快乐学Python,使用爬虫爬取电视剧信息,构建评分数据集
在前面几篇文章中,我们了解了Python爬虫技术的三个基础环节:下载网页、提取数据以及保存数据。
这一篇文章,我们通过实际操作来将三个环节串联起来,以国产电视剧为例,构建我们的电视剧评分数据集。
1、需求描述
收集目前国产电视剧的相关数据,需要构建国产电视剧和评分的数据集。
2、需求说明
收集国产电视剧的数据,越全越好,至少收集评分、电视剧名称、主演信息三个信息。之后将数据存储在一个 csv 表中,表头如下:
- title,代表电视剧名称
- rating,代表电视剧评分
- stars,代表电视剧主演
3、初步分析
在基于 Python 技术来构建数据集的方式中,首当其冲要做的事情就是选择要抓取的网站。选择的标准一般主要看网站是否具备我们想要的信息,以及是否方便抓取。
这次我们要抓取的电视剧信息中,还有一个重要的考量因素就是是否方便抓取多个页面,毕竟一个网页一般都无法包含全部的电视剧信息。
我们在下载 HTML 页面的环节往往需要下载多个页才能获取完整的数据。
通过在搜索引擎搜索有电视剧列表的网站,我们决定下载“全集网”中的电视剧信息。
4、全集网主页分析
打开全集网中的国产电视剧主页,可以看到如下图示。
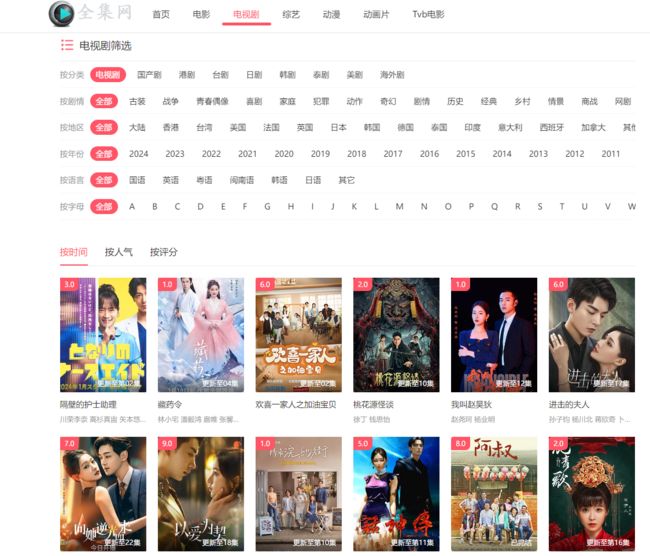
通过观察以上页面,可以发现该网页我们想要的字段:标题、评分和主演信息在页面上都有显示,只要显示就说明我们可以通过爬虫拿到。
同时注意我们地址栏url地址的变化,当前是:
![]()
现在我们来考察它的加载方式,拉到底部,可以看到该网页提供的是传统的翻页操作。如下所示:
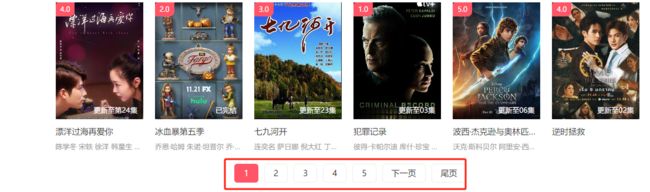
我们点击第二页,发现跳转到了一个新的页面,该页面的 URL 和我们一开始访问的差不多,只是其中有一个数据的值变成了2。
![]()
这说明我们可以通过不断改变 URL 中的 页码 参数的值,来访问第二页之后的内容。这样在后续写代码中,我们只需要写针对一个页面的抓取代码,然后用一个循环来不断执行该方法,并每次叠加 page 的值就能实现将所有电视剧的内容抓取下来。
综上所述,全集网的页面更符合我们本次抓取的任务需求,我们后续就将该网页作为我们的抓取目标。
5、数据获取-下载所需网页
全集网的电视剧比较多,我们本次下载的html网页也会很多,所以可以在电脑上新建一个文件夹,在文件夹中新建我们的程序文件,将下载的网页保存在同级文件夹即可。(创建文件夹可以手动创建,无需通过程序,大家自行创建吧!)
创建完文件夹和程序文件后,先编写下载网页和保存文件的代码。
不想写的可以直接把前面文章中的网页下载代码和数据保存到文件的代码复制过来。
import urllib3
# 第一个函数,用来下载网页,返回网页内容
# 参数 url 代表所要下载的网页网址。
def download_content(url):
http = urllib3.PoolManager()
response = http.request("GET", url)
response_data = response.data
html_content = response_data.decode()
return html_content
# 第二个函数,将字符串内容保存到文件中
# 第一个参数为所要保存的文件名,第二个参数为要保存的字符串内容的变量
def save_to_file(filename, content):
fo = open(filename,"w", encoding="utf-8")
fo.write(content)
fo.close()
运行以上代码后,我们就可以使用这两个函数来下载网页了。
(1)单个网页下载
先来下载一个网页试试情况:
# 将我们找到的电视剧网的网址存储在变量 url 中
url = "https://www.fschurun.com/vodshow/13--------1---.html"
# 将url 对应的网页下载下来,并把内容存储在 html_content 变量中
html_content = download_content(url)
# 将 html_content 变量中的内容存储在 htmls 文件夹中,文件名为 tv1.html 代表第一页
save_to_file("tvs_html/tv1.html",html_content)
接下来,我们点击 tv1.html 打开,来查看是否有我们需要的电视剧信息。回过头去看我们上文中发的截图,有个电视剧的名称是《藏药令》。

说明电视剧网的内容不是动态生成的,可以用 urllib3 进行下载。
(2)多个网页下载
现在第一个网页已经下载成功了。我们目标是下载 137个网页的内容,所以剩余的可以通过一个循环来下载。在我们之前的分析中,下载第二页和之后的内容只需要修改 URL 中的 page 的值即可。
另外,在我们通过循环来批量下载内容的时候,还有一个很重要的注意事项,一般都会在每次下载之后等待几百毫秒的时间,再进行下一次下载,这样可以避免短时间内对网站发起大量的下载请求,浪费网站的带宽资源。
在今天这个案例中,我们每次下载之后等待一秒再进行下一次下载。在 Python 中,我们可以通过 time 模块的 sleep 方法来使程序暂停固定的时间。
代码如下:
import time
for i in range(2, 137):
url = "https://www.fschurun.com/vodshow/13--------"+str(i)+"---.html";
print("begin download:",url);
html = download_content(url);
filename = "tvs_html/tv"+str(i)+".html";
save_to_file(filename, html);
print("download end ");
time.sleep(1);
执行上述程序,可以看到程序每隔一秒钟输出一行信息,如下所示。
执行完毕后,我们在侧边栏打开 htmls 文件夹,可以看到我们的 137 个 html 文件已经保存成功。
6、数据提取
我们前面的需求分析已经提到了,需要电视剧的名称、评分和主演信息。那我们就开始分析网页,找到我们需要的数据所在的标签。
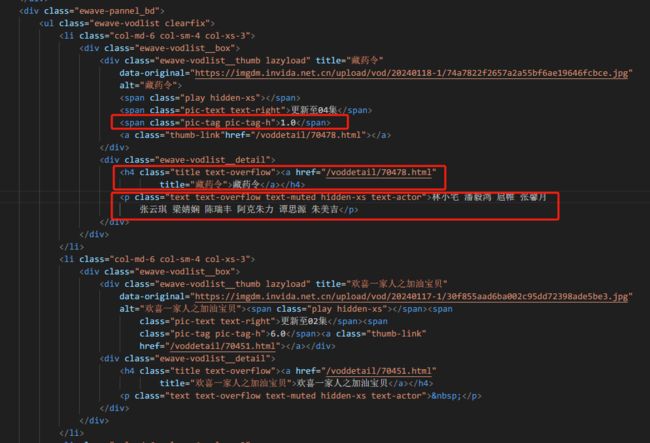
从图中我们可以得出:
- 电视剧列表是用ul布局,每个li代表一个电视剧。
- 在li里面,又有两个div,第一个div来展示电视剧评分。第二个div来展示电视剧名称和主演信息。
- 具体的内容又以span标签、h4标签或p标签来展示。
至此,我们的数据提取思路基本就清晰了:
- 获取所有 class=ewave-vodlist__box 的 div 标签对象。
- 针对每一个标签对象,都尝试:
- 查找div,class为ewave-vodlist__thumb lazyload下面的span标签的值,作为评分数据。
- 查找div,class为ewave-vodlist__detail下面的h4标签的值,作为电视剧名称。
- 查找div,class为ewave-vodlist__detail下面的p标签的值,作为主演数据
(1)提取单个HTML的所有电视剧信息
接下里,我们按照上面的数据提取思路,来编写获取单个HTML文件电视剧信息的代码。单个文件处理完之后,扩展到多个文件的数据处理就简单了。
代码如下:
from bs4 import BeautifulSoup
# 输入参数为要分析的 html 文件名,返回值为对应的 BeautifulSoup 对象
def create_doc_from_file(filename):
fo = open(filename, "r", encoding="utf-8");
html_content = fo.read();
fo.close()
doc = BeautifulSoup(html_content);
return doc;
之后根据初步分析中分析的步骤,实现内容的抓取。
# 用tv1.html的内容创建BeautifulSoup对象
doc = create_doc_from_file("tvs_html/tv1.html");
# 查找class="ewave-vodlist__box" 的所有 div 标签
# 并以列表形式存储在 box_list 中
box_list = doc.find_all("div",class_="ewave-vodlist__box");
