设计 Mint.com
1. 梳理 User Case 和 约束
Use cases
作用域内的Use Case
- User 连接到 financial account
- Service 从 Account 中提取 transactions
- 日常 Update
- 整理 transaction
- 所有的手动目录由 User 覆盖
- 没有自动化的重排机制
· - 通过目录分析月消费
- Service 推荐 budget
- 允许 user 去手动设置 budget
- 没有自动化的 重组目录
- Service 有高可用
作用域外
- Service 执行额外的日志记录和分析
约束和假设
状态假设
- 每个 Transaction 的尺寸
- user_id - 8 bytes
- created_at - 5 bytes
- seller - 32 bytes
- amount - 5 bytes
- Total: ~50 bytes
- 每个月有250GB的新transaction内容
- 每个transaction 50 bytes * 50 亿 transaction / 月
- 每三年有9 TB 的新 transaction 内容
- 假设最多的是新的 transaction,而不是更新过的已经存在的 transaction
- 2000 transaction / s
- 200 读请求 / s
方便的转换公式:
- 每个月有 250万秒
- 1 request / s = 250 万 request / 月
- 40 request / s = 1 亿 request / 月
- 400 request / s = 十亿 request / 月
2. 创建一个High Level设计
描述一个包括所有重要组件的 High Level 设计
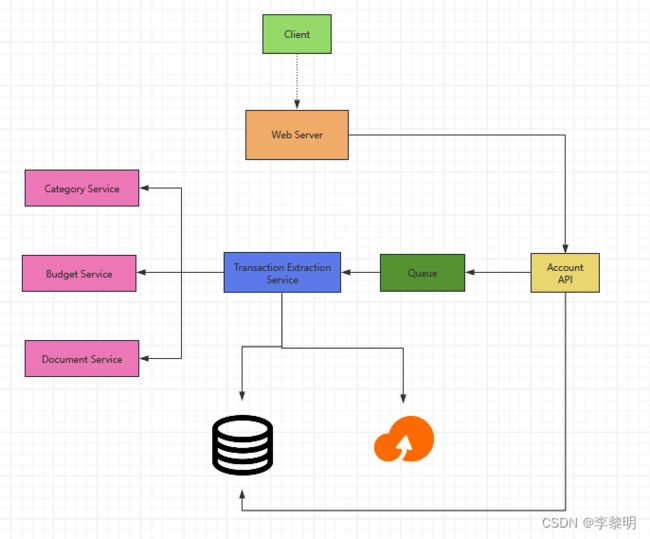
3. 设计核心组件
Use Case: User 连接到 financial account
- Client 发送一个请求到 Web Server, 作为反向代理运行
- Web Server 转发 request 到 Account API 服务器
- Account API 服务器更新 SQL 数据库的
accounts表(伴随着新记录的 account 信息)
accounts 表应该有如下结构:
id int NOT NULL AUTO_INCREMENT
created_at datetime NOT NULL
last_update datetime NOT NULL
account_url varchar(255) NOT NULL
account_login varchar(32) NOT NULL
account_password_hash char(64) NOT NULL
user_id int NOT NULL
PRIMARY KEY(id)
FOREIGN KEY(user_id) REFERENCES users(id)
我们可以创建一个 index 在 id,user_id 和 created_at 去加速查询(登录时间代替扫描整张表)
,而且保持数据在内存里,从内存里面线性读取1MB数据需要花费 250 微妙,当从 SSD 中读取需要 倍,从磁盘中读取需要 80倍
我们可以使用 public REST API:
$ curl -X POST --data '{ "user_id": "foo", "account_url": "bar", \
"account_login": "baz", "account_password": "qux" }' \
https://mint.com/api/v1/account
Use Case: Service从账户获取transaction
我们想从账户中提取信息在如下的 case:
- User 第一个 link Account
- User 手动刷新 Account
- 对于过去 30 天内一直处于活动状态的用户,每天自动生成
Data Flow:
- Client 发送一个 reuqest 给 Web Server
- Web Server 转发 请求到 Accounts API Server
- Account API service 放一个 job在 Queue里面,比如 Amazon SQS 和 Rabbit MQ
- 提取 transaction 会需要一段时间,我们可能想要使用 queue 去异步的操作,尽管这会需要额外的复杂度
- Transaction Extraction Service 做如下的事:
- 针对给定财政机构的账户,从 Queue 中拉取数据,并且提取 transaction,存储结果作为二进制文件进 Object Store
- 使用 Category Service 去组织每个 transaction
- 通过目录 使用 Budget Service 去计算每个月的花费
- Budget Service使用Notification Service去让 User 知道他们是否靠近或超预算
- 更新 SQL Database 里的
transactions表伴随着格式化的 transaction - 更新 SQL Database 里的
monthly_spendingtable 的月均消费 - 提示 User 交易已经通过Notification Service完成
