树莓派也可以部署基于YOLO的目标检测

YOLO目标检测结果
在本文的第一部分中,我测试了YOLO(You Only Look Once)这一流行的目标检测库的“复古”版本。只使用OpenCV运行深度学习模型,而不使用“沉重”的框架如PyTorch或Keras,对于低功耗设备来说是有前途的,因此我决定深入研究这个主题,看看最新的YOLO v8模型在树莓派上的工作原理。
让我们深入了解。
硬件
在云中运行任何模型通常不是问题,资源几乎是无限的。但对于“在现场”的硬件,有更多的限制。有限的RAM、CPU功率,甚至不同的CPU架构、较旧或不兼容的软件版本、缺乏高速互联网连接等等。云基础设施的另一个重要问题是成本。假设我们正在制作一个智能门铃,并且我们想要向其添加人员检测。我们可以在云中运行一个模型,但每个API调用都要花钱,谁来支付呢?并不是每个客户都愿意为门铃或任何类似的“智能”设备支付月费,因此在本地运行模型可能至关重要,即使结果可能不那么好。
在这个测试中,我将在树莓派上运行YOLO v8模型:

树莓派4
树莓派是一款便宜的信用卡大小的单板计算机,运行Raspbian或Ubuntu Linux。我将测试两个不同的版本:
树莓派3 Model B,制造于2015年。它配备了1.2 GHz Cortex-A53 ARM CPU和1 GB RAM。
树莓派4,制造于2019年。它配备了1.8 GHz Cortex-A72 ARM CPU和1、4或8 GB RAM。
树莓派计算机现在广泛用于不仅是爱好和DIY项目,还用于嵌入式工业应用(专为此设计的树莓派计算模块)。因此,看到这些板子如何处理目标检测等计算要求较高的操作是很有趣的。在接下来的所有测试中,我将使用这张图片:

测试图片
现在,让我们看看它是如何工作的。
“标准”版本的YOLOv8
作为热身,让我们尝试标准版本,就像它在官方GitHub页面上描述的那样:
from ultralytics import YOLOimport cv2import timemodel = YOLO('yolov8n.pt')img = cv2.imread('test.jpg')# First run to 'warm-up' the modelmodel.predict(source=img, save=False, save_txt=False, conf=0.5, verbose=False)# Second runt_start = time.monotonic()results = model.predict(source=img, save=False, save_txt=False, conf=0.5, verbose=False)dt = time.monotonic() - t_startprint("dT:", dt)# Show resultsboxes = results[0].boxesnames = model.namesconfidence, class_ids = boxes.conf, boxes.cls.int()rects = boxes.xyxy.int()for ind in range(boxes.shape[0]): print("Rect:", names[class_ids[ind].item()], confidence[ind].item(), rects[ind].tolist())在“生产”系统中,可以从相机中获取图像;对于我们的测试,我使用了一个名为“test.jpg”的文件,如前所述。我还执行了两次“predict”方法,以使时间估计更加准确(第一次运行通常需要更多时间,因为模型需要“热身”并分配所有所需的内存)。树莓派以“无头”模式工作,没有显示器,因此我使用控制台作为输出;这是大多数嵌入式系统工作的一种更或多或少的标准方式。
在具有32位操作系统的树莓派3上,这个版本不起作用:pip不能安装“ultralytics”模块,因为出现了以下错误:
ERROR: Cannot install ultralyticsThe conflict is caused by: ultralytics 8.0.124 depends on torch>=1.7.0结果发现,PyTorch仅适用于ARM 64位操作系统。在具有64位操作系统的树莓派4上,代码确实可以工作,计算时间约为0.9秒。控制台输出如下:
我还在台式电脑上进行了相同的实验以可视化结果:
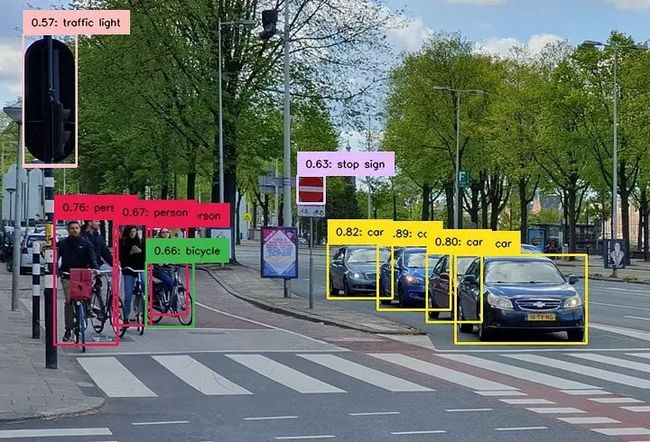
YOLO v8 Nano检测结果
正如我们所看到的,即使对于“nano”大小的模型,结果也相当不错。
Python ONNX版本
ONNX(开放神经网络交换)是一种用于表示机器学习模型的开放格式。它也得到了OpenCV的支持,因此我们可以很容易地以这种方式运行我们的模型。YOLO的开发人员已经提供了一个命令行工具来进行此转换:
yolo export model=yolov8n.pt imgsz=640 format=onnx opset=12在这里,“yolov8n.pt”是将要转换的PyTorch模型文件。文件名中的最后一个字母“n”表示“nano”。不同的模型可用(“n” — nano,“s” — small,“m” — medium,“l” — large),显然,对于树莓派,我将使用最小和最快的模型。可以在台式电脑上进行转换,然后使用“scp”命令将模型复制到树莓派:
scp yolov8n.onnx pi@raspberrypi:/home/pi/Documents/YOLO现在我们准备好准备源代码。我使用了Ultralytics存储库中的一个示例,稍作修改以在树莓派上运行:
import cv2
import time
model: cv2.dnn.Net = cv2.dnn.readNetFromONNX("yolov8n.onnx")
names = "person;bicycle;car;motorbike;aeroplane;bus;train;truck;boat;traffic light;fire hydrant;stop sign;parking meter;bench;bird;" \
"cat;dog;horse;sheep;cow;elephant;bear;zebra;giraffe;backpack;umbrella;handbag;tie;suitcase;frisbee;skis;snowboard;sports ball;kite;" \
"baseball bat;baseball glove;skateboard;surfboard;tennis racket;bottle;wine glass;cup;fork;knife;spoon;bowl;banana;apple;sandwich;" \
