前端面试题(持续更新~~)
文章目录
- 一、基础
-
- 1、数组常用的方法
- 2、数组有哪几种循环方式?分别有什么作用?
- 3、字符串常用的方法
- 4、原型链
- 5、闭包
- 6、常见的继承
- 7、cookie 、localstorage 、 sessionstrorage区别
- 8、数组去重方法
- 9、http 的请求方式
- 10、数据类型的判断方法
- 11、cookie 和 session 的区别
- 二、JS
-
- 1、js 的执行机制
- 三、CSS
-
- 1、常见的布局方法
- 2、盒子模型
- 四、Vue
-
- 1、vue 双向数据绑定的原理
- 2、vue 的生命周期
- 3、v-if 和 v-show区别
- 4、computed 和 watch 的区别
- 5、对vuex的理解
- 五、ES
-
- 1、async await含义及作用
- 2、es6新特性
一、基础
1、数组常用的方法
1、concat() 方法用于合并两个或多个数组。此方法不会更改现有数组,而是返回一个新数组。
2、find() 方法返回数组中满足提供的测试函数的第一个元素的值。否则返回 undefined 。
语法: 数组名.find(function (item,index,arr) {})
item : 这个表示的是数组中的每一项
index : 这个表示的是每一项对应的索引
arr : 这个表示的是原数组
3、findIndex() 方法返回数组中满足提供的测试函数的第一个元素的索引。否则返回-1。
4、includes() 方法用来判断一个数组是否包含一个指定的值,根据情况,如果包含则返回 true, 否则返回 false。
5、indexOf() 方法返回在数组中可以找到一个给定元素的第一个索引,如果不存在,则返回-1。 (通常用它判断数组中有没有这个元素)。lastIndexOf 用法与其一致,区别:前者从左开始检查,后者从右开始检查。
语法一: 数组名.indexOf( 要查询的数据)
语法二: 数组名.indexOf( 要查询的数据, 开始索引)
6、join() 方法将一个数组(或一个类数组对象)的所有元素连接成一个字符串并返回这个字符串。 如果数组只有一个项目,那么将返回该项目而不使用分隔符。
语法: 数组名.join(’ 连接符’)
7、push() 方法将一个或多个元素添加到数组的末尾,并返回该数组的新长度。
语法: 数组名.push( 数据)
8、pop() 方法从数组中删除最后一个元素,并返回该元素的值。此方法更改数组的长度。
9、shift() 方法从数组中删除第一个元素,并返回该元素的值。此方法更改数组的长度。
10、unshift() 方法将一个或多个元素添加到数组的开头,并返回该数组的新长度(该方法修改原有数组)。
11、splice() 方法通过删除或替换现有元素或者原地添加新的元素来修改数组,并以数组形式返回被修改的内 容。此方法会改变原数组。 由被删除的元素组成的一个数组。如果只删除了一个元素,则返回只包含一个元素的数组。如果没有删 除元素,则返回空数组。
截取数组,返回截取出来的数据,语法一:数组名.splice(开始索引,多少个)
删除并插入数据,返回截取出来的数据,语法二: 数组名.splice(开始索引,多少个,你要插入的数据)
12、slice() ,截取数组的一部分数据
语法: 数组名.slice( 开始索引, 结束索引)
13、reverse() 方法将数组中元素的位置颠倒,并返回该数组。该方法会改变原数组。
14、sort() 方法用原地算法对数组的元素进行排序,并返回数组。默认排序顺序是在将元素转换为字 符串,然后比较它们的 UTF-16 代码单元值序列时构建的。
语法一: 数组名.sort()会排序 会按照位排序
语法二: 数组名.sort(function (a,b) {return a-b}) 会正序排列
语法三: 数组名.sort(function (a,b) {return b-a}) 会倒序排列
ES6新增的方法
1、forEach() 用来循环遍历的 for
语法: 数组名.forEach(function (item,index,arr) {})
2、map()映射数组的
语法: 数组名.map(function (item,index,arr) {})
3、filter()过滤数组
语法: 数组名.filter(function (item,index,arr) {})
4、every()判断数组是不是满足所有条件
语法: 数组名.every(function (item,index,arr) {})
5、some()数组中有没有满足条件的
语法: 数组名.some(function (item,index,arr) {})
6、reduce()叠加后的效果
语法: 数组名.reduce(function (prev,item,index,arr) {},初始值)
prev :一开始就是初始值 当第一次有了结果以后;这个值就是第一次的结果
2、数组有哪几种循环方式?分别有什么作用?