- 使用一个 Queue(not pictured) 去异步的发送 notifications
transactions Table 应该有以下的结构:
id int NOT NULL AUTO_INCREMENT
created_at datetime NOT NULL
seller varchar(32) NOT NULL
amount decimal NOT NULL
user_id int NOT NULL
PRIMARY KEY(id)
FOREIGN KEY(user_id) references users(id)
我们会创建一个 index 在 id,user_idm和 created_at
monthly_spending 表会有如下的结构:
id int NOT NULL AUTO_INCREMENT
month_year date NOT NULL
category varchar(32)
amount decimal NOT NULL
user_id int NOT NULL
PRIMARY KEY(id)
FOREIGN KEU(user_id) REFERENCES users(id)
我们将创建一个 index 在 id 和 user_id
Category Service
我们可以寻找一个 seller-to-category 目录,伴随着最流行的 sellers. 如果我们预估 50000 sellers 和评估每个 entry 会花费少于 255 bytes. 这个目录将只是需要 12 MB 的内存
class DefaultCategories(Enum):
HOUSING = 0
FOOD = 1
GAS = 2
SHOPPING = 3
...
seller_category_map = {}
seller_category_map['Exxon'] = DefaultCategories.GAS
seller_category_map['Target'] = DefaultCategories.SHOPPING
对于没有初始化寻找到的 map, 我们可以使用众包 effort, 通过评估手动目录股改我们的 User提供的数据。我们可以使用一个 heap 去快速的查找顶级手动覆盖每个 seller 在 O(1)时间内。
class Categorizer(object):
def __init__(self, seller_category_map, seller_category_crowd_overrides_map):
self.seller_category_map = seller_category_map
self.seller_category_crowd_overrides_map = \
seller_category_crowd_overrides_map
def categorize(self, transaction):
if transaction.seller in self.seller_category_map:
return self.seller_category_map[transaction.seller]
elif transaction.seller in self.seller_category_crowd_overrides_map:
self.seller_category_map[transaction.seller] = \
self.seller_category_crowd_overrides_map[transaction.seller].peek_min()
return self.seller_category_map[transaction.seller]
return None
Transaction 实现:
class Transaction(object):
def __init__(self, created_at, seller, amount):
self.created_at = created_at
self.seller = seller
self.amount = amount
Use Case: Service 推荐 budget
我们可以使用普遍的 budget 模板,用来分配目录总数基于income tiers. 使用这种方法,我们将不会存储 1 亿 budget 作为约束,只有这些被 User 覆盖掉,如果一个 user 覆盖掉一个 bug=dget 目录。 我们可以存储这个 覆盖量 在 表 budget_overrides
class Budget(object):
def __init__(self, income):
self.income = income
self.categories_to_budget_map = self.create_budget_template()
def create_budget_template(self):
return {
DefaultCategories.HOUSING: self.income * .4,
DefaultCategories.FOOD: self.income * .2,
DefaultCategories.GAS: self.income * .1,
DefaultCategories.SHOPPING: self.income * .2,
...
