在Centos7上进行Trino 377的集群安装部署
目录
- 1. 集群规划
- 2. 安装依赖
- 3. 下载解压
- 4. 配置文件
-
- 4.1 服务器配置etc/config.properties
- 4.2 节点配置etc/node.properties
- 4.3 JVM配置etc/jvm.config
- 4.4 日志配置etc/logging.properties
- 5. 启动
- 6. 关闭
- 7. 查看Web UI
1. 集群规划
| 主机名 | 服务 |
|---|---|
| bigdata001 | coordinator |
| bigdata002 | worker |
| bigdata003 | worker |
2. 安装依赖
每台服务器安装Java11和Python3。其中Java11版本必须大于等于11.0.11,OpenJDK的版本不能满足,可以使用Azul提供的Zulu OpenJDK,这个也是免费使用的
如下所示进行检验:
[root@bigdata001 ~]#
[root@bigdata001 ~]# java -version
openjdk version "11.0.14.1" 2022-02-08 LTS
OpenJDK Runtime Environment Zulu11.54+25-CA (build 11.0.14.1+1-LTS)
OpenJDK 64-Bit Server VM Zulu11.54+25-CA (build 11.0.14.1+1-LTS, mixed mode)
[root@bigdata001 ~]#
[root@bigdata001 ~]# python3 --version
Python 3.10.1
[root@bigdata001 ~]#
3. 下载解压
在3台服务器上进行安装包下载,然后进行解压,再创建配置文件目录
[root@bigdata001 ~]#
[root@bigdata001 ~]# wget https://repo1.maven.org/maven2/io/trino/trino-server/377/trino-server-377.tar.gz
[root@bigdata001 ~]#
[root@bigdata001 ~]# tar -zxvf trino-server-377.tar.gz
[root@bigdata001 ~]#
[root@bigdata001 ~]# cd trino-server-377
[root@bigdata001 trino-server-377]#
[root@bigdata001 trino-server-377]# mkdir etc
[root@bigdata001 trino-server-377]#
[root@bigdata001 trino-server-377]# cd etc/
[root@bigdata001 etc]#
4. 配置文件
4.1 服务器配置etc/config.properties
coordinator的配置如下:
[root@bigdata001 etc]#
[root@bigdata001 etc]# cat config.properties
# 该节点是否作为coordinator
coordinator=true
# coordinator是否同时作为worker节点
node-scheduler.include-coordinator=false
# http连接端口
http-server.http.port=8080
# 所有节点查询可以使用的最大内存和
query.max-memory=3GB
# 单个节点查询可以使用的最大用户内存
query.max-memory-per-node=512MB
# 服务发现的地址
discovery.uri=http://bigdata001:8080
[root@bigdata001 etc]#
worker的配置如下,所以worker的配置需要一模一样
[root@bigdata002 etc]#
[root@bigdata002 etc]# cat config.properties
coordinator=false
http-server.http.port=8080
query.max-memory=3GB
query.max-memory-per-node=512MB
discovery.uri=http://bigdata001:8080
[root@bigdata002 etc]#
4.2 节点配置etc/node.properties
每个节点的node.id参数必须不一样
[root@bigdata001 etc]#
[root@bigdata001 etc]# cat node.properties
# 集群所有节点环境名称必须一样
node.environment=trino_cluster
# UUID, 36个16进制数字, 每个节点的都不一样, 默认随机生成, 设置固定值在集群升级时可以保持和原来的一致
node.id=a49c04c9-6642-11ec-acff-30d042079a38
# 日志文件和数据文件储存目录
node.data-dir=/root/trino-server-377/var
[root@bigdata001 etc]#
4.3 JVM配置etc/jvm.config
每个节点根据实际情况进行配置
[root@bigdata001 etc]#
[root@bigdata001 etc]# cat jvm.config
-server
-Xmx1G
-XX:-UseBiasedLocking
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+ExplicitGCInvokesConcurrent
-XX:+ExitOnOutOfMemoryError
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow
-XX:ReservedCodeCacheSize=64M
-XX:PerMethodRecompilationCutoff=10000
-XX:PerBytecodeRecompilationCutoff=10000
-Djdk.attach.allowAttachSelf=true
-Djdk.nio.maxCachedBufferSize=2000000
[root@bigdata001 etc]#
OutOfMemoryError会使JVM进入不一致状态,所以需要进行堆转储(heap dump)并强制退出,以便调试
4.4 日志配置etc/logging.properties
每个节点根据实际情况进行配置
[root@bigdata001 etc]#
[root@bigdata001 etc]# cat logging.properties
# 设置io.trino包的所有类(包括嵌套包的类, 如io.trino.spi.connector)的日志输出级别
io.trino=INFO
# 参数还可以设置为: DEBUG、ERROR
io.trino.plugin.mysql=WARN
[root@bigdata001 etc]#
5. 启动
启动顺序为先启动coordinator,再启动worker
[root@bigdata001 trino-server-377]#
[root@bigdata001 trino-server-377]# bin/launcher start
Started as 42972
[root@bigdata001 trino-server-377]#
[root@bigdata001 trino-server-377]# cat var/var/log/server.log | grep 'SERVER STARTED'
2021-12-27T09:42:19.473+0800 INFO main io.trino.server.Server ======== SERVER STARTED ========
[root@bigdata001 trino-server-377]#
[root@bigdata001 trino-server-377]# bin/launcher status
Running as 43901
[root@bigdata001 trino-server-377]#
使用bin/launcher run让进程前台运行,日志直接输出在控制台
6. 关闭
[root@bigdata001 trino-server-377]#
[root@bigdata001 trino-server-377]# bin/launcher stop
Stopped 43901
[root@bigdata001 trino-server-377]#
也可以用bin/launcher kill杀掉进程
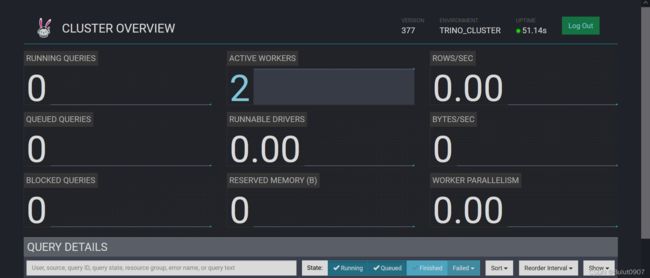
7. 查看Web UI
打开http://bigdata001:8080,输入用户:trino,不用输入密码,点击登录,显示如下: