常见的窗口函数
常见的窗口函数
窗口函数基本概念
| 名称 | 参数 | 描述 |
|---|---|---|
| ROW_NUMBER() | 否 | 当前行在其分组内的序号.不管其排序结果中是否出现重复值.其排序结果都为:1,2.3.4.5. |
| DENSE_RANK() | 否 | 不间断的组内排序.使用这个函数时,可以出现1.1.2.2这种形式的分组。 |
| RAN() | 否 | 间断的组内排序。其排序结果可能出现如下结果:1.1.3.4.4.6 |
| PERCENT_RANK() | 否 | 累计百分比。该函数的计算结果为:小于该条记录值的所有记录的行数/该分组的总行数-1.所以该记录的返回值为[0,1]。 |
| CUME_DIST() | 否 | 累计分布值。即分组值小于等于当前值的行数与分组总行数的比值。取值范围为(0.1]。 |
| LAG() | lag(expr,[N,[detaut]]) | 从当前行开始往前取第N行,如果N缺失,默认为1。如果不存在前一行.则默认返回default。default默认值为NULL。 |
| LEAD() | lead(expr,[N,[defaut]]) | 从当前行开始往后取第N行。函数功能与lag()相反.其余与lag()相同。 |
| FIRST_VALUE() | frst_value(expr) | 返回分组内截止当前行的第一个值。 |
| LAST_VALUE() | last_value(expr) | 返回分组内截止当前行的最后一个值。 |
| NTH_VALUE() | nth_value(expr.N) | 返回分组内截止当前行的第N行。与first_value\last_value\nth_ value函数功能相似,只是返回分组内截止当前行的不同行号的数据。 |
| NTILE() | ntile(N) | 返回当前行在分组内的分桶号。在计算时要先将该分组内的所有数据划分成N个桶。之后返回每个记录所在的分桶号。返回范围从1到N。 |
注: ‘参数’列说明该函数是否可以加参数。“否”说明该函数的括号内不可以加参数。expr即可以代表字段,也可以代表在字段上的计算,比如sum(col)等。
将上述函数按照功能划分,可以把MySQL支持的窗口函数分为如下几类:
- 序号函数:
ROW_NUMBER()、RANK()、DENSE_RANK() - 分布函数:
PERCENT_RANK()、CUME_DIST() - 前后函数:
LAG()、LEAD() - 头尾函数:
FIRST_VALUE()、LAST_VALUE() - 其它函数:
NTH_VALUE()、NTILE()

数据准备
create table wf_example(
id smallint unsigned not null auto_increment primary key,
wind varchar(32),
val smallint);
insert into wf_example values
(null,'Window_A',1),
(null,'Window_A',2),
(null,'Window_A',2),
(null,'Window_A',3),
(null,'Window_A',3),
(null,'Window_A',3),
(null,'Window_B',100),
(null,'Window_B',200),
(null,'Window_B',300),
(null,'Window_B',400),
(null,'Window_B',500);
select * from wf_example;
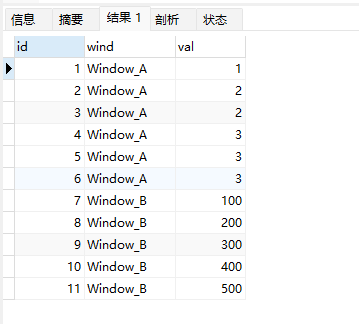
序号函数
row_number()
单纯的对每一组数据编号,进行顺序显示。(顺序排列)——1、2、3。
语法:
row_number() over window
没有参数,返回当前行在组内的位置编号,从1开始,order by子句会影响行的编号顺序,如果没有order by,那么行的编号是不确定的。另外,即使行完全相同,它们的编号也是不同的,这点和后面的 rank() 和 dense_rank() 不同。
