编译原理课程设计--C语言编译器
编译原理课程设计–C语言编译器
源程序1:

源程序1词法分析结果:
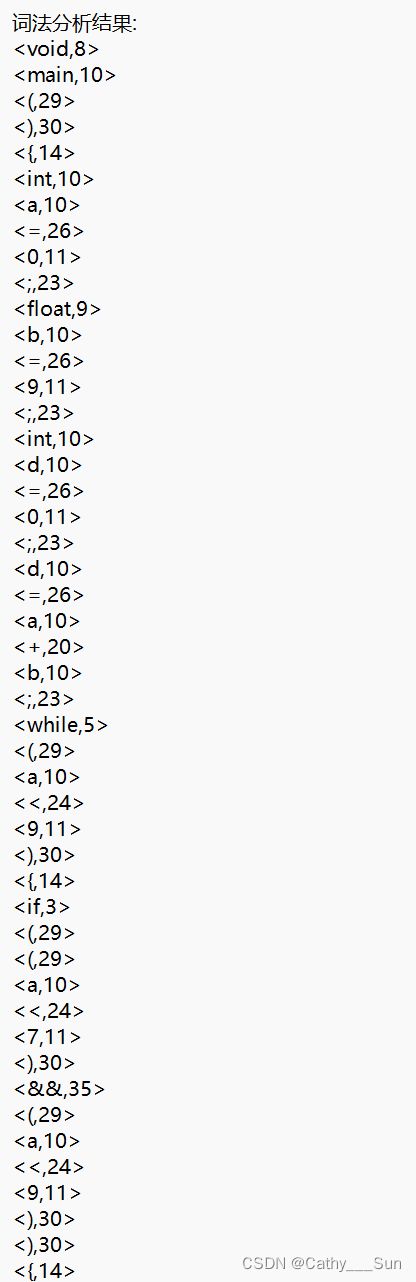
与程序1语法分析结果(部分)

源程序1四元式:

源程序1优化后的四元式:

action-goto表(部分)
文件目录:

课设目的
(1)掌握语义分析过程,即语法制导翻译过程。
(2)在语法分析的LR分析程序中的基础上添加程序,进行语义分析,生成源程序的四元式代码。
(3)理解语法分析和语义分析的接口方式。
(4)掌握中间代码的局部优化、循环优化和全局优化的基本原理和方法。
(5)对语义分析生成的四元式代码进行基本块的划分和局部优化,减少代码的存储空间,提高代码的运行效率。
课设内容
在语法分析程序中添加语义分析功能,审查TPL语言源程序是否有语义错误,若程序语义正确,则语义分析结果生成四元式代码,否则给出错误位置和原因。编写语义分析程序的流程如图2-1所示。