1、every() 方法测试一个数组内的所有元素是否都能通过某个指定函数的测试。它返回一个布尔 值。
2、filter() 方法创建一个新数组, 其包含通过所提供函数实现的测试的所有元素。
注意: filter() 不会对空数组进行检测。
注意: filter() 不会改变原始数组。
3、forEach() 方法对数组的每个元素执行一次提供的函数。
4、some() 方法测试是否至少有一个元素可以通过被提供的函数方法。该方法返回一个 Boolean 类型 的值。
3、字符串常用的方法
1、获取字符串长度
2、获取字符串指定位置的值
1】charAt() 方法从一个字符串中返回指定位置(索引)的字符。
2】charCodeAt()方法获取的是指定位置字符的Unicode值。
3、检索字符串是否包含特定序列
3】indexOf(),查找某个字符,有则返回第一次匹配到的位置,否则返回-1。
语法:string.indexOf(searchvalue,fromindex)
4】lastIndexOf(),查找某个字符,有则返回最后一次匹配到的位置,否则返回-1。
5】includes() 方法用于判断一个字符串是否包含在另一个字符串中,根据情况返回 true 或 false。
6】startsWith():该方法用于检测字符串是否以指定的子字符串开始。如果是以指定的子字符串开头返回 true,否则 false。
7】endsWith():该方法用来判断当前字符串是否是以指定的子字符串结尾。如果传入的子字符串在搜索字符串的末尾则返回 true,否则将返回 false。
4、连接多个字符串
8】concat() 方法将一个或多个字符串与原字符串连接合并,形成一个新的字符串并返回。
5、字符串分割成数组
9】split() 方法用于把一个字符串分割成字符串数组。该方法不会改变原始字符串。
语法:string.split(separator,limit)
separator:必需。字符串或正则表达式,从该参数指定的地方分割 string。
limit:可选。该参数可指定返回的数组的最大长度。如果设置了该参数,返回的子串不会多于这个参数指定的数组。如果没有设置该参数,整个字符串都会被分割,不考虑它的长度。
如果把空字符串用作 separator,那么字符串中的每个字符之间都会被分割。
其实在将字符串分割成数组时,可以同时拆分多个分割符,使用正则表达式即可实现。
6、 截取字符串
substr()、substring()和 slice() 方法都可以用来截取字符串。
10】slice() 方法提取某个字符串的一部分,并返回一个新的字符串,且不会改动原字符串。
语法:string.slice(start,end)
start:必须。 要截取的片断的起始下标,第一个字符位置为 0。如果为负数,则从尾部开始截取。
end:可选。 要截取的片段结尾的下标。若未指定此参数,则要提取的子串包括 start 到原字符串结尾的字符串。如果该参数是负数,那么它规定的是从字符串的尾部开始算起的位置。
11】 substr() 方法返回一个字符串中从指定位置开始到指定字符数的字符。
语法:string.substr(start,length)
start 必需。要抽取的子串的起始下标。必须是数值。如果是负数,那么该参数声明从字符串的尾部开始算起的位置。也就是说,-1 指字符串中最后一个字符,-2 指倒数第二个字符,以此类推。
length:可选。子串中的字符数。必须是数值。如果省略了该参数,那么返回从 stringObject 的开始位置到结尾的字串。
12】substring() 方法用于提取字符串中介于两个指定下标之间的字符。
语法:string.substring(from, to)
7】字符串大小写转换
13】toLowerCase():该方法用于把字符串转换为小写。
14】toUpperCase():该方法用于把字符串转换为大写。
8、字符串模式匹配
15】replace()方法用于在字符串中用一些字符替换另一些字符,或替换一个与正则表达式匹配的子串。
语法:string.replace(searchvalue, newvalue)
16】match():该方法用于在字符串内检索指定的值,或找到一个或多个正则表达式的匹配。该方法类似 indexOf() 和 lastIndexOf(),但是它返回指定的值,而不是字符串的位置。
17】search()方法用于检索字符串中指定的子字符串,或检索与正则表达式相匹配的子字符串。
