SCI一区级 | Matlab实现EVO-CNN-BiLSTM-Mutilhead-Attention能量谷优化算法优化卷积双向长短期记忆神经网络融合多头注意力机制多变量多步时间序列预测
SCI一区级 | Matlab实现EVO-CNN-BiLSTM-Mutilhead-Attention能量谷优化算法优化卷积双向长短期记忆神经网络融合多头注意力机制多变量多步时间序列预测
目录
-
- SCI一区级 | Matlab实现EVO-CNN-BiLSTM-Mutilhead-Attention能量谷优化算法优化卷积双向长短期记忆神经网络融合多头注意力机制多变量多步时间序列预测
-
- 预测效果
- 基本介绍
- 程序设计
- 参考资料
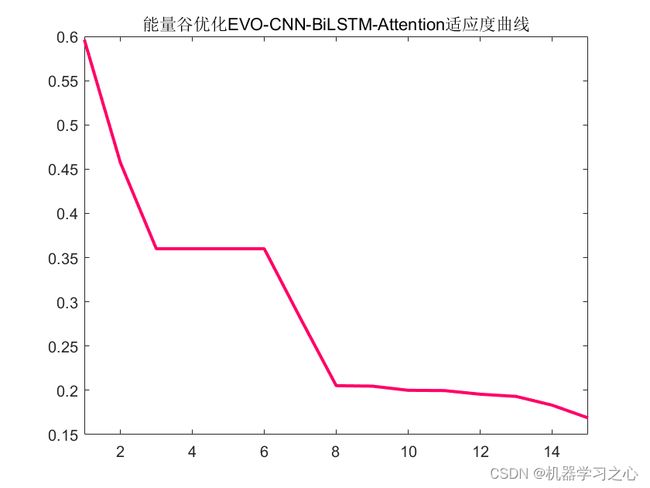
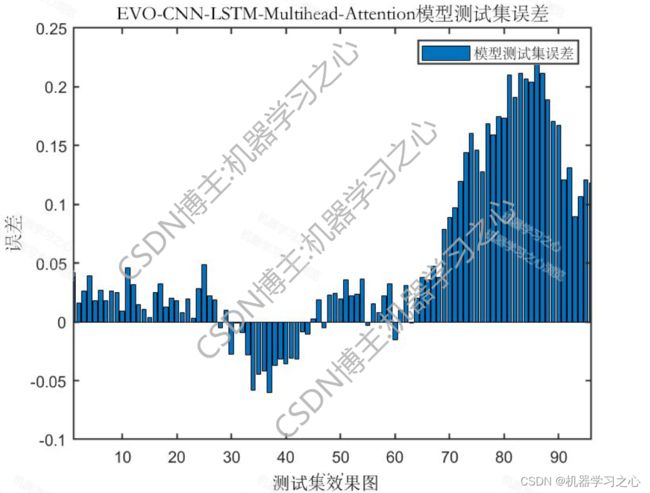
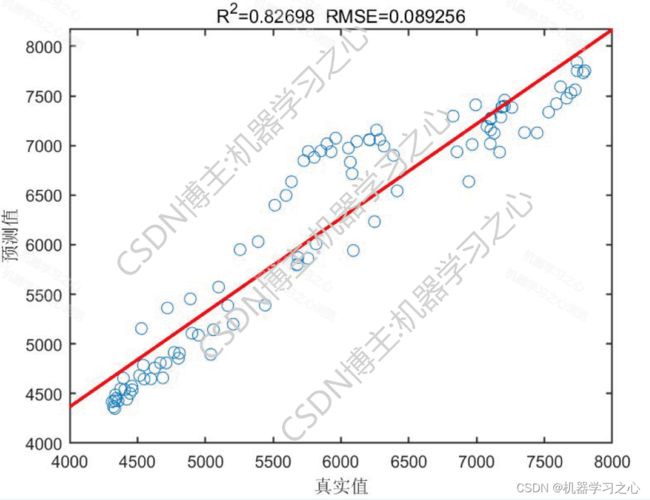
预测效果



基本介绍
1.Matlab实现EVO-CNN-BiLSTM-Mutilhead-Attention能量谷优化算法优化卷积双向长短期记忆神经网络融合多头注意力机制多变量多步时间序列预测,优化学习率,卷积核大小,神经元个数,以最小MAPE为目标函数;
CNN卷积核大小:卷积核大小决定了CNN网络的感受野,即每个卷积层可以捕获的特征的空间范围。选择不同大小的卷积核可以影响模型的特征提取能力。较小的卷积核可以捕获更细粒度的特征,而较大的卷积核可以捕获更宏观的特征。
BiLSTM神经元个数:BiLSTM是一种适用于序列数据的循环神经网络,其神经元个数决定了模型的复杂性和记忆能力。较多的BiLSTM神经元可以提高模型的学习能力,但可能导致过拟合。
学习率:学习率是训练深度学习模型时的一个关键超参数,它控制每次参数更新的步长。学习率过大可能导致模型不稳定和发散,学习率过小可能导致训练过慢或陷入局部最小值。
多头自注意力层 (Multihead-Self-Attention):Multihead-Self-Attention多头注意力机制是一种用于模型关注输入序列中不同位置相关性的机制。它通过计算每个位置与其他位置之间的注意力权重,进而对输入序列进行加权求和。注意力能够帮助模型在处理序列数据时,对不同位置的信息进行适当的加权,从而更好地捕捉序列中的关键信息。在时序预测任务中,注意力机制可以用于对序列中不同时间步之间的相关性进行建模。
能量谷优化算法(Energy valley optimizer,EVO)是2023年提出的一种新颖的元启发式算法。EVO算法的灵感来自于宇宙中粒子的行为,特别是这些粒子的稳定性和衰变过程。大多数粒子不稳定,倾向于通过分解或衰变来释放能量,而少数粒子则能无限期地保持稳定。
2.运行环境为Matlab2023a及以上,提供损失、RMSE迭代变化极坐标图;网络的特征可视化图;测试对比图;适应度曲线(若首轮精度最高,则适应度曲线为水平直线);
3.excel数据集(负荷数据集),输入多个特征,输出单个变量,考虑历史特征的影响,多变量多步时间序列预测(多步预测即预测下一天96个时间点),main.m为主程序,运行即可,所有文件放在一个文件夹;