}
def override_category_budget(self, category, amount):
self.categories_to_budget_map[category] = amount
对于 Budget Service, 我们可以在 transactions 表里面运行 SQL Query去生成 monthly_spending 聚合表, monthly_spendging 表将可能有更少的行数,相比较于 50 亿的 transatcion. 自动 user 典型的有大量的 trasnactions 每个月。
作为一个替代,我们可以运行 MapReduce jobs在二进制的 trasnaction 文件中:
- 目录化每个 trasnaction
- 通过目录生成月综合消费
在 trasnaction 文件宏进行分析可以显式的减少数据库的负载。
我们可以调用 Budget Service 去重新进行分析User是否更新目录
样例log 文件格式:
user_id timestamp seller amount
MapReduce implementation:
class SpendingByCategory(MRJob):
def __init__(self, categorizer):
self.categorizer = categorizer
self.current_year_month = calc_current_year_month()
...
def calc_current_year_month(self):
"""Return the current year and month."""
...
def extract_year_month(self, timestamp):
"""Return the year and month portions of the timestamp."""
...
def handle_budget_notifications(self, key, total):
"""Call notification API if nearing or exceeded budget."""
...
def mapper(self, _, line):
"""Parse each log line, extract and transform relevant lines.
Argument line will be of the form:
user_id timestamp seller amount
Using the categorizer to convert seller to category,
emit key value pairs of the form:
(user_id, 2016-01, shopping), 25
(user_id, 2016-01, shopping), 100
(user_id, 2016-01, gas), 50
"""
user_id, timestamp, seller, amount = line.split('\t')
category = self.categorizer.categorize(seller)
period = self.extract_year_month(timestamp)
if period == self.current_year_month:
yield (user_id, period, category), amount
def reducer(self, key, value):
"""Sum values for each key.
(user_id, 2016-01, shopping), 125
(user_id, 2016-01, gas), 50
"""
total = sum(values)
yield key, sum(values)
4. 扩展设计:
架构优化
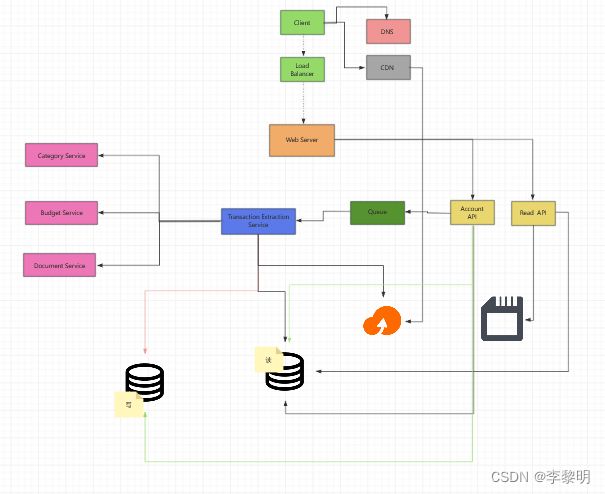
我们可以添加一个额外的 Use Case: User 访问 summaries 和 transactions
User 状态,通过目录聚合,而且最近的 trasactions 被放在一个 Memory Cache, 比如 Redis 或者 Memcached.
- Client 发送一个读请求到 Web Server
- Web Server 转发请求到 Read API Server
- 静态内容会被存储在 Object Store, 比如 S3, 被 缓存进 CDN
- Read API server 会做下面的事情:
- 为内容Check Memery Cache
- 如果 url 在内存中,发挥缓存内容
- 否则
- 如果 url 在 SQL 数据库中,拉取内容
- 更新内容进缓存中
- 如果 url 在 SQL 数据库中,拉取内容
我们可以用数据仓库解决方案(如Amazon Redshift或Google BigQuery)创建一个单独的分析数据库,而不是将monthly_spending聚合表保存在SQL数据库中。
我们可能只想在数据库中存储一个月的交易数据,而将剩下的数据存储在数据仓库或对象存储中。像亚马逊S3这样的对象存储可以轻松处理每月250 GB新内容的限制。
为了解决每秒200个平均读取请求(峰值更高),流行内容的流量应由内存缓存而不是数据库处理。内存缓存对于处理分布不均的流量和流量尖峰也很有用。只要SQL读取副本没有因为复制写入而陷入困境,它们应该能够处理缓存缺失。
对于单个SQL写主从模式来说,每秒2000个平均事务写入(峰值更高)可能很难。我们可能需要采用额外的SQL扩展模式