对语义分析的结果四元式划分基本块,采用DAG图完成块内优化,给出优化后的四元式结果。编写代码优化程序的流程如图2-2所示。

课设要求
采用自底向上的方法来设计TPL编译器,实现编译器的以下功能:
(1)能对任何TPL语言源程序的语法分析结果进行语义分析。
(2)输出语义分析过程。
(3)若程序语义正确,则语义分析结果生成四元式代码,否则给出错误位置和原因。
(4)采用基本块的划分方法对语义分析的结果四元式划分基本块。
(5)使用DAG图完成基本块的优化,给出优化后的四元式结果。
课设原理
语义分析原理
//语义分析是基于语法制导下的语义分析,对每个产生式编制一个语义子程序,在进行语法分析的过程中,当使用一个产生式进行归约时,就调用该产生式相应的语义子程序实现语义检查与翻译。语法制导定义的实现途径首先将LR分析器能力扩大,增加在归约后调用语义规则的功能,再增加语义栈,语义值放到与符号栈同步操作的语义栈中,多项语义值可放在同一个语义栈。以下给出每个产生式的语义子程序以及对应的修改后的产生式。
(0) S->vm(){S}
{S.chain:=S1.chain;}
(1) S->C{S}
{S.chain:=merge(C.chain,S.chain);}
(2) S->T{S}
{emit(jump,-,-T.codebegin);
S.chain:=T.chain;
backpatch(S1.chain,T.codebegin);}
(3) S->A;S
{S.chain := S1.chain;
backpatch(A.chain,nextstat);}
(4) S->AS
{S.chain := S1.chain;}
(5) A->nz
{S.TYPE := int;
A.chain = 0;}
(6) S->^
{S.chain := 0;}
(7) C->i(A)
{backpatch(A.true,nextstat);
C.chain := A.false;}
(8) T->W(A)
{T.codebegin:=W.codebegin;
backpatch(A.true,nexstat);
T.chain:=A.false;}
(9) T->F(A;A;A)
{T.codebegin:=F.codebegin;
backpatch(A2.true,nextstat);
T.chain: = A2.false;}
(10) A->nz=k
{A.chain = 0;
A.type := int;
emit(:=,k,-,z);}
(11) A->lz=k
{A.type := float;
emit(:=,k,-,z);
A.chain = 0;}
(12) A->z=A
{p:=z.place;
A.chain = 0;
if p ≠ nil then emit(:=,A1.place,-,p)
else error;
A.chain = 0;}
(13) A->z+A
{A.palce:=newtemp;
emit(+,z.place,A1.place,A.place);}
(14) A->z*A
{A.palce:=newtemp;
emit(*,z.place,A1.place,A.place);}
(15) A->z-A
{A.palce:=newtemp;
emit(-,z.place,A1.place,A.place);}
(16)A->z>k
{A.codebegin:=nextstat;
A.true:=nextstat;
A.false:=nextstat+1;
emit(>,z.palce,k.val,0);
emit(jump,-,-0);}
(17) A->z<k
{A.codebegin:=nextstat;
A.true:=nextstat;
A.false:=nextstat+1;
emit(<,z.palce,k.val,0);
emit(jump,-,-0);}
(18) A->(A)||(A)
{A.codebegi
n:=A1.codebegin;
backpatch(A1.false,A2.codebegin);
A.true:=merge(A1.true,A2.true);
A.false:=A2.false;}
(19) A->(A)&&(A)
{A.codebegin:=A1.codebegin;
backpatch(A1.true,A2.codebegin);
A.true:=A2.true;
A.false:=merge(A1.false,A2.false);}
(20) A->(A)!=(A)
{A.codebegin:=nextstat;
A.true:=nextstat;
A.false:=nextstat+1;
emit(!=j,A1.palce,A2.place,0);
emit(jump
,-,-0);}
(21) A->(A)==(A)
{A.codebegin:=nextstat;
A.true:=nextstat;
A.false:=nextstat+1;
emit(==j,A1.palce,A2.place,0);
emit(jump,-,-0);}
(22) A->z++
{A.palce:=newtemp;
emit(+,z.
place,1,A.place);
A.chain = 0;}
(23) A->z
{A.place := z;
emit(:=,z,-,A.place);
A.chain = 0;}
(24) A->k
{A.place := newtemp;
emit(:=,k,-,A.place);
A.chain = 0;}
(25) S->b;
{S.chain := nextstat;}
(26) W->w
{W.codebegin = nextstat;}
(27) F->f
{F.codebegin = nextstat;}
(28) A->z==k
{A.codebegin:=nextstat;
A.true:=nextstat;
A.false:=nextstat+1;
emit(==j,z.name,k,0);
emit(jump,-,-0);}
(29) A->A->nz=z
{A.chain = 0;
A.type := int;
emit(:=,z,-,z);}
(30) A->A->nz=-k
{A.chain = 0;
A.type := int;
emit(-,k,-,z);}
局部优化原理
代码优化部分主要实现对基本块内的局部优化,实验原理如下。
(1)找入口语句
程序的第一个语句;
条件转移语句或无条件转移语句的转移目标;
紧跟在条件转移语句后面的语句。
(2)划分基本块
对每一入口语句,构造其所属的基本块。它是由该入口语句到下一入口语句(不包括下一入口语句),或到一转移语句(包括该转移语句),或到一停语句(包括该停语句)之间的语句序列组成的。
(3)删除不可达语句
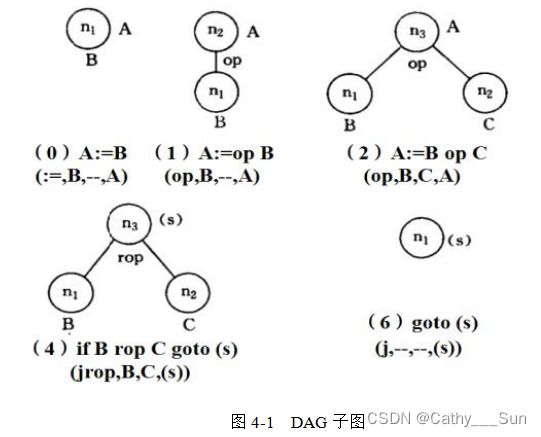
(4)对每个块按照四元式类型构造DAG图。DAG子图如图4-1所示。
数据结构、函数说明和主要算法
主要的数据结构
typedef struct//语法树的结点属性
{
string val;//常量的值
string name;//变量的名字
string type;//符号的属性和标识符的属性
string place;
int tru_e;
int fals_e;
int codebegin;
int chain;
}quaternion;
vector<int> G[1000];//语法树结点标号
vector<string> symbol;//语法树结点内容
vector <quaternion> attr;//储存语法树结点
extern int Q_count = 0;//语法树结点个数
typedef struct//四元式结构体