select wind, val,
row_number() over w 组内编号
from wf_example
window w as (partition by wind);

上面示例中:
- 每一行都有唯一的编号,从1开始,即使数据完全相同,编号也不同。
rank()
排序每一组的某一字段, 同等级同序号前后不连续。(并列排序,跳过重复序号)——1、1、3,
语法:
rank() over window
没有参数,返回当前行在组内的排序,排序带间隙(排名数字不连续),在partition by 后面可以跟上order by 子句来指定按某列排序,示例中按照val值升序排列:
select wind,val,
rank() over (partition by wind order by val) 带间隙排序
from wf_example;
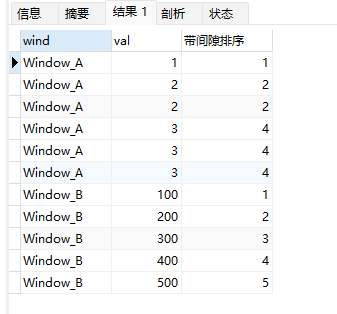
上面示例中:
order by val定义了按照 val 的值排序,注意相同的值,排序也相同,如果没有order by val子句,那么所有行的排序都是1。- Window_A中,由于存在两个2,因此下一个排序是4,排序存在间隙。
dense_rank()
排序每一组的某一字段, 同等级同序号前后也连续。(并列排序,不跳过重复序号)——1、1、2。
语法:
dense_rank() over window
没有参数,返回当前行在组内的排序,排序不带间隙(排名是连续的):
select wind, val,
rank() over (partition by wind order by val) 带间隙排序,
dense_rank() over (partition by wind order by val) 不带间隙排序
from wf_example;
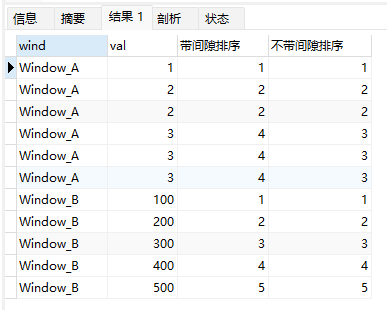
上面示例中:
- Window_A的组内排序中,虽然存在2个2,下一个排序依然是3,排序不存在间隙。
没有参数,返回当前行在组内的排序,排序不带间隙(排名是连续的):
分布函数
percent_rank()
计算分区或结果集中行的百分位数排名。
语法:
percent_rank() over window
百分比排序,返回当前行在组内的百分比位置,返回值范围为[0, 1],可以用 当前行排序/(行数-1) 计算得出,但与rank不同,这里排序是从0开始而不是从1(相当于rank-1),因此第1行的百分比位置是0%,相当于:(rank-1)/(rows-1)。
select wind,val,
rank() over (partition by wind order by val) 带间隙排序,
percent_rank() over (partition by wind order by val) 百分比排序
from wf_example;
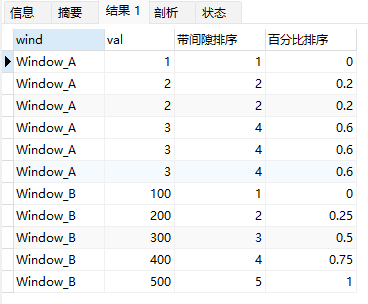
上面示例中:
- window_A中第1行rank为1,组内rows为6,代入(rank-1)/(rows-1)得到percent_rank为 (1-1)/(6-1),结果为0.
- Window_A中第3行rank为2(和第2行并列第2),组内rows为6,代入(rank-1)/(rows-1)得到percent_rank为 (2-1)/(6-1),结果为0.2。
- window_B中最后一行rank为5,rows为5,代入(rank-1)/(rows-1)得到percent_rank为 (5-1)/(5-1),结果为1.
cume_dist()
累积分布值<= 当前 rank 值的行数 / 分组内总行数,取值范围为 0~1。
语法:
cume_dist() over window
累积分布(cumulative distribution)。返回 “当前行之前” 与 “和当前行相等(包含当前行)” 的行数,占组内行数的百分比。
(当前行及之前行数 + 和当前行相等的行数)/组内数量,这个和rank类似,但是统计的是一个累积的比例,数据分布从0到1.