9、移除字符串收尾空白符
18】trim() 方法会从一个字符串的两端删除空白字符。
trimStart()、trimEnd()与trim()一致
10、重复一个字符串
19】repeat(n) 方法返回一个新字符串,表示将原字符串重复n次。
11、补齐字符串长度
20】padStart()和padEnd()方法用于补齐字符串的长度。如果某个字符串不够指定长度,会在头部或尾部补全。
(1)padStart()
padStart()用于头部补全。该方法有两个参数,其中第一个参数是一个数字,表示字符串补齐之后的长度;第二个参数是用来补全的字符串。
如果原字符串的长度,等于或大于指定的最小长度,则返回原字符串。
如果用来补全的字符串与原字符串,两者的长度之和超过了指定的最小长度,则会截去超出位数的补全字符串。
如果省略第二个参数,默认使用空格补全长度。
padStart()的常见用途是为数值补全指定位数,如将一位数字补齐为三位数字,1——>001
(2)padEnd()
padEnd()用于尾部补全。该方法也是接收两个参数,第一个参数是字符串补全生效的最大长度,第二个参数是用来补全的字符串。
4、原型链
每一个实例对象上有一个proto 属性,指向的构造函数的原型对象,构造函数的原型 对象也是一个对象, 也有 proto 属性,这样一层一层往上找的过程就形成了原型链。
5、闭包
1、定义
闭包(closure)指有权访问另一个函数作用域中变量的函数。简单理解就是 ,一个作用 域可以访问另外一个函数内部的局部变量。
2、闭包函数
function fn(){
var num = 10
function fun(){
console.log("-----------",num)
}
return fun
}
var f = fn()
f()
3、作用
延长变量作用域、在函数的外部可以访问函数内部的局部变量,容易造成内层泄露,因为闭包中 的局部变量永远不会被回收。
6、常见的继承
1、原型链继承
特点:
1、实例可继承的属性有:实例的构造函数的属性,父类构造函数属性,父类原型的属性。(新 实例不会继承父类实例的属性!
缺点:
1、新实例无法向父类构造函数传参。
2、继承单一。
3、所有新实例都会共享父类实例的属性。(原型上的属性是共享的,一个实例修改了原型属 性,另一个实例的原 型属性也会被修改!)
2、借用构造函数继承
重点:
用 .call()和.apply() 将父类构造函数引入子类函数(在子类函数中做了父类函数的自执行(复 制))
特点:
1、只继承了父类构造函数的属性,没有继承父类原型的属性。
2、解决了原型链继承缺点 1、2、3。
3、可以继承多个构造函数属性(call 多个)。
4、在子实例中可向父实例传参。
缺点:
1、只能继承父类构造函数的属性。
2、无法实现构造函数的复用。(每次用每次都要重新调用)
3、每个新实例都有父类构造函数的副本,臃肿。
3、组合继承(组合原型链继承和借用构造函数继承)(常用)
重点:
结合了两种模式的优点,传参和复用
特点:
1、可以继承父类原型上的属性,可以传参,可复用。
2、每个新实例引入的构造函数属性是私有的。
缺点:
调用了两次父类构造函数(耗内存),子类的构造函数会代替原型上的那个父类构造函 数。
4、原型式继承
重点:
用一个函数包装一个对象,然后返回这个函数的调用,这个函数就变成了个可以随意增添属性的 实例或对象。object.create()就是这个原理。
特点:
类似于复制一个对象,用函数来包装。
缺点:
1、所有实例都会继承原型上的属性。
2、无法实现复用。(新实例属性都是后面添加的)
5、class 类实现继承
通过 extends 和 super 实现继承
6、寄生式继承
重点:
就是给原型式继承外面套了个壳子。
优点:
没有创建自定义类型,因为只是套了个壳子返回对象(这个),这个函数顺理成章就成 了创建的新对象。
缺点:
没用到原型,无法复用。
7、cookie 、localstorage 、 sessionstrorage区别
1、与服务器交互:
cookie 是网站为了标示用户身份而储存在用户本地终端上的数据(通常经过加密)
cookie 始终会在同源 http 请求头中携带(即使不需要),在浏览器和服务器间来回传递
sessionStorage 和 localStorage 不会自动把数据发给服务器,仅在本地保存
2、存储大小:
cookie 数据根据不同浏览器限制,大小一般不能超过 4k
