MIT 6.824 分布式系统 lab1 MapReduce 遇到死锁问题
记录学习6.824的lab1遇到的坑(死锁了)
代码逻辑借鉴:https://blog.csdn.net/weixin_45938441/article/details/124018485
问题描述
目前处于编写worker与coordinate进行RPC通信的环节,worker中的Map和Reduce方法还都没有开动只有一个打印逻辑,只是想先测一下,worker和coordinate之间能否正常通信。随后在map阶段,worker端可以正常拿到task信息,但是一切换到reduce阶段,程序就发生了死锁,情况如下。
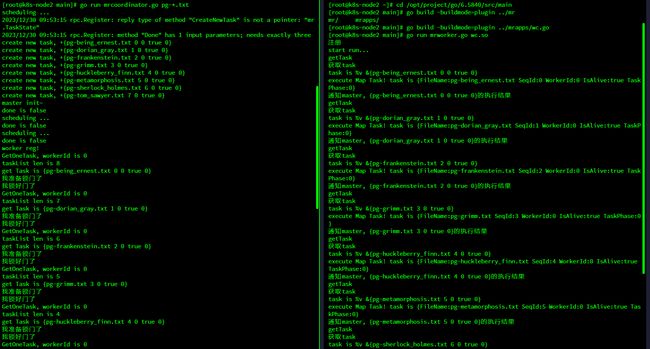 以上是map阶段的程序运行结果,左边是coordinator端,右边是worker端,coordinator可以正常创建task,worker可以正常拿到task,并且进行打印
以上是map阶段的程序运行结果,左边是coordinator端,右边是worker端,coordinator可以正常创建task,worker可以正常拿到task,并且进行打印
到了reduce阶段之后是这样的

正常创建了任务,但是之后就一动不动了。。。。。。
解决历程
发生死锁的程序如下
coordinator
package mr
import (
"fmt"
"log"
"sync"
"time"
)
import "net"
import "os"
import "net/rpc"
import "net/http"
type TaskPhase int
type TaskStatus int
const (
MAP_PHASE TaskPhase = 0
REDUCE_PHASE TaskPhase = 1
)
const (
// 刚创建还没有进入到队列中
CREATE TaskStatus = 0
// 进入到队列中,但是还没有被worker获取到的状态
PREPARE TaskStatus = 1
// 正在运行中
RUNNING TaskStatus = 2
// 运行失败
FAILED TaskStatus = 3
// 完成
COMPLETE TaskStatus = 4
)
const (
// 任务超过10秒就算失败
TASK_TIMEOUT = time.Second * 10
// 定时扫描任务队列状态的时间间隔
SCHEDULE_TIME = time.Second
)
type Task struct {
// 任务处理的文件名
FileName string
// 任务的序列号
SeqId int
// 任务的workerid
WorkerId int
// 任务是否可用
IsAlive bool
// 任务阶段
TaskPhase TaskPhase
}
type TaskState struct {
// 任务开始时间
StartTime time.Time
// 任务状态
Status TaskStatus
// 任务序列
SeqId int
// 任务名
FileName string
// workerId
WorkerId int
}
type Coordinator struct {
// map的数量
MapNumber int
// reduce的数量
ReduceNumber int
// 任务队列
TaskList chan Task
// 任务状态
TaskStates []TaskState
// 任务阶段
TaskPhase TaskPhase
// 锁
lock sync.Mutex
// Worker的序列号
WorkerSeq int
// 是否完成
done bool
}
// start a thread that listens for RPCs from worker.go
func (c *Coordinator) server() {
rpc.Register(c)
rpc.HandleHTTP()
//l, e := net.Listen("tcp", ":1234")
sockname := coordinatorSock()
os.Remove(sockname)
l, e := net.Listen("unix", sockname)
if e != nil {
log.Fatal("listen error:", e)
}
go http.Serve(l, nil)
}
// main/mrcoordinator.go calls Done() periodically to find out
// if the entire job has finished.
func (c *Coordinator) Done() bool {
c.lock.Lock()
defer c.lock.Unlock()
return c.done
}
func (c *Coordinator) schedule() {
for {
//utils.DPrintf("scheduling ...\n")
fmt.Println("scheduling ...")
