c++ 关于那些莫名其妙 “不 coredump” 的思考
很多人都听过, 在某个地方删除一个 printf 的时候, 代码居然 coredump 了,
本文尝试对这些问题做一点思考。
基本代码
#include汇编
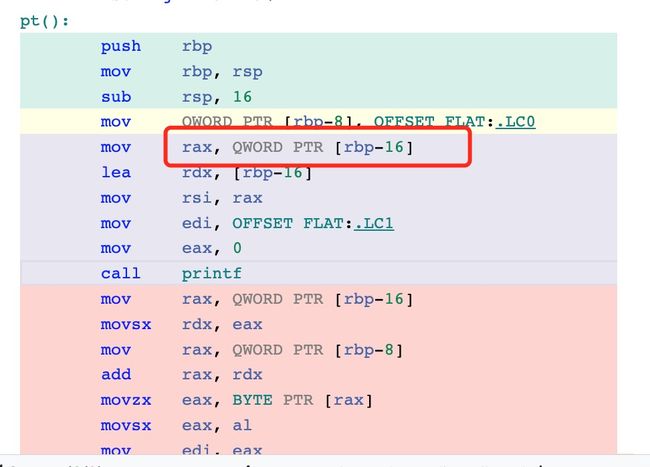
解释
在 pt() 内部, 我们没有对 a进行初始化, 从汇编来看,a 的值, 确实没有初始化,这时候a 的值是不确定的, 编译代码并运行, oops, coredump 了, 这个是符合预期的
怎么不 coredump
给出代码
#include编译运行这个代码, 发现 a 的值确实是 还是 coredump
但是 %d 输出a 是 1,为什么是 1
预备知识: 汇编函数参数存储的位置: rdi, rsi, rdx, rcx, r8, r9
当参数大于 6 个的时候, 参数直接存在栈上.
printf 的参数有 9 个, 导致 3, 2, 1 直接存储在栈上他们入栈的顺序是
在 64位系统上, 占用了 8 个字节
push 1 ; // 因为是小端存储, 导致大端的值是不确定的
push 2
push 3
我们回到
void test() {
init2();
pt();
}
可以知道 long long a 的地址和 push 1 使用的地址是一样的
所以导致了 %d 输出a 的时候值是 1, 而%d 的时候值不是 1
所以使用需要 int(a) 进行强转
其他方式一
可以发现 a 的值一直就是 0
#include其他方式二
这个例子 a = 3 和 e 的地址一样,
#include