4.命令窗口输出SSE、RMSE、MSE、MAE、MAPE、R2、r多指标评价,适用领域:负荷预测、风速预测、光伏功率预测、发电功率预测、碳价预测等多种应用。

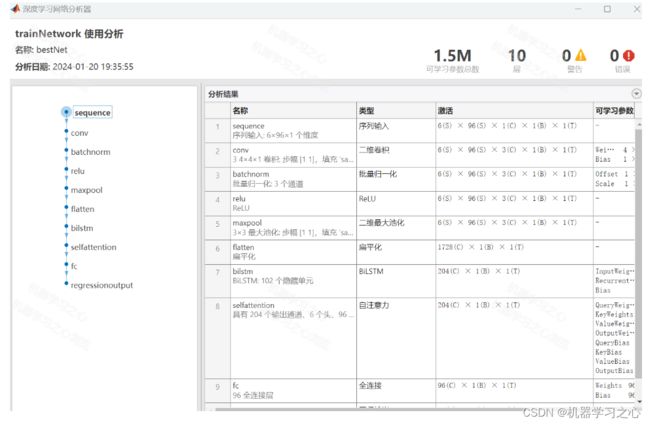




程序设计
- 完整源码和数据获取方式:私信博主回复Matlab实现EVO-CNN-BiLSTM-Mutilhead-Attention多变量多步时序预测。
%% 清除内存、清除屏幕
clc
clear
%% 导入数据
data = xlsread('负荷数据.xlsx');
rng(0)
%% 数据分析
daynum=30; %% 数据量较大,选取daynum天的数据
step=96; %% 多步预测
data =data(end-step*daynum+1:end,:);
W_data = data(:,end)'; %% 实际值输出:每天24小时,每小时4个采样点
%% 数据归一化
[features, ~] = mapminmax(Features, 0, 1);
[w_data, ps_output] = mapminmax(W_data, 0, 1);
%% 数据平铺为4-D
LP_Features = double(reshape(features,fnum,step,1,daynum)); %% 特征数据格式
LP_WindData = double(reshape(w_data,step,1,1,daynum)); %% 实际数据格式
%% 格式转换为cell
NumDays = daynum; %% 数据总天数为daynum天
for i=1:NumDays
FeaturesData{1,i} = LP_Features(:,:,1,i);
end
for i=1:NumDays
RealData{1,i} = LP_WindData(:,:,1,i);
end
%% 划分数据
XTrain = FeaturesData(:,1:daynum-2); %% 训练集输入为 1-(daynum-2)天的特征
YTrain = RealData(:,2:daynum-1); %% 训练集输出为 2-(daynum-1)天的实际值
%% 初始化
Particles=[]; NELs=[];tsmvalue={};
for i=1:nParticles
Particles(i,:)=unifrnd(VarMin,VarMax,[1 VarNumber]);
[NELs(i,1),tsmvalue{i,1},Net{i,1},Info{i,1}]=CostFunction(Particles(i,:));
FEs=FEs+1;
end
% 对粒子进行排序
for a = 1:size(NELs,1)
cellNEL{a,1} = NELs(a,:);
end
Mixdata=[cellNEL,tsmvalue,Net,Info];
sortedData = sortrows(Mixdata, 1);
[NELs, SortOrder]=sort(NELs);
Particles=Particles(SortOrder,:);
BS=Particles(1,:);
BS_NEL=NELs(1); %% 最优的误差结果
WS_NEL=NELs(end); %% 最差的误差结果
BS_PD=sortedData(1,2); %% 最小误差对应的预测结果
BS_NT=sortedData(1,3); %% 最小误差对应的网络
BS_IF=cell2mat(sortedData(1,4)); %% 最小误差对应的训练曲线
valubest=sortedData(:,2);
netbest=sortedData(:,3);
infobest=sortedData(:,4);
%% 主循环
while FEs<MaxFes
Iter=Iter+1;
NewParticles=[];
NewNELs=[];
Tsmvalues={};
NewNets={};
NewInfos={};
for i=1:nParticles
Dist=[];
for j=1:nParticles
Dist(j,1)=distance(Particles(i,:), Particles(j,:));
end
[ ~, a]=sort(Dist);
CnPtIndex=randi(nParticles);
if CnPtIndex<3
CnPtIndex=CnPtIndex+2;
end
CnPtA=Particles(a(2:CnPtIndex),:);
CnPtB=NELs(a(2:CnPtIndex),:);
X_NG=mean(CnPtA);
X_CP=mean(Particles);
EB=mean(NELs);
SL=(NELs(i)-BS_NEL)/(WS_NEL-BS_NEL); SB=rand;
if NELs(i)>EB
参考资料
[1] https://blog.csdn.net/kjm13182345320/article/details/128577926?spm=1001.2014.3001.5501
[2] https://blog.csdn.net/kjm13182345320/article/details/128573597?spm=1001.2014.3001.5501