涌现的能力包括与人类的技能形成互补的能力, 而这些能力有可能带动与AGI有关的新型互动等类型的新产业。同时对AGI能力的预测演变成了对社会影响的预测,比如,AGI可能会带来重大经济影响,是否达到广泛劳动力替代的必要标准;以及地缘政治的影响(AGI可能带来的经济优势或军事相关等)。
AGI被某些人认为是一种极端风险的概念。这些人认为AGI系统可能会实施欺骗、操纵,实行自我资源的积累,推进目标及代理某人的行为,在大部分的领域智力超过人类,在关键角色上取代人类以及有可能进行自我学习与提升。
"涌现"能力是指开发人员未明确预期但AI系统在运行时突然出现的能力
AGI定义:9个案例研究
许多人工智能的人员与组织已提出了AGI的定义。在本节中,我们列出9个有代表性的案例并分析了这些定义的优劣。这份分析为我们随后引入的AGI能力评估框架的二维分层法提供了分析依。
案例1: 图灵测试 - The Turing Test
图灵在1950年提出的图灵测试应该是最著名的将AGI概念付诸实践的最著名的尝试。图灵的"模仿游戏"是一种测试机器是否具备人类智能的方法,即要求人类以交互的方式来分辨文字的另一端是人还是机器。 最初的测试框架是一个思想试验,遭到很多的的批判。 在实际的测试中,这个测试通常在强调如何更好的骗过人类而不是在强调机器的"智能化"程度。 考虑到现阶段的LLM已经过了某些图灵框架的测试, 这更加证明“图灵测试"的这一标准并不能作为AGI的评判标基准。
Googlle认为图灵机器是否能“思考"是一个有趣哲学和科学问题,但AGI要以能力来定义而非过程(processes)。
**案例2: 强人工智能 - Strong AI - Systems Possessing Consciousness **
哲学家John Searle提出: “根据’强人工智能’,计算机不仅仅一个研究大脑的工具, 相反,一个编写了程序的计算机实际上是一种人的思维(思维 mind), 从这个意义上来说,给定正确程序的计算机可以说成是具有他人意识”。虽然强人工智能可能是一种通向AGI的路径,但就确定机器是否拥有强人工智能的属性(比如意识)的方法上并没有科学共识。
案例3: 类比人脑 - Analogies to the Human Brain
最初使用"通用人工智能"这一术语是在1997年的Mark Gubrud的一个军事技术的文章中,在该文章中AGI被定义为"在复杂性与速度上超过了人类大脑,它可用于知识获取,操纵和推理,适用于任何需要人工智能的工业或军事行动的任何阶段上"的智能系统。 这个早期定义除了强调AI的能力还强调过程(复杂度媲美人类)。 虽然现代机器学习(modern ML)下的神经网络架构是受人脑的启发而生, 但基于transformer架构体系的成功并不依赖于类人的学习, 因此对于AGI来说是否具有严格人类大脑的思维过程和基准并不是必须的。
案例4:人类认知任务的表现 - Human-Level Performance on Cognitive Task
2001年Legg和Goertzel在计算机科学家间推广’AGI’这一术语,将AGI描述为一个 能够执行人类可完成的认知任务 的机器。 这个定义关注点在了非物理任务上(即无需一个机器人作为AGI的实体)。 和许多AGI的定义一样,这个框架在"做什么任务"和 "哪些人"的选择上存在歧义。
案例5:学习任务的能力 - Ability to Learn Tasks
在《技术奇点》(The Technological Singularity)一书中,Shanahan提出了AGI的定义:AGI是指“并不是要专门完成某一特定任务,而是可以学习和执行人类的广泛任务”的人工智能。这个框架有一个很重要的属性,就是它强调了包括元认知任务(学习)对实现AGI要求的重要性。
案例6:经济价值的工作 - Economically Valuable Work