{
string a;
string b;
string c;
string d;
}four;
four F[MAX];//储存四元式
int F_count = 100;//四元式地址
string table_z[MAX];//符号表 变量名
int table_z_count = 0;//变量个数
string table_h[MAX];//符号表 函数名
int table_h_count = 0;//函数名个数
int new_w = 0;//新的临时变量的个数
typedef struct//优化结点属性
{
vector <string> left;//结点左方信息
string down;//结点下方信息
vector <int> parent;//父结点号容器
vector <int> son;//子结点号容器
int future;//生成的结点是几型
int num;//根据第几条四元式产生的结点
}optimize;
vector<int> parted;//入口标号
int parted_count = 0;//块数
four FF[MAX];//储存被优化后的四元式
int FF_count = 100;//被优化后的四元式地址
int down[MAX];//每一块减少的条数
int down_count = 0;
所有函数的说明
string newtemp();//新建变量
void quater(int u);//遍历语法树
u:开始遍历的结点标号
void emit();//输出四元式
void apart();//分块函数
vector <optimize> DAG(int z,int a,int b,vector <optimize> opp,int opp_count,vector <int> H[1000]);//DAG构图函数
z:第几块
a:入口标号
b:出口标号
opp:储存DAG各结点信息的容器
opp_count:DAG结点个数
H:DAG图结点标号链接情况
void work_optimize();//优化函数
void emit2()//输出优化后的四元式
主要算法
void quater(int u)//从第u个结点开始向下遍历语法树,分析每个结点,执行相应语义动作
1.if (为空结点) then return
2.end if
3.for(i ← 0 to G[u].size())
4. quater(G[u][i])//迭代遍历所有的儿子结点
5.end for
//根据不同的产生式执行语义动作
6.if(结点信息为0表示用第0条产生式进行规约)then
7. 执行第零条产生式的语义动作
8.else if(结点信息为1表示用第1条产生式进行规约)then
9. 执行第1条产生式的语义动作
10.……(若执行语义动作过程中产生新的变量名称,使用容器储存变量名称。)
11.else if(结点信息为30表示用第30条产生式进行规约)then
12. 执行第30条产生式的语义动作
13.end if
vector <optimize> DAG(int z,int a,int b,vector <optimize> opp,int opp_count,vector <int> H[1000])//a、b为两个入口语句,生成块的DAG图
1.queue <int> son;//暂存儿子结点标号
2.for(i ← a to b);//遍历一块
3. if该结点信息为0型then
4. 遍历已经生成的结点查找有无相等变量已经生成;
5. if没有then新建结点
6. else if有then更新该结点左部信息;
7. end if;
8. else if该结点信息为1型then
9. 遍历已经生成的结点查找有无相等变量已经生成;
10. 遍历已经生成的结点查找有无相等数值已经生成;
11. if变量未曾生成,数值未曾出现then
12. 新建一个儿子结点;
13. 新建一个父结点;
14. 儿子结点标号入son栈;
15. while(!son.empty());//构建语法树
16. H[opp_count].push_back(son.front());//DAG连接
17. son.pop();//son栈弹出元素
18. end while;
19. else if数值出现过,变量名未曾出现then
20. 新建一个父亲结点;
21. 儿子结点标号入son栈;
22. while(!son.empty())//构建语法树
23. H[opp_count].push_back(son.front());//DAG连接
24. son.pop();//son栈弹出元素
25. end while;
26. end if;
27. else if该结点信息为2型then
28. 遍历已经生成的结点查找有无相等变量已经生成;
29. 遍历已经生成的结点查找有无相等变量已经生成;
30. if两个变量都存在then
31. if有共同的父结点并且能合并then更新该父结点左部信息;
32. else不能合并then
33. 新建一个儿子结点;
34. 儿子结点标号入son栈
35. while(!son.empty())//构建语法树
36. H[opp_count].push_back(son.front());//DAG连接
37. son.pop();//son栈弹出元素
38. end while;
39. end if;
40. else if只有一个变量存在
41. 新建一个儿子结点;
42. 新建一个父亲结点存新的运算结果;
43. 儿子结点标号入栈;
44. son.push(opp_count-1);
45. while(!son.empty())//构建语法树
46. H[opp_count].push_back(son.front());//DAG连接
47. son.pop();//son栈弹出元素
48. end while;
49. else if一个变量都不存在then
50. 新建两个儿子结点;
51. 新建一个父亲结点;
52. 儿子结点标号入栈;
53. while(!son.empty())//构建语法树
54. H[opp_count].push_back(son.front());//DAG连接
55. son.pop();//son栈弹出元素
56. end while;
57. else if该结点信息为6型then
58. 新建一个结点;
59. end if;
60.end for
61.return opp;
void work_optimize()//对四元式进行优化
1.for(i ← 1 to parted_count)
2. vector <optimize> opp;//优化结点信息
3. vector <int> H[1000];//储存四元式DAG 画邻接表
4. int H_count = 1;//DAG结点标号
5. int opp_count = 0;//生成的DAG的结点数
6. opp = DAG(i,parted[i],parted[i+1]-1,opp,opp_count,H);//生成DAG
7. simple(opp);//根据结点是几型的确定该四元式是否需要删除,并整理保留下来的四元式信息
8.end for;
9.for(i ← 0 to FF_count)//遍历优化后的四元式
10. if是跳转语句 then
11. 根据第四区段求得跳转到第m块;
12. 根据down数组求得第m块前共减少a条四元式;
13. m = m - a;//优化后的跳转序列
14. FF[i].d = m;
15. end if;
16.end for;
17.emit2();//输出优化后的四元式
运行结果

 Q::幺幺幺伞琪琪灵伞耳琪(项目私发)
Q::幺幺幺伞琪琪灵伞耳琪(项目私发)