select wind,val,
rank() over w 行编号,
percent_rank() over w 百分比排序,
cume_dist() over w 累积比例
from wf_example
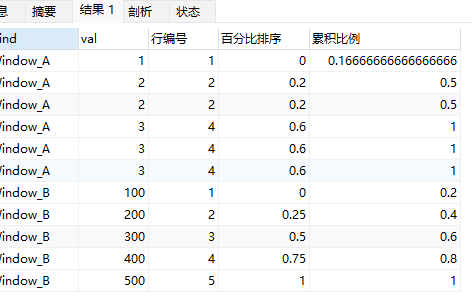
上面示例中:
- Window_A中,第1行为独立一行,前面没有行,也没有和自己相同的行,因此累积数量为1,累积比例为:1/6,即0.166666666
- Window_A中,第2行,累积数量为:前面的1行,自己第2行,和自己相等的第3行,因此累积数量为3,累积比例为:3/6,即0.5
- Window_A中,第4行,累积数量为:前面的3行,自己第4行,和自己相等的第5,6行,因此累积数量为6,累积比例为:6/6,即1。
- Window_B中,每一行都是独立的,不存在和自己相同的行,行编号就包含了自己及之前所有的行,因此每行的累积比例都是:行编号/组内行数
前后函数
lag(expr, n, default)
返回当前行前面 n 行的 expr 值。n 如果没有这样的行,则返回值为 default。如果缺少 n 或 default,则默认值分别为 1 或 NULL。
n 必须是非负整数。如果 n 为 0, expr 则为当前行的值。
从 MySQL 8.0.22 开始,n 不能 NULL。此外,它必须是1 到 2的63次方 的整数。
语法:
lag(expr [, N [, default]])
select wind,val,
lag(val*10) over w 当前行前面一个值,
lag(val*10,1,'不存在') over w 当前行前面一个值带默认值,
val-lag(val,2) over w 当前值与前两个值的差
from wf_example
window w as (partition by wind order by val);
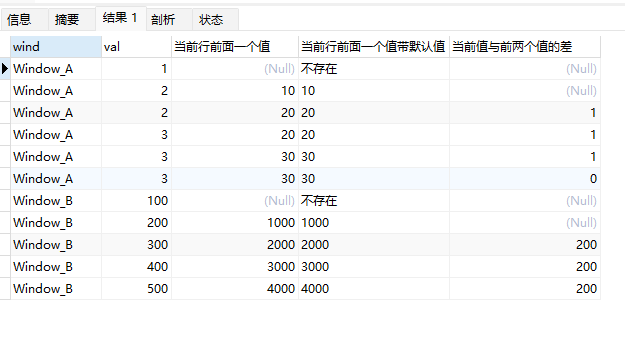
上面的示例中:
lag(val*10)返回前一行表达式val*10计算值(N参数省略,默认为1,default参数省略,默认为nulll,第一行没有前一行,返回null)lag(val*10,1,'不存在')返回前一行表达式val*10计算值(default为"不存在",因此第一行返回字符串"不存在")val-lag(val,2)计算当前行与前2行之间的差额
lead(expr, n, default)
- 返回当前行
后面 n 行的 expr 值。n 如果没有这样的行,则返回值为 default。如果缺少 n 或 default,则默认值分别为 1 或 NULL。 - n 必须是非负整数。如果 n 为 0, expr 则为当前行的值。
- 从 MySQL 8.0.22 开始,n 不能 NULL。此外,它必须是1 到 2的63次方 的整数。
语法:
lead(expr [N [, default]])
select wind,val,
lead(val*10) over w 当前行后面一个值的十倍,
lead(val*10,1,'不存在') over w 当前行后面一个值十倍带默认值,
val-lead(val,2) over w 当前行与后面第二个值的差
from wf_example
window w as (partition by wind order by val);
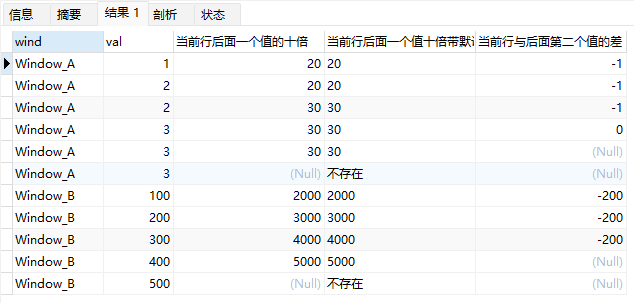
上面的示例中:
lead(val*10)返回后一行表达式val*10计算值(N参数省略,默认为1,default参数省略,默认为null,最后一行由于没有后一行,返回null)lag(val*10,1,'不存在')返回后一行表达式val*10计算值(default为"不存在",因此最后一行返回字符串"不存在")val-lead(val,2)计算当前行与后面第2行之间的差额