"orange;broccoli;carrot;hot dog;pizza;donut;cake;chair;sofa;pottedplant;bed;diningtable;toilet;tvmonitor;laptop;mouse;remote;keyboard;" \
"cell phone;microwave;oven;toaster;sink;refrigerator;book;clock;vase;scissors;teddy bear;hair dryer;toothbrush".split(";")
img = cv2.imread('test.jpg')
height, width, _ = img.shape
length = max((height, width))
image = np.zeros((length, length, 3), np.uint8)
image[0:height, 0:width] = img
scale = length / 640
# First run to 'warm-up' the model
blob = cv2.dnn.blobFromImage(image, scalefactor=1 / 255, size=(640, 640), swapRB=True)
model.setInput(blob)
model.forward()
# Second run
t1 = time.monotonic()
blob = cv2.dnn.blobFromImage(image, scalefactor=1 / 255, size=(640, 640), swapRB=True)
model.setInput(blob)
outputs = model.forward()
print("dT:", time.monotonic() - t1)
# Show results
outputs = np.array([cv2.transpose(outputs[0])])
rows = outputs.shape[1]
boxes = []
scores = []
class_ids = []
output = outputs[0]
for i in range(rows):
classes_scores = output[i][4:]
minScore, maxScore, minClassLoc, (x, maxClassIndex) = cv2.minMaxLoc(classes_scores)
if maxScore >= 0.25:
box = [output[i][0] - 0.5 * output[i][2], output[i][1] - 0.5 * output[i][3],
output[i][2], output[i][3]]
boxes.append(box)
scores.append(maxScore)
class_ids.append(maxClassIndex)
result_boxes = cv2.dnn.NMSBoxes(boxes, scores, 0.25, 0.45, 0.5)
for index in result_boxes:
box = boxes[index]
box_out = [round(box[0]*scale), round(box[1]*scale),
round((box[0] + box[2])*scale), round((box[1] + box[3])*scale)]
print("Rect:", names[class_ids[index]], scores[index], box_out)如我们所见,我们不再使用PyTorch和原始的Ultralytics库,但所需的代码量更大。我们需要将图像转换为一个blob,这是YOLO模型所需的。在打印结果之前,我们还需要将输出矩形转换为原始坐标。但作为优势,这个代码在“纯粹”的OpenCV上运行,没有任何额外的依赖关系。
在树莓派3上,计算时间为28秒。只是为了好玩,我还加载了“medium”模型(这是一个101 MB的ONNX文件!)看看会发生什么。令人惊讶的是,应用程序没有崩溃,但计算时间为224秒(近4分钟)。显然,2015年的硬件不适合运行来自2023年的SOTA模型,但看到它如何工作仍然很有趣。
在树莓派4上,计算时间为1.08秒。
C++ ONNX版本
最后,让我们尝试我们工具集中的“最重”的武器,并在C++中编写相同的代码。但在这之前,我们需要安装用于C++的OpenCV库和头文件。最简单的方法是运行类似“sudo apt install libopencv-dev”的命令。但至少对于Raspbian,它不起作用。通过“apt”可用的最新版本是4.2,而加载YOLO模型所需的OpenCV的最低要求是4.5。因此,我们需要从源代码构建OpenCV。我将使用OpenCV 4.7,与我Python测试中使用的相同的版本:
sudo apt update
sudo apt install g++ cmake libavcodec-dev libavformat-dev libswscale-dev libgstreamer-plugins-base1.0-dev libgstreamer1.0-dev
sudo apt install libgtk2.0-dev libcanberra-gtk* libgtk-3-dev libpng-dev libjpeg-dev libtiff-dev
sudo apt install libxvidcore-dev libx264-dev libgtk-3-dev libgstreamer1.0-dev gstreamer1.0-gtk3
wget https://github.com/opencv/opencv/archive/refs/tags/4.7.0.tar.gz
tar -xvzf 4.7.0.tar.gz
rm 4.7.0.tar.gz
cd opencv-4.7.0
mkdir build && cd build
cmake -D WITH_QT=OFF -D WITH_VTK=OFF -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local -D WITH_FFMPEG=ON -D PYTHON3_PACKAGES_PATH=/usr/lib/python3/dist-packages -D BUILD_EXAMPLES=OFF ..