# 使用遍历循环遍历 box_list 中的所有标签对象
for box in box_list:
# 根据上述分析的思路,分别获取包含标题、评分、和演员信息的标签
rating = box.find("div",class_ = "ewave-vodlist__thumb lazyload").find("span",class_="pic-tag pic-tag-h").text;
title = box.find("div",class_="ewave-vodlist__detail").find("h4",class_ = "title text-overflow").text;
stars = box.find("div",class_="ewave-vodlist__detail").find("p",class_ = "text text-overflow text-muted hidden-xs text-actor").text;
print(title, rating, stars)
执行之后,输出如下(截取了部分日志)。可以看到我们想要的信息是有了,但是却好像带了很多没必要的空格和换行。

针对抽取的结果出现空格和换行的问题,我们可以使用正则表达式来处理。
创建一个格式处理的函数:
import re
def remove_extra_spaces(string):
# 将连续的非空格字符与其前面的空格合并为一个单词
string = re.sub(' +',' ',string);
# 去除开头和结尾的空格、换行
string = string.strip().replace("\n","");
return string;
在我们上面打印语句中,主演的数据中调用一下这个函数,就可以按规则去掉空格和换行。
# 用tv1.html的内容创建BeautifulSoup对象
doc = create_doc_from_file("tvs_html/tv1.html");
# 查找class="ewave-vodlist__box" 的所有 div 标签
# 并以列表形式存储在 box_list 中
box_list = doc.find_all("div",class_="ewave-vodlist__box");
# 使用遍历循环遍历 box_list 中的所有标签对象
for box in box_list:
# 根据上述分析的思路,分别获取包含标题、评分、和演员信息的标签
rating = box.find("div",class_ = "ewave-vodlist__thumb lazyload").find("span",class_="pic-tag pic-tag-h").text;
title = box.find("div",class_="ewave-vodlist__detail").find("h4",class_ = "title text-overflow").text;
stars = box.find("div",class_="ewave-vodlist__detail").find("p",class_ = "text text-overflow text-muted hidden-xs text-actor").text;
print(title, rating, remove_extra_spaces(stars))
这回打印出来的数据格式就清爽很多了:

(2)提取多个HTML的内容
通过上述代码,我们已经可以将 tv1.html 文件中的所有电视剧信息给打印出来。但我们这次一共有一百多个 html 文件,要怎么实现处理多个 html 文件呢?
因为这一百个 HTML 文件虽然电视剧内容不一样,但是标签结构却是基本一样的(在电视剧网翻页的时候,可以看到每一页的样子都是一样的)。所以我们只需要将上面的代码放在循环中循环运行,然后每次循环都处理不同的 html 文件即可。
为了让代码更加清晰,我们先将上面的处理单个文件的代码改写为函数,参数就是要处理的 html 文件名,函数则命名为:get_tv_from_html。
# 从参数指定的 html 文件中获取电视剧的相关信息
def get_tv_from_html(html_file_name):
doc = create_doc_from_file(html_file_name);
box_list = doc.find_all("div",class_="ewave-vodlist__box");
for box in box_list:
rating = box.find("div",class_ = "ewave-vodlist__thumb lazyload").find("span",class_="pic-tag pic-tag-h").text;
title = box.find("div",class_="ewave-vodlist__detail").find("h4",class_ = "title text-overflow").text;
stars = box.find("div",class_="ewave-vodlist__detail").find("p",class_ = "text text-overflow text-muted hidden-xs text-actor").text;
# 将获取的三个变量打印出来,看看是否正确。
print(title, rating, remove_extra_spaces(stars))
# 试试用新写的函数处理一 tv2.html
get_tv_from_html("tvs_html/tv2.html")
调用后输出如下:

可以看到,我们成功用我们写的函数来从 tv2.html 中提取了电视剧的信息。这样要实现从一百多个文件中抽取信息,只需要写一个循环,来每次传给 get_tv_from_html 函数不同的文件名即可。【这里就不再放循环代码了,新手小伙伴可以试试自己来写,如果有问题可以联系。】