c.scanOneSchedule()
time.Sleep(SCHEDULE_TIME)
if c.done {
return
}
}
}
func (c *Coordinator) scanOneSchedule() {
c.lock.Lock()
defer c.lock.Unlock()
allDone := true
for index, state := range c.TaskStates {
status := state.Status
if status == CREATE {
allDone = false
c.TaskList <- c.CreateNewTask(index, state)
c.TaskStates[index].Status = PREPARE
} else if status == PREPARE {
allDone = false
} else if status == RUNNING {
// 检测运行时间
allDone = false
if time.Now().Sub(state.StartTime) > TASK_TIMEOUT {
// 如果超时,直接重发
c.TaskList <- c.CreateNewTask(index, state)
c.TaskStates[index].Status = PREPARE
}
} else if status == FAILED {
// 运行失败了
allDone = false
c.TaskList <- c.CreateNewTask(index, state)
c.TaskStates[index].Status = PREPARE
} else if status == COMPLETE {
fmt.Printf("task %s\n", state.FileName)
} else {
panic("task status is error")
}
}
if allDone {
if c.TaskPhase == MAP_PHASE {
c.TaskPhase = REDUCE_PHASE
// 切换状态
c.TaskStates = make([]TaskState, c.ReduceNumber)
} else {
c.done = true
}
}
}
func (c *Coordinator) CreateNewTask(seqId int, state TaskState) Task {
task := Task{
FileName: "",
SeqId: seqId,
IsAlive: true,
TaskPhase: c.TaskPhase,
}
if c.TaskPhase == MAP_PHASE {
task.FileName = state.FileName
}
fmt.Printf("create new task, +%v\n", task)
return task
}
// create a Coordinator.
// main/mrcoordinator.go calls this function.
// nReduce is the number of reduce tasks to use.
func MakeCoordinator(files []string, nReduce int) *Coordinator {
c := Coordinator{
MapNumber: len(files),
ReduceNumber: nReduce,
TaskPhase: MAP_PHASE,
TaskStates: make([]TaskState, len(files)),
TaskList: make(chan Task, len(files)),
WorkerSeq: 0,
done: false,
}
// 根据文件创建任务队列
// 初始化
for i := 0; i < len(files); i++ {
c.TaskStates[i] = TaskState{
StartTime: time.Now(),
Status: CREATE,
SeqId: i,
FileName: files[i],
}
}
// 定时扫描队列
go c.schedule()
// Your code here.
// 查看文件信息
c.server()
fmt.Println("master init~")
return &c
}
rpc
package mr
//
// RPC definitions.
//
// remember to capitalize all names.
//
import (
"errors"
"fmt"
"log"
"net/rpc"
"os"
"time"
)
import "strconv"
// Cook up a unique-ish UNIX-domain socket name
// in /var/tmp, for the coordinator.
// Can't use the current directory since
// Athena AFS doesn't support UNIX-domain sockets.
func coordinatorSock() string {
//s := "/var/tmp/5840-mr-"
s := "E:\\project\\tmp\\5840-mr-"
s += strconv.Itoa(os.Getuid())
return s
}
type RegArgs struct {
WorkerId int
}
type RegReply struct {
}
func (w *worker) register() {
fmt.Println("注册")
args := &RegArgs{}
reply := &RegReply{}
err := call("Coordinator.RegWorker", args, reply)
if !err {
log.Fatal("worker register error!", err)
}
w.WorkerId = args.WorkerId
}
type TaskArgs struct {
// work节点的id
WorkerId int
}
type TaskReply struct {
Task *Task
}
func (w *worker) getTask() (*Task, error) {
fmt.Println("获取task")
args := &TaskArgs{WorkerId: w.WorkerId}
reply := &TaskReply{}
res := call("Coordinator.GetOneTask", args, reply)
if !res {
return nil, errors.New("worker getTask error!")
}
return reply.Task, nil
}
type ReportArgs struct {
// 任务的运行结果
Result bool
// 任务阶段
TaskPhase TaskPhase
// workerID
WorkerId int
// 任务
Task Task
}
type ReportReply struct {
}
func (w *worker) reportTask(task Task, res bool) error {
fmt.Printf("通知master, %v的执行结果\n", task)
args := &ReportArgs{
Result: res,
TaskPhase: task.TaskPhase,
WorkerId: w.WorkerId,
Task: task,
}
reply := &ReportReply{}
err := call("Coordinator.Report", args, reply)
if err {
return errors.New("report task failed!")
