python 字典集合散列表原理
这一节笼统地描述了 Python 如何用散列表来实现 dict 类型,有些细节只是一笔带过。但是总体来说描述是准确的。
散列表其实是一个稀疏数组(总是有空白元素的数组称为稀疏数组)。在一般的数据结构教材中,散列表里的单元通常叫作表元(bucket)。在 dict 的散列表当中,每个键值对都占用一个表元,每个表元都有两个部分,一个是对键的引用,另一个是对值的引用。因为所有表元的大小一致,所以可以通过偏移量来读取某个表元。
因为 Python 会设法保证大概还有三分之一的表元是空的,所以在快要达到这个阈值的时候,原有的散列表会被复制到一个更大的空间里面。
如果要把一个对象放入散列表,那么首先要计算这个元素键的散列值。Python 中可以用hash() 方法来做这件事情,接下来会介绍这一点。
散列值和相等性
内置的 hash() 方法可以用于所有的内置类型对象。如果是自定义对象调用 hash() 的话,实际上运行的是自定义的 __hash__。如果两个对象在比较的时候是相等的,那它们的散列值必须相等,否则散列表就不能正常运行了。例如,如果 1 == 1.0 为真,那么 hash(1) == hash(1.0) 也必须为真,但其实这两个数字(整型和浮点)的内部结构是完全不一样的。
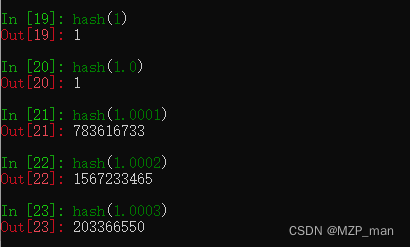
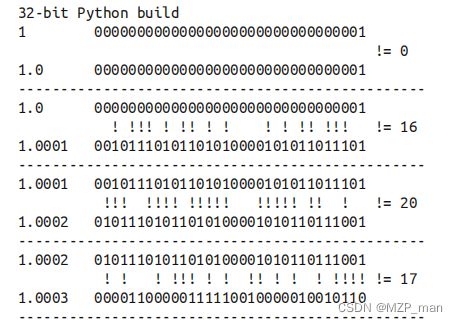
为了让散列值能够胜任散列表索引这一角色,它们必须在索引空间中尽量分散开来。这意味着在最理想的状况下,越是相似但不相等的对象,它们散列值的差别应该越大。下面示例是一段代码输出,这段代码被用来比较散列值的二进制表达的不同。注意其中 1 和1.0 的散列值是相同的,而 1.0001、1.0002 和 1.0003 的散列值则非常不同。
tips:
从 Python 3.3 开始,str、bytes 和 datetime 对象的散列值计算过程中多了随机的“加盐”这一步。所加盐值是 Python 进程内的一个常量,但是每次启动Python 解释器都会生成一个不同的盐值。随机盐值的加入是为了防止 DOS 攻击而采取的一种安全措施。在 __hash__ 特殊方法的文档(https://docs.python.org/3/reference/datamodel.html#object.__hash__) 里有相关的详细信息。
了解对象散列值相关的基本概念之后,我们可以深入到散列表工作原理背后的算法了。
散列表算法
为了获取 my_dict[search_key] 背后的值,Python 首先会调用 hash(search_key) 来计算search_key 的散列值,把这个值最低的几位数字当作偏移量,在散列表里查找表元(具体取几位,得看当前散列表的大小)。若找到的表元是空的,则抛出 KeyError 异常。若不是空的,则表元里会有一对 found_key:found_value。这时候 Python 会检验 search_key == found_key 是否为真,如果它们相等的话,就会返回 found_value。
如果 search_key 和 found_key 不匹配的话,这种情况称为散列冲突。发生这种情况是因为,散列表所做的其实是把随机的元素映射到只有几位的数字上,而散列表本身的索引又只依赖于这个数字的一部分。为了解决散列冲突,算法会在散列值中另外再取几位,然后用特殊的方法处理一下,把新得到的数字再当作索引来寻找表元。若这次找到的表元是空的,则同样抛出 KeyError;若非空,或者键匹配,则返回这个值;或者又发现了散列冲突,则重复以上的步骤。下图展示了这个算法的示意图。
图1:从字典中取值的算法流程图;给定一个键,这个算法要么返回一个值,要么抛出 KeyError 异常

添加新元素和更新现有键值的操作几乎跟上面一样。只不过对于前者,在发现空表元的时候会放入一个新元素;对于后者,在找到相对应的表元后,原表里的值对象会被替换成新值。
另外在插入新值时,Python 可能会按照散列表的拥挤程度来决定是否要重新分配内存为它扩容。如果增加了散列表的大小,那散列值所占的位数和用作索引的位数都会随之增加,这样做的目的是为了减少发生散列冲突的概率。
表面上看,这个算法似乎很费事,而实际上就算 dict 里有数百万个元素,多数的搜索过程中并不会有冲突发生,平均下来每次搜索可能会有一到两次冲突。在正常情况下,就算是最不走运的键所遇到的冲突的次数用一只手也能数过来。
了解 dict 的工作原理能让我们知道它的所长和所短,以及从它衍生而来的数据类型的优缺点。下面就来看看 dict 这些特点背后的原因。
dict的实现及其导致的结果
下面的内容会讨论使用散列表给 dict 带来的优势和限制都有哪些
1. 键必须是可散列的
一个可散列的对象必须满足以下要求。
(1) 支持 hash() 函数,并且通过 __hash__() 方法所得到的散列值是不变的。
(2) 支持通过 __eq__() 方法来检测相等性。
(3) 若 a == b 为真,则 hash(a) == hash(b) 也为真。
所有由用户自定义的对象默认都是可散列的,因为它们的散列值由 id() 来获取,而且它们都是不相等的。
tips:
如果你实现了一个类的 __eq__ 方法,并且希望它是可散列的,那么它一定要有个恰当的 __hash__ 方法,保证在 a == b 为真的情况下 hash(a) == hash(b)也必定为真。否则就会破坏恒定的散列表算法,导致由这些对象所组成的字典和集合完全失去可靠性,这个后果是非常可怕的。另一方面,如果一个含有自定义的 __eq__ 依赖的类处于可变的状态,那就不要在这个类中实现__hash__ 方法,因为它的实例是不可散列的。