头尾函数
first_value(expr)
first_value 取分组内排序后,截止到当前行,第一个值。
语法:
first_value(expr) over window
select wind,val,
first_value(val) over (w order by val desc) 指定列倒序框架内第一个值,
first_value(val) over (w order by val asc) 指定列正序框架内第一个值
from wf_example
window w as (partition by wind);
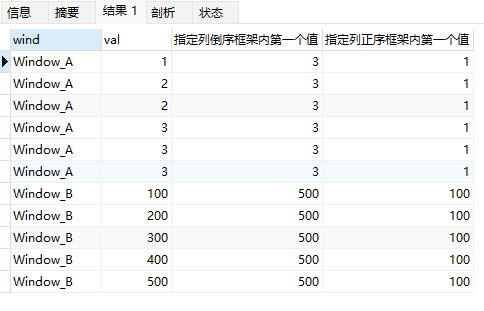
上面示例中:
- window_B中当 order by val desc 时,框架内第一个值是500,这里直接取列的值,你也可以替换为表达式。
- window_B中当 order by val asc 时,框架内第一个值是100。
last_value(expr)
last_value 取分组内排序后,截止到当前行,最后一个值。
语法:
last_value(expr) over window
select wind,val,
last_value(val*10) over w 框架内最后一个值的十倍
from wf_example
window w as (partition by wind order by val);
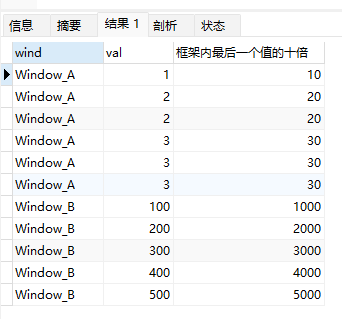
上面的示例中:
Window_B中,last_value(val*10) 返回的值每一行都不同,截止当前行的窗口内最后一个值(就是当前行自己),而不是整个组的最后一个值。
其他函数
nth_value(expr, n)
nth_value 函数返回第 n 行的 expr 值,没有则返回 null。
语法:
nth_value(expr, N) over window
select wind,val,
nth_value(val, 2) over w 窗口内第二个值,
nth_value(val, 3) over w 窗口内第三个值,
nth_value(val, 4) over w 窗口内第四个值
from wf_example
window w as (partition by wind order by val);

上面的示例中:
nth_value(val, 2)返回窗口内第二个值,第1行计算时由于窗口只有一行,没有第二个值,所以返回null。nth_value(val, 3)返回窗口内第三个值,注意window_A由于2,3行val是相等的,计算第二行时的窗口会包含第三行,而Window_B是独立的,第二行返回null。nth_value(val, 4)返回窗口内第四个值,window_A和Window_B都在第四行才取到值,前三行都是null。
ntile(n)
将组内成员再次分为N个小组(子分组/buckets),返回子分组的编号。
语法:
ntile(N) over window
select wind,val,
ntile(2) over w 将每个组再次分为2个组,
ntile(4) over w 将每个组再次分为4个组,
ntile(100) over w 将每个组再次分为100个组
from wf_example
window w as (partition by wind order by val);
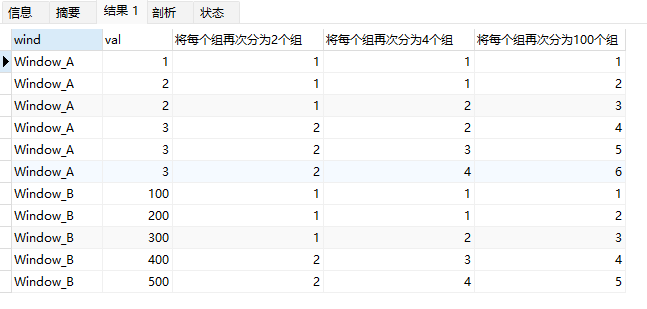
上面示例中:
ntile(2)将每个组再次分为2个组,并返回每一行所属子分组的编号ntile(100)当组的数量超过行数时,每一行都是一个独立子分组。