}
return nil
}
/*
*
进行rpc通信,返回是否成功通信
*/
func call(rpcname string, args interface{}, reply interface{}) bool {
sockname := coordinatorSock()
conn, err := rpc.DialHTTP("unix", sockname)
if err != nil {
log.Fatal("dialing: ", err)
}
// 离开之前关闭连接
defer conn.Close()
// 调用方法
err = conn.Call(rpcname, args, reply)
if err != nil {
fmt.Println(err)
return false
}
return true
}
func (c *Coordinator) RegWorker(args *RegArgs, reply *RegReply) error {
fmt.Println("worker reg!")
c.lock.Lock()
defer c.lock.Unlock()
args.WorkerId = c.WorkerSeq
c.WorkerSeq++
return nil
}
func (c *Coordinator) GetOneTask(args *TaskArgs, reply *TaskReply) error {
fmt.Printf("GetOneTask, workerId is %d\n", args.WorkerId)
fmt.Printf("taskList len is %d\n", len(c.TaskList))
task := <-c.TaskList
task.WorkerId = args.WorkerId
reply.Task = &task
fmt.Printf("get Task is %v\n", task)
if !task.IsAlive {
// 如果当前任务是不可用的
fmt.Printf("task not alive, task is %v\n", task)
return errors.New("task not alive")
}
if task.TaskPhase != c.TaskPhase {
// 当前任务的阶段不是已经切换过来的阶段
fmt.Printf("task phase not truth, jump it\n")
return errors.New("task phase not truth jump")
}
if c.TaskStates[task.SeqId].Status != PREPARE {
// 任务不是prepare直接不能拿
fmt.Printf("new task must prepare, task %v\n", task)
return errors.New("task mush prepare")
}
c.lock.Lock()
// 修改对应任务的状态
c.TaskStates[task.SeqId].Status = RUNNING
c.TaskStates[task.SeqId].StartTime = time.Now()
c.TaskStates[task.SeqId].WorkerId = args.WorkerId
c.lock.Unlock()
return nil
}
func (c *Coordinator) Report(args *ReportArgs, reply *ReportReply) error {
c.lock.Lock()
defer c.lock.Unlock()
seqId := args.Task.SeqId
// 如果发现当前阶段不一致,或者当前的任务已经分配给了其他任务
if c.TaskPhase != args.TaskPhase || c.TaskStates[seqId].WorkerId != args.WorkerId {
fmt.Printf("in report task, workerId = %v report a useless task = %v\n", args.WorkerId, args.Task)
return errors.New("task report error")
}
if args.Result {
// 任务执行成功了
// 修改任务状态
c.TaskStates[seqId].Status = COMPLETE
} else {
// 任务执行失败
c.TaskStates[seqId].Status = FAILED
}
go c.scanOneSchedule()
return nil
}
当切换至Reduce阶段后,执行到GetOneTask方法的c.lock.Lock()之后,协程就停了,之后会跳到每隔一秒刷新状态的协程中,即方法scanOneSchedule中,之后程序就彻底死锁了,因此,猜测问题的切入口应该是在这两个方法中寻找,必然是哪里出现了逻辑错误,导致释放锁程序没有执行。
经调试后发现,问题出现在这里,如下。
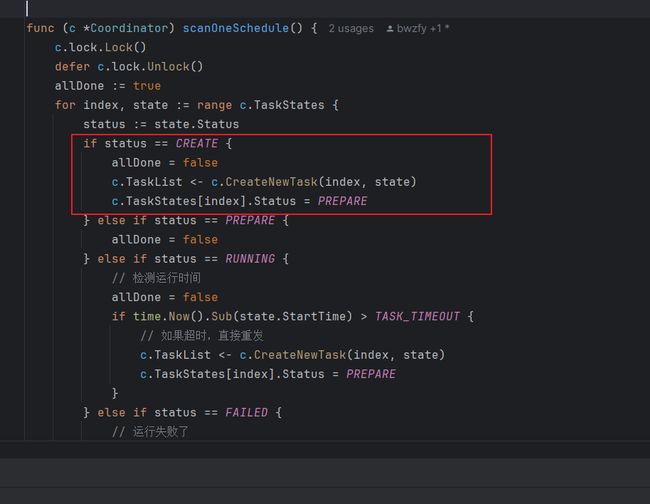
当程序切换至Reduce阶段,TaskStates的长度会由8切换至10,但是TaskList长度在初始化时,就设定为了8,因此会出现异常,导致后续的Unlock()逻辑无法触发导致死锁。
解决方案
在初始化阶段设置TaskList长度的时候,判断map的长度和reduce的长度,如果哪个更长,就用哪个去初始化TaskList,程序如下.

由于不熟悉Go语言(一天速成),导致寻找bug的过程花了很长时间,在此记录一下。
得出的结论是,果然释放锁的程序无论如何一定要执行,得放finally中。