截止到现在,我们已经把网页下载下来了,并且把我们需要的内容抽取出来了,剩下的一步就是写到CSV中。
7、数据保存-将数据保存到CSV中
要将数据保存为 csv 的记录,我们首先需要将每一行数据保存为字典,然后以一个字典列表的形式传递给 csv 模块的 DictWriter。
(1)准备保存到CSV的函数
为了让后续代码更简洁,我们先将把字典列表保存到 csv 文件的操作写成一个函数。
# 导入 csv 模块
import csv
# 输入有三个参数:要保存的字典列表,csv 文件名,和表头
def write_dict_list_to_file(dict_list, filename, headers):
# 当要处理的网页比较复杂时,增加 encoding 参数可以兼容部分特殊符号
fo = open(filename, "w", newline="", encoding="utf-8")
writer = csv.DictWriter(fo, headers);
writer.writeheader();
writer.writerows(dict_list)
fo.close()
(2)创建电视剧字典列表
all_tv_dict = []
(3)改造 get_tv_from_html 函数
# 从参数指定的 html 文件中获取电视剧的相关信息
def get_tv_from_html(html_file_name):
doc = create_doc_from_file(html_file_name);
#【新增】当前处理的文件的字典列表
tv_list = [];
box_list = doc.find_all("div",class_="ewave-vodlist__box");
for box in box_list:
rating = box.find("div",class_ = "ewave-vodlist__thumb lazyload").find("span",class_="pic-tag pic-tag-h").text;
title = box.find("div",class_="ewave-vodlist__detail").find("h4",class_ = "title text-overflow").text;
stars = box.find("div",class_="ewave-vodlist__detail").find("p",class_ = "text text-overflow text-muted hidden-xs text-actor").text;
#【新增】使用字典来保存上面抽取的数据,字典的key和csv的表头保持一致
tv_dict = {}
tv_dict['title'] = title;
tv_dict['rating'] = rating;
tv_dict['stars'] = stars;
tv_list.append(tv_dict)
return tv_list
#【新增】调用修改后的程序
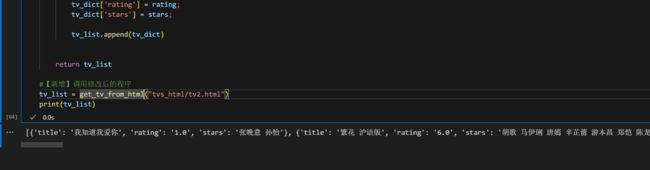
tv_list = get_tv_from_html("tvs_html/tv2.html")
print(tv_list)
运行后结果如下:
(4)获取所有文件的电视剧信息
目前,我们通过 get_tv_from_file 函数,已经可以获取单个 html 的电视剧列表,现在我们需要通过一个循环,去处理所有的 html。对于每一个 html 文件,获取字典列表之后,都把列表添加到我们的总列表:all_tv_dict 中。这样,在循环执行结束后,all_tv_dict 变量中就包含了所有电视剧的信息。
# 因为是处理 tv1- tv136 的文件,所以i 循环从1到136
for i in range(1, 136):
# 拼出每一次要处理的文件名
filename = "tvs_html/tv"+str(i)+".html";
# 调用 get_tv_from_html 处理当次循环的文件
# 将这个文件中的电视剧列表存储在 dict_list 变量
dict_list = get_tv_from_html(filename);
# 将 dict_list 的内容添加到总列表 all_tv_dict 中
# 列表的拼接可以直接使用 + 号
all_tv_dict = all_tv_dict + dict_list
# 打印出总列表的长度,看看我们一共抓取到了几部电视剧
print(len(all_tv_dict))
因为要用 BeautifulSoup 处理一百多个文件,这里执行会有点慢。需要耐心等一下,执行完毕后输出结果为 9270。
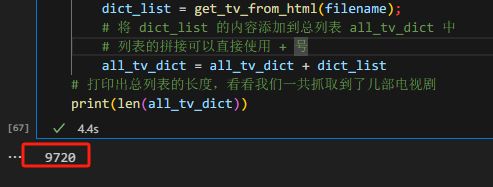
说明我们一共抓取了9270部电视剧。
(5)保存结果到 csv 文件中
在需求说明中,已经明确了要保存的 csv 文件名为:tv_rating.csv, 表头为:title, rating, stars。
现在,我们所有电视剧的信息都已经存储在 all_tv_dict 总列表中,现在我们只需要调用存储到 csv 的函数将其保存到 csv 文件即可。
# 调用之前准备的 write_dict_list_to_csv 函数
# 第一个参数为要保存的列表,这里就是我们存储了所有电视剧耳朵总列表 all_tv_dict
# 第二个参数为要保存的文件名
# 第三个参数为要保存的 csv 文件的表头
write_dict_list_to_file(all_tv_dict, "tv_rating.csv", ["title", "rating", "stars"]);
执行之后,没有内容输出,但是可以看到在源代码文件夹下已经生成了 tv_rating.csv 文件。
使用 Excel 打开该 csv 文件,可以看到我们的表头已经正确写入,表头对应的内容也已经正确写入。

至此,一份国产电视剧评分的数据集就制作完毕了。
更多精彩文章欢迎关注公众号:服务端技术精选