OpenAI的章程对AGI的的定义是: “一个最具经济价值的工作过胜过人类的高度自治的系统”。这个定义具有优势,它强调"能力而非过程"这一标准,得点关注了系统的能力而非不是其底层机制;而且这个定义提供了一个潜在的衡量标准,即经济价值。
该定义的缺点是他并没有涵盖"通用智能"的所有的标准。许多与智力相关的任务(如艺术创造力与情感智商等)虽没有直接经济价值,但也有间接的价值(比如艺术创造力产出书籍或电影,情商有可能与能否成为一名出色的CEO的能力有关)。
从经济价值来定义AGI的带来的另个问题就是框架必须经过实施部署,而能力关注的焦点应该是AGI执行一个任务的潜力。
案例7:灵活性与通用性 - Flexible and General
Flexible and General – The “Coffee Test” and Related Challenges
Marcus认为AGI是 “任务灵活性与通用性的简写,其智能水平与可靠性和人类相当甚至超越”。 这个定义涵盖了 通用性和能力, 且它提到的"灵活性"是很有价值的,像Shanahan的公式一样,这个提议涵盖了如学习新技能的元认知任务的AGI能力,只有具备元认知任务的AGI才能足够的通用。
而且Marcus通过5项具体的任务来测试他定义(理解电影,理解小说内容,烹饪,写一个无bug的1万行程序,将自句语言的数学证明转为了符号形式)。但对于该评测系统是否将AGI的状态全部纳入Google表示并未知晓。
案例8:人工能力的智能 - Artificial Capable Intelligence
《在即将到来的浪潮》一书中,Suleyman提出了“人工能力的智能(Artificial Capable Intelligence ACI)”,并提出AI系统是指是一个具有足够能力和通用性的人工智能系统,在现实世界中可以完成复杂且多步骤的任务。具体来说,Suleyman提出了一个基于经济的ACI技能定义,被认为是“现在图灵测试”,即给定人工智能10万美元的资本要求其在10个月内将其升值为100万美元。
这个框架比OpenAI的经济价值工作的定义更狭窄,它有一个额外的缺点就是只以财务利润为目标会会潜在引入结盟的风险。然而,Suleyman概念的优势在专注在人类重视的执行一个复杂的表多步骤的任务,这些任务比当前AI的基准测试更具生态有效性。Marcus的上述五项灵活性和通用性测试似乎也符合ACI的精神。
案例9: SOTA的通才 - SOTA LLMs as Generalists
SOTA LLMs as Generalists
Agüera y Arcas and Norvig 提出了最新的LLMs(GPT-4, Bard, Llama 2 和 Claude)就是AGI。他们认为通用性是AGI的关键属性, 因为语言模型可以讨论很多主题,执行许多任务,处理多模态的输入与输出,以多语言的方式操控及及可以零样本和少样本的学习,这些足以达到通用性的标准。
Google认为该定义只有通用性这一AGI的重要特征,执行力(performance)并没过多的提及。
AGI定义-六大原则
聚焦能力而不是过程: 该原则让我们可以将以下两点排除在外:
- AGI的实现并不意味着系统一定盯以人类的方式思考或理解(这是关注过程的重要表现)
- AGI的实现并不意味着系统具有主观意识或感知能力等品质(这些品质不仅在关注过程而且目前无法进行科学测量)
保证通用性与能力(Performance)
AGI是否需要领域通用以及在某一领域执行如何两者同样重要,缺一不可。
重视认知与元认知任务
元认知能力(诸如学习新任务的任务或何时需要向人类澄清和协助的能力)是一个AI系统是否具有通用性的关键且必要条件。
是否需要一个机器人身体作为定义AGI的准标一定是一个充满争议的问题。目前大多数定义都聚集在认知任务上,也就是我们说的非物理任务。
核心在于潜力而非部署
只要一个系统在有能力执行给定能力的任务,就可以证明他拥有AGI的能力。因为是否在现实世界中部署这么一套系统需要考虑的因素很多(法律、道德、安全等等)不该作为定义AGI的必要条件。
