系统调用的概念及原理
系统调用与内核函数
内核函数与普通函数形式上没有什么区别,只不过前者在内核实现,因此要满足一些内核编程的要求。
系统调用是用户进程进入内核的接口层,它本身并非内核函数,但它是由内核函数实现的,进入内核后,不同的系统调用会找到相应的内核函数,这些内核函数被称为系统调用的“服务例程”。
比如系统调用getpid()实际调用的是服务例程sys_getpid(),也可以说,系统调用getpid()是服务例程sys_getpid()的“封装例程”。
系统调用基本概念
计算机的各种硬件资源是有限的,为了更好的管理这些资源,用户进程是不允许直接操作的,所有对这些资源的访问都必须由操作系统控制。为此操作系统为用户态运行的进程与硬件设备之间进行交互提供了一组接口,这组接口就是所谓的系统调用。
那么在应用程序和硬件之间设置这样一个接口层有什么优点呢?
1. 把用户从学习硬件设备的低级编程特性中解放出来。
2. 提高了系统的安全性,内核在满足某个请求之前就可以在接口级检查这个请求的正确性。
3. 最重要的是,这些接口使得程序更具有可移植性,因为只要不同操作系统所提供的一组接口相同,那么在这些操作
系统上就可以正确的编译和执行相同的程序。
系统调用实质上就是函数调用,只不过调用的是系统函数,处于内核态而已。 用户在调用系统调用时会向内核传递一个系统调用号,然后系统调用处理程序通过此号从系统调用表中找到相应的内核函数执行,最后返回。
系统调用号
Linux系统有几百个系统调用,为了唯一的标识每一个系统调用,Linux为每一个系统调用定义了一个唯一的编号,这个编号就是系统调用号。(在我的电脑上,它是在 /usr/include/x86_64-linux-gnu/asm/unistd_32.h, 可以通过 find / -name unistd_32.h -print 查找)。
系统调用号的另一个目的是作为系统调用表的下标,当用户空间的进程执行一个系统调用的时侯,这个系统调用号就被用来指明到底是要执行那个系统调用。
系统调用表
为了把系统调用号与相应的服务例程关联起来,内核利用了一个系统调用表,存放在sys_call_table数组中,它是一个函数指针数组,每一个函数指针都指向其系统调用的封装例程,有NR_syscalls个表项,第n个表项包含系统调用号为n的服务例程的地址。
系统调用处理函数
系统调用最终还是会由内核函数完成,那么为什么不直接调用内核函数呢?
这是因为用户空间的程序无法直接执行内核代码,因为内核驻留在受保护的地址空间上,不允许用户进程在内核地址空间上读写。所以,应用程序会以某种方式通知系统,告诉内核需要执行一个函数调用,这种通知机制是靠软中断来实现的,通过引发一个异常来促使系统切换到内核态去执行异常处理程序。此时的异常处理程序就是所谓的系统调用处理程序。
系统调用是属于操作系统内核的一部分,必须以某种方式提供给进程让它们去调用。CPU可以在不同的特权级别下运行,
而相应的操作系统也有不同的运行级别,用户态和内核态。运行在内核态的进程可以毫无限制的访问各种资源,
而在用户态下的用户进程的各种操作都有着限制,比如不能随意的访问内存、不能开闭中断以及切换运行的特权级别。
所以操作系统通过中断从用户态切换到内核态。
补充——中断是什么
中断控制是计算机发展中一种重要的技术。 最初它是为克服对I/O接口控制采用程序查询所带来的处理器效率低而产生的。
中断控制的主要优点是只有在I/O需要服务时才能得到处理器的响应,而不需要处理器不断地进行查询。
由此,最初的中断全部是对外部设备而言的,称为外部中断(或硬件中断)。
但随着计算机系统结构的不断改进以及应用技术的日益提高,中断的适用范围也随之扩大,出现了所谓的内部中断(或叫异常),
它是为解决机器运行时所出现的某些随机事件及编程方便而出现的。因而形成了一个完整的中断系统。
中断可分为两大类:异常和中断。
异常分为故障和陷阱,特点是既不使用中断控制器,也不能被屏蔽(异常实际上是CPU发出的中断信号)。
中断分为外部可屏蔽中断和外部非屏蔽中断,所有I/O设备产生的中断请求均引起屏蔽中断,而紧急事件(如硬件故障)引起的故障产生非屏蔽中断。
Intel x86系列微机共支持256中向量中断,Linux对256个向量的分配如下:
(1) 从0~31的向量对应异常和非屏蔽中断。
(2) 从32~47的向量分配给屏蔽中断。
(3) 从48~255的向量用来标识软中断。Linux只用了其中一个(128向量即0x80向量)用来实现系统调用。
注:Linux为什么只使用一个中断号来对应所有的系统调用,而不是一个中断号对应一个系统调用?