sessionStorage 和 localStorage 虽然也有存储大小的限制,但比 cookie 大得多,可以达到 5M 或更大
3、有期时间:
localStorage 存储持久数据,浏览器关闭后数据不丢失除非主动删除数据
sessionStorage 数据在当前浏览器窗口关闭后自动删除
cookie 设置的 cookie 过期时间之前一直有效,与浏览器是否关闭无关
8、数组去重方法
第一种,利用filter()
const array = ['a1','b1','c1',9,'e1','a1','b1',true,false,undefined,12,9,undefined,null,null,NaN,NaN,0,{},{},0];
function unique(arr){
return arr.filter(function(item,index,arr){
return arr.indexOf(item,0) === index
})
}
console.log("+++++++",unique(array))
结果:['a1', 'b1', 'c1', 9, 'e1', true, false, undefined, 12, null, 0, {}, {}]
第二种,利用ES6 Set去重
function unique(arr){
return Array.from(new Set(arr))
}
console.log("+++++++",unique(array))
结果: ['a1', 'b1', 'c1', 9, 'e1', true, false, undefined, 12, null, NaN, 0, {}, {}]
第三种,利用for嵌套for,然后splice去重(ES5常用)
function unique(arr){
for(var i = 0; i < arr.length; i++){
for(var j = i + 1; j < arr.length; j++){
if(arr[i] == arr[j]) {
arr.splice(j,1);
j--;
}
}
}
return arr
}
console.log("+++++++",unique(array))
结果:['a1', 'b1', 'c1', 9, 'e1', true, false, undefined, 12, NaN, NaN, {}, {}]
9、http 的请求方式
get、post、put、delete 等
10、数据类型的判断方法
判断数据类型的方法一般可以通过:typeof、instanceof、constructor、toString四种常用方法
| 类型 | typeof | instanceof | constructor | Object.prototype.toString.call |
|---|---|---|---|---|
| 优点 | 使用简单 | 能检测出引用 类型 | 基本能检测所有 的类型(除了 null 和 undefined) | constructor 易被 修改,也不能跨 iframe |
| 缺点 | 只能检测 出基本类 型(除了 null) | 不能检测出基 本类型,且不 能跨 iframe | constructor 易被 修改,也不能跨 iframe | IE6 下,undefined 和 null 均为 Object |
11、cookie 和 session 的区别
1、cookie 数据存放在客户的浏览器上,session 数据放在服务器上。
2、cookie 不是很安全,别人可以分析存放在本地的 cookie 并进行 cookie 欺骗,考虑到安全应当使用 session。
3、session 会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,考虑到减轻服务器性能方面,应当使用 cookie 。
4、单个 cookie 保存的数据不能超过 4K,很多浏览器都限制一个站点最多保存 20 个 cookie。
5、所以个人建议:将登陆信息等重要信息存放为 session ;其他信息如果需要保留,可以放在 cookie 中。
二、JS
1、js 的执行机制
js 是一个单线程、异步、非阻塞 I/O 模型、 event loop 事件循环的执行机制,所有任务可以分成两种,一种是同步任务(synchronous),另一种是异步任务(asynchronous)。