make -j2 && sudo make install && sudo ldconfig树莓派不是世界上最快的Linux计算机,编译过程大约需要2小时。对于具有1GB RAM的树莓派3,交换文件大小应至少增加到512MB;否则,编译将失败。
C++代码本身很短:
#include
#include
#include
#include "inference.h"
int main(int argc, char **argv) {
Inference inf("yolov8n.onnx", cv::Size(640, 640), "", false);
cv::Mat frame = cv::imread("test.jpg");
// First run to 'warm-up' the model
inf.runInference(frame);
// Second run
const clock_t begin_time = clock();
std::vector output = inf.runInference(frame);
printf("dT: %f\n", float(clock() - begin_time)/CLOCKS_PER_SEC);
// Show results
for (auto &detection : output) {
cv::Rect box = detection.box;
printf("Rect: %s %f: %d %d %d %d\n", detection.className.c_str(), detection.confidence,
box.x, box.y, box.width, box.height);
}
return 0;
} 在这个代码中,我使用了Ultralitics GitHub存储库中的“inference.h”和“inference.cpp”文件,这些文件应放置在同一个文件夹中。我还执行了两次“runInference”方法,与之前的测试一样。我们现在可以使用这个命令编译源代码:
c++ yolo1.cpp inference.cpp -I/usr/local/include/opencv4 -L/usr/local/lib -lopencv_core -lopencv_dnn -lopencv_imgcodecs -lopencv_imgproc -O3 -o yolo1结果令人惊讶。C++版本比之前的版本慢得多!在树莓派3上,执行时间为110秒,比Python版本慢了三倍多。在树莓派4上,计算时间为1.79秒,大约慢了1.5倍。总的来说,很难说为什么。Python的OpenCV库是使用pip安装的,但C++的OpenCV是从源代码构建的,也许一些ARM CPU优化没有启用。如果有读者知道原因,请在下面的评论中写明。无论如何,看到这样的效果发生真的很有趣。
结论
我可以“合理猜测”大多数数据科学家和数据工程师在云中使用他们的模型,或者至少在高端设备上使用模型,并且从未尝试在嵌入式硬件上“现场”运行代码。这篇文章的目标是为读者提供一些关于它是如何工作的见解。在这篇文章中,我们尝试在不同版本的树莓派上运行YOLO v8模型,结果非常有趣。
在低功耗设备上运行深度学习模型可能是一个挑战。即使是树莓派4,也就是撰写本文时基于Raspbian的最佳模型,也只能以约1 FPS的速度提供YOLO v8 Tiny模型。当然,还有改进的空间。可能可以进行一些优化,例如将模型转换为FP16(具有较低精度的浮点格式)或甚至INT8格式。最后,可以使用在特殊的单板计算机上运行的代码,如NVIDIA Jetson Nano,它支持CUDA并且可能更快。
在本文的开头,我写道“只使用OpenCV,而不使用PyTorch或Keras等沉重的框架运行深度学习模型的可能性对于低功耗设备是有前途的”。实际上,PyTorch是一个高效且高度优化的框架。基于PyTorch的原始YOLO版本是最快的,而基于OpenCV的ONNX代码比它慢10-20%。但在我撰写本文时,PyTorch在32位ARM CPU上不可用,因此在某些平台上可能别无选择。
C++版本的结果更有趣。正如我们所看到的,要在适当的优化下运行可能是一项挑战,特别是对于嵌入式架构。而且,如果不深入研究这些细节,与由板厂商提供的Python版本相比,自定义构建的OpenCV C++代码甚至可能运行得更慢。
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除