因为中断号是有限的,而系统调用又太多了。
Linux对系统调用的调用必须通过执行int $0x80汇编指令,这条指令会产生向量为128的编程异常。
中断有两个重要的属性,中断号和中断处理程序。中断号用来标识不同的中断,不同的中断具有不同的中断处理程序。在操作系统内核中维护着一个中断向量表,这个数组存储了所有中断处理程序的地址,而中断号就是相应中断在中断向量表中的偏移量。
在实地址模式中,CPU把内存中从0开始的1KB用来存储中断向量表。表中的每个表项占4个字节,
由两个字节的段地址和两个字节的偏移量组成,这样构成的地址便是相应的中断处理程序的入口地址。
但是,在保护模式下,由4字节的表项构成的中断向量表显然满足不了要求。这是因为:
<1>除了两个字节的段描述符,偏移量必须用4字节来表示;
<2>要有反映模式切换的信息。
因此,在保护模式下,中断向量表中的表项由8个字节组成,中断向量表也改叫做中断描述符表
IDT(Interrupt Descriptor Table)。其中的每个表项叫做一个门描述符(Gate Descriptor),
“门”的含义是当中断发生时必须先通过这些门,然后才能进人相应的处理程序。
Linux下系统调用原理
根据上文,我们知道Linux使用一个中断号来对应所有的系统调用,那么只有一个中断号,操作系统怎么知道是哪一个系统调用要被调用呢?
上文也提到过,系统调用拥有自己的系统调用号,系统调用表以及系统调用处理函数。一个调用号对应一个处理函数,通过处理函数和调用号在调用表中找到相应的系统调用。
在Linux中,EAX寄存器是负责传递系统调用号的。
以fork()为例,fork()的系统调用号为2,在执行int $0x80指令前,调用号会被存放在eax寄存器中,系统调用处理函数(中断处理函数)最终会通过系统调用号,调用正确的系统调用。
伪代码:
movl eax,2
int 0x80
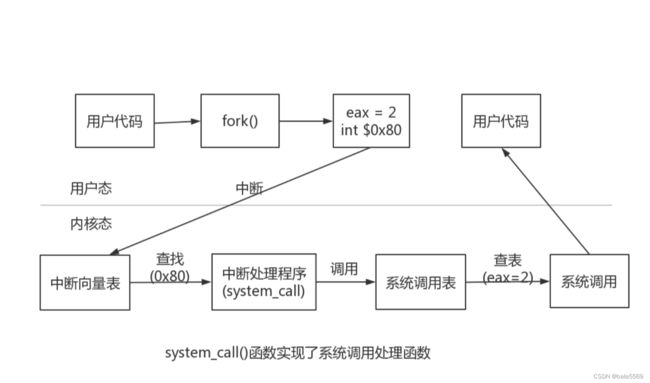
系统调用除了需要传递系统调用号以外,还是需要传递参数,并且具有返回值的,那么参数是怎么传递的呢?
对于参数传递,Linux也是通过寄存器完成的。Linux最多允许向系统调用传递6个参数,
分别依次由%ebx,%ecx,%edx,%esi,%edi和%ebp这个6个寄存器完成。
以调用exit(1)为例
伪代码:
movl eax,2
movl ebx,1
int 0x80
因为exit需要一个参数1,所以这里只需要使用ebx。这6个寄存器可能已经被使用,所以在传参前必须把当前寄存器的状态保存下来,待系统调用返回后再恢复。
Linux中,在用户态和内核态运行的进程使用的栈是不同的,分别叫做用户栈和内核栈, 两者各自负责相应特权级别状态下的函数调用。当进行系统调用时,进程不仅要从用户态切换到内核态,同时也要完成栈切换, 这样处于内核态的系统调用才能在内核栈上完成调用。系统调用返回时,还要切换回用户栈,继续完成用户态下的函数调用。
寄存器%esp(栈指针,指向栈顶)所在的内存空间叫做当前栈, 比如%esp在用户空间则当前栈就是用户栈,否则是内核栈。栈切换主要就是%esp在用户空间和内核空间间的来回赋值。 在Linux中,每个进程都有一个私有的内核栈,当从用户栈切换到内核栈时,需完成保存%esp以及相关寄存器的值(%ebx,%ecx…)并将%esp设置成内核栈的相应值。而从内核栈切换会用户栈时,需要恢复用户栈的%esp及相关寄存器的值以及保存内核栈的信息。
之前总是听说系统调用很费时,在学习了系统调用的原理后,我们应该也知道了其中的原因。
系统调用通过中断实现,需要从用户态切换到内核态,也就是要完成栈切换。
会使用寄存器传参,需要额外的保存和恢复的过程。