同步任务指的是,在主线程上排队执行的任务,只有前一个任务执行完毕,才能执行后一个任务。
异步任务指的是,不进入主线程、而进入"任务队列"(task queue)的任务,只有"任务队列"通知主线程, 某个异步任务可以执行了,该任务才会进入主线程执行。
三、CSS
1、常见的布局方法
页面布局常用的方法有浮动、定位、flex、grid 网格布局、栅格系统布局
1、浮动: 优点:兼容性好。 缺点:浮动会脱离标准文档流,因此要清除浮动。我们解决好这个问题即可。
2、绝对定位 优点:快捷。 缺点:导致子元素也脱离了标准文档流,可实用性差。
3、flex 布局(CSS3 中出现的) 优点:解决上面两个方法的不足,flex 布局比较完美。移动端基本用 flex 布局。
4、网格布局(grid) CSS3 中引入的布局,很好用。代码量简化了很多。
5、栅格系统布局 优点:可以适用于多端设备。
2、盒子模型
在标准盒子模型中,width 和 height 指的是内容区域的宽度和高度。
增加内边距、边框和外边距不会 影响内容区域的尺寸,但是会增加元素框的总尺寸。
IE 盒子模型中,width 和 height 指的是内容区域+border+padding的宽度和高度。
四、Vue
1、vue 双向数据绑定的原理
vue.js 是采用数据劫持结合发布者-订阅者模式的方式,通过Object.defineProperty()来劫持各个属性的setter,getter,在数据变动时发布消息给订阅者,触发相应的监听回调。
具体步骤
第一步: 需要 observe 的数据对象进行递归遍历,包括子属性对象的属性,都加上 setter 和getter 这样的话,给这个对象的某个值赋值,就会触发 setter,那么就能监听到了数据变化。
第二步: compile 解析模板指令,将模板中的变量替换成数据,然后初始化渲染页面视图,并将每个指令对应的节点绑定更新函数,添加监听数据的订阅者,一旦数据有变动,收到通知,更新视图。
第三步: Watcher 订阅者是 Observer 和 Compile 之间通信的桥梁,主要做的事情是:
1、在自身实例化时往属性订阅器(dep)里面添加自己
2、自身必须有一个 update() 方法
3、待属性变动 dep.notice() 通知时,能调用自身的 update() 方法,并触发 Compile 中绑定的回调,则功成身退。
第四步:MVVM 作为数据绑定的入口,整合 Observer、Compile 和 Watcher 三者,通过 Observer 来监听自己的 model 数据变化,通过 Compile 来解析编译模板指令,最终利用 Watcher 搭起 Observer 和 Compile 之间的通信桥梁,达到数据变化 -> 视图更新;视图交互变化(input) -> 数据 model 变更的双向绑定效果。
2、vue 的生命周期
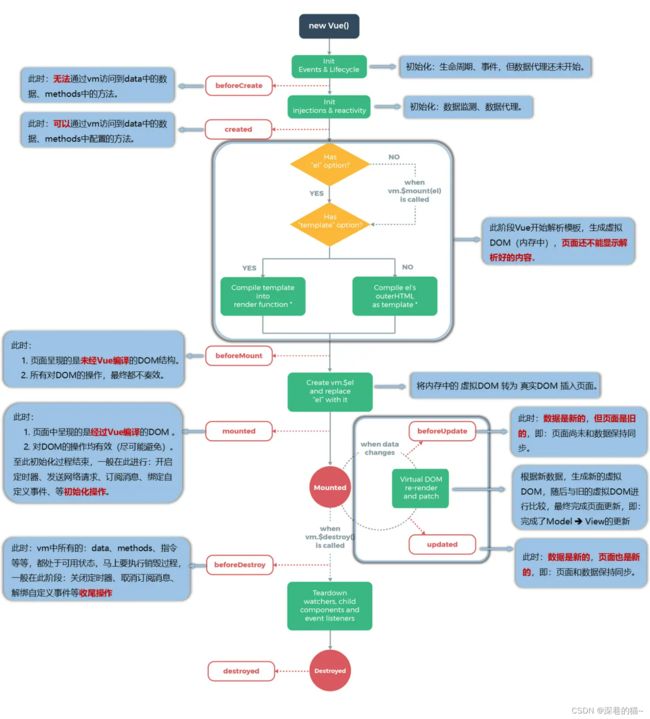
vue 实例从创建到销毁的过程就是生命周期。也就是从开始创建、初始化数据、编译模板、挂在 dom -> 渲染、更新 -> 渲染、准备销毁、销毁等一系列过程,vue 的生命周期常见的主要分为4 大阶段 ,8 大钩子函数,另外三个生命周期函数不常用:
keep-alive 主要用于保留组件状态或避免重新渲染。
activated只有在 keep-alive 组件激活时调用。
deactivated只有在 keep-alive 组件停用时调用。
errorCapured 当捕获一个来自子孙组件的错误时被调用。此钩子会收到三个参数:错误对象、发生错误的组件实例以及一个包含错误来源信息的字符串。此钩子可以返回 false, 以阻止该错误继续向上传播。
一、创建前 / 后,在beforeCreate生命周期函数执行的时候,data 和 method 还没有初始化;在created 生命周期函数执行的时候,data 和 method 已经初始化完成。
二、渲染前/后,在beforeMount 生命周期函数执行的时候,已经编译好了模版字符串、但还没有真正渲染到页面中去;在mounted 生命周期函数执行的时候,已经渲染完,可以看到页面。
三、数据更新前/后,在beforeUpdate生命周期函数执行的时候,已经可以拿到最新的数据,但还没渲染到视图中去。在updated生命周期函数执行的时候,已经把更新后的数据渲染到视图中去了。