2. 字典在内存上的开销巨大
由于字典使用了散列表,而散列表又必须是稀疏的,这导致它在空间上的效率低下。举例而言,如果你需要存放数量巨大的记录,那么放在由元组或是具名元组构成的列表中会是比较好的选择;最好不要根据 JSON 的风格,用由字典组成的列表来存放这些记录。用元组取代字典就能节省空间的原因有两个:其一是避免了散列表所耗费的空间,其二是无需把记录中字段的名字在每个元素里都存一遍。
在用户自定义的类型中,__slots__ 属性可以改变实例属性的存储方式,由 dict 变成tuple,相关细节以后会说。
记住我们现在讨论的是空间优化。如果你手头有几百万个对象,而你的机器有几个 GB 的内存,那么空间的优化工作可以等到真正需要的时候再开始计划,因为优化往往是可维护性的对立面。
3. 键查询很快
dict 的实现是典型的空间换时间:字典类型有着巨大的内存开销,但它们提供了无视数据量大小的快速访问——只要字典能被装在内存里。如果把字典的大小从1000 个元素增加到 10 000 000 个,查询时间也不过是原来的 2.8 倍,从 0.000163 秒增加到了 0.00456 秒。这意味着在一个有 1000 万个元素的字典里,每秒能进行 200 万个键查询。
4. 键的次序取决于添加顺序
当往 dict 里添加新键而又发生散列冲突的时候,新键可能会被安排存放到另一个位置。于是下面这种情况就会发生:由 dict([key1, value1), (key2, value2)] 和 dict([key2, value2], [key1, value1]) 得到的两个字典,在进行比较的时候,它们是相等的;但是如果在 key1 和 key2 被添加到字典里的过程中有冲突发生的话,这两个键出现在字典里的顺序是不一样的。
示例展示了这个现象。这个示例用同样的数据创建了 3 个字典,唯一的区别就是数据出现的顺序不一样。可以看到,虽然键的次序是乱的,这 3 个字典仍然被视作相等的。
# -*- coding: utf-8 -*-
DIAL_CODES = [
(86, 'China'),
(91, 'India'),
(1, 'United States'),
(62, 'Indonesia'),
(55, 'Brazil'),
(92, 'Pakistan'),
(880, 'Bangladesh'),
(234, 'Nigeria'),
(7, 'Russia'),
(81, 'Japan'),
]
d1 = dict(DIAL_CODES) # 创建 d1 的时候,数据元组的顺序是按照国家的人口排名来决定的。
print('d1:', d1.keys())
# d1: dict_keys([86, 91, 1, 62, 55, 92, 880, 234, 7, 81])
d2 = dict(sorted(DIAL_CODES)) # 创建 d2 的时候,数据元组的顺序是按照国家的电话区号来决定的
print('d2:', d2.keys())
# d2: dict_keys([1, 7, 55, 62, 81, 86, 91, 92, 234, 880])
d3 = dict(sorted(DIAL_CODES, key=lambda x: x[1])) # 创建 d3 的时候,数据元组的顺序是按照国家名字的英文拼写来决定的
print('d3:', d3.keys())
# d3: dict_keys([880, 55, 86, 91, 62, 81, 234, 92, 7, 1])
print(d1 == d2 and d2 == d3)
# True
5. 往字典里添加新键可能会改变已有键的顺序
无论何时往字典里添加新的键,Python 解释器都可能做出为字典扩容的决定。扩容导致的结果就是要新建一个更大的散列表,并把字典里已有的元素添加到新表里。这个过程中可能会发生新的散列冲突,导致新散列表中键的次序变化。要注意的是,上面提到的这些变化是否会发生以及如何发生,都依赖于字典背后的具体实现,因此你不能很自信地说自己知道背后发生了什么。如果你在迭代一个字典的所有键的过程中同时对字典进行修改,那么这个循环很有可能会跳过一些键——甚至是跳过那些字典中已经有的键。
由此可知,不要对字典同时进行迭代和修改。如果想扫描并修改一个字典,最好分成两步来进行:首先对字典迭代,以得出需要添加的内容,把这些内容放在一个新字典里;迭代结束之后再对原有字典进行更新。
tips:
在 Python 3 中,.keys()、.items() 和 .values() 方法返回的都是字典视图。也就是说,这些方法返回的值更像集合,而不是像 Python 2 那样返回列表。视图还有动态的特性,它们可以实时反馈字典的变化。
set的实现以及导致的结果
set 和 frozenset 的实现也依赖散列表,但在它们的散列表里存放的只有元素的引用(就像在字典里只存放键而没有相应的值)。在 set 加入到 Python 之前,我们都是把字典加上无意义的值当作集合来用的。
在 上面所提到的字典和散列表的几个特点,对集合来说几乎都是适用的。为了避免太多重复的内容,这些特点总结如下。
• 集合里的元素必须是可散列的。
• 集合很消耗内存。
• 可以很高效地判断元素是否存在于某个集合。
• 元素的次序取决于被添加到集合里的次序。
• 往集合里添加元素,可能会改变集合里已有元素的次序。