关注生态有效性
选择与人类真实世界(即生态有效)的价值一致的任务非常重要(这些任不仅是经济价值,还有社会价值与艺术价值等)。我们要避开传统的人工智能指标,因为后者虽然容易自然化与量化但可能无法捕促到人们看重的AGI技能。
关注AGI路径而非单一终端
我们计划为每一层次的AGI设定一组明确的指标或基准,为每一级别引入可识别的风险,并由此改变人工智能的交互范式。
这种基于层级的AGI定义有利于与许多著名的公式与之共存,例如,Aguera y Arcas和Norvig的定义属于我们的"新兴AGI"类别,而OpenAI的劳动力替代阈值更符合"Virtuoso AGI", 其他的对于AGI的许多现有定义(例如Legg、Shanahan和Suleyman的公式等)我们归属这些分类至"合格AGI"水平。
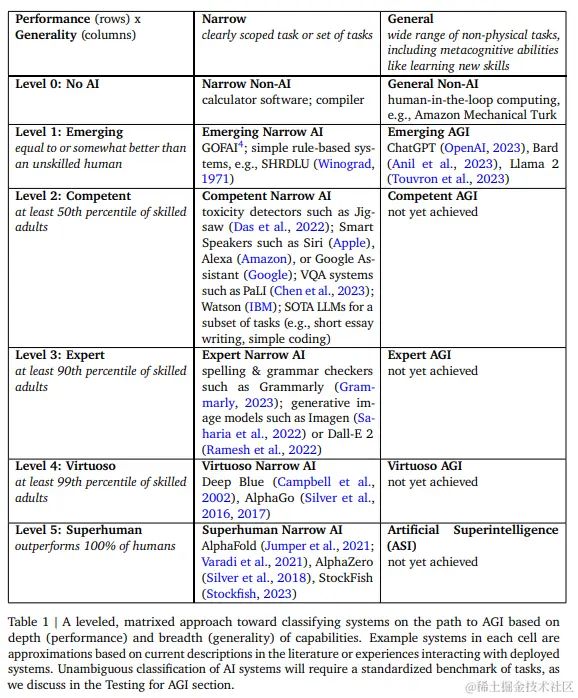
AGI能力水平分类框架(二维分层法) - Levels of AGI -
Level0: No AI
- 专用(Narrow): 计算机软件;编译器
- 通用(General):人机回圈计算,比如亚马逊土耳其机器人
Level1: 新兴(Emerging)
- 专用(Narrow):新兴IA。GOFA。GOFAI4; 简单的基于规则系统。simple rule-based systems, e.g., SHRDLU
- 通用(General):新兴AGI:** ChatGPT(OpenAI, 2023), Bard (Anil et al., 2023), Llama 2 (Touvron et al., 2023)
Level2: 熟练(Competent)
- 专用(Narrow): 恶意评估检测器,如Jigsaw;智能扬声器,如Siri;Alexa或Google助手,VQA系统,如PaLI;Watson; SOTA LLMs的子任务(例如,短文写作、简单编码等)
- 通用(General):还没达到
Level3: 专家(Expert)
- 专用(Narrow): 拼写与语法检查,如法语; 图像生成如Imagen 或 Dall-E 2
- 通用(General):还未达成
Level4: 大师(Virtuoso)
- 专用(Narrow): Deep Blue(深蓝),AlphaGo
- 通用(General): 还没达到
Level5: 超人类(Superhuman)
- 专用(Narrow): AlphaFold,AlphaZero,StockFish
- 通用(General):还没达到
- 人机回圈(Human-in-the-loop, HITL) 是一种人与机器的交互方式。
- Amazon Mechanical Turk: 亚马逊土耳其机器人
- GOFAI (Good Old-Fashioned Artificial Intelligence) 有效的老式人工智能(狭义人工智能)
- SHRDLU : 一种早期的自然语言理解计算机程序
- Stockfish: 国际象棋引擎
原表
总结
共享AGI的概念与含义将有助于:
- 模型比较,风险评估与应对策略(mitigation strategies);
- 明确政策制定者与监管机构的标准;
- 确定研发的目标、预期(predictions) 和风险,
- 以及理解我们现在通话AIG道路上的所处位置。
附录: 达特茅斯人工智能会议-Dartmouth Artificial Intelligence Conference
会议内容有:
- C.E香农(C.E. Shannon)的研究提案
- M.L.明斯基(M.L.Minsky)的研究提案
- N.罗切斯特(N.Rochester)的研究提案
- 约翰·麦卡锡JohnMcCarthy)的研究提案
- 对人工智能问题感兴趣的人
www.360doc.com/content/19/…