四、销毁前/后,在beforeDestroy 生命周期函数执行的时候,实例进入准备销毁的阶段、此时 data 、methods 、指令等还是可用状态;在destroyed生命周期函数执行的时候,实例已经完成销毁、此时 data 、methods 、指令等都不可用。
3、v-if 和 v-show区别
v-if,确保在切换过程中条件块内的事件监听器和子组件适当地被销毁和重建, 操作的实际上是 dom 元素的创建或销毁。
v-show,基于 CSS 进行切换, 它操作的是display:none/block属性。
一般来说, v-if 有更高的切换开销,而 v-show 有更高的初始渲染开销。因此,如果需要非常频繁地切换,则使用 v-show 较好; 如果在运行时条件很少改变,则使用 v-if 较好。
4、computed 和 watch 的区别
computed计算属性就是为了简化 template 里面模版字符串的计算复杂度、防止模版太过冗余。
它具有 缓存特性 computed 用来监控自己定义的变量,该变量不在 data 里面声明,直接在 computed 里面定义,然后就 可以在页面上进行双向数据绑定展示出结果或者用作其他处理;
watch主要用于监控 vue 实例的变化,它监控的变量当然必须在 data 里面声明才可以,它可以监控一个 变量,也可以是一个对象,一般用于监控路由、input 输入框的值特殊处理等等,它比较适合的场景是 一个数据影响多个数据,它不具有缓存性
watch:监测的是属性值, 只要属性值发生变化,其都会触发执行回调函数来执行一系列操作。
computed:监测的是依赖值,依赖值不变的情况下其会直接读取缓存进行复用,变化的情况下才 会重新计算。
除此之外,有点很重要的区别是:计算属性不能执行异步任务,计算属性必须同步执行。也就是说计算 属性不能向服务器请求或者执行异步任务。如果遇到异步任务,就交给侦听属性。watch 也可以检测 computed 属性。
5、对vuex的理解
1、首先 vuex 的出现是为了解决 web 组件化开发的过程中,各组件之间传值的复杂和混乱的问题
2、将我们在多个组件中需要共享的数据放到 store 中,
3、要获取或格式化数据需要使用 getters,
4、改变 store 中的数据,使用 mutation,但是只能包含同步的操作,在具体组件里面调用的方式this.$store.commit('xxxx')
5、Action 也是改变 store 中的数据,不过是提交的 mutation,并且可以包含异步操作,在组件中的调 用方式this.$store.dispatch('xxx'); 在 actions 里面使用的 commit(‘调用 mutation’)
五、ES
1、async await含义及作用
async await 是es7里面的新语法、它的作用就是 async 用于申明一个 function 是异步的,而 await 用 于等待一个异步方法执行完成。它可以很好的替代promise 中的 then。
async 函数返回一个 Promise 对象,可以使用 then 方法添加回调函数。当函数执行的时候,一旦遇 到 await 就会先返回,等到异步操作完成,再接着执行函数体内后面的语句。
2、es6新特性
1、新增了let、 const,let 和 const具有块级作用域,不存在变量提升的问题。
2、新增了箭头函数,简化了定义函数的写法,同时 可以巧用箭头函数的 this、(注意箭头函数本身没有 this,它的 this 取决于外部的环境)。
3、新增了promise 解决了回调地域的问题。
4、新增了模块化、利用 import 、export 来实现导入、导出。
5、新增了结构赋值, ES6 允许按照一定模式,从数组和对象中提取值,对变量进行赋值,这被称为解构 (Destructuring)。
6、新增了class 类的概念,它类似于对象。
1、什么是 MVVM、MVC模型?
MVC: MVC 即 model-view-controller(模型-视图-控制器)是项目的一种分层架构思想,它把复杂的业务逻辑,
抽离为职能单一的小模块,每个模块看似相互独立,其实又各自有相互依赖关系。它的好处是:
保证了模块的智能单一性,方便程序的开发、维护、耦合度低。
MVVM:MVVM 即 Model-View-ViewModel,(模型-视图-控制器)它是一种双向数据绑定的模式, 用 viewModel 来建立起 model 数据层和 view 视图层的连接,数据改变会影响视图,视图改变会影响数据
参考:here