Linux 部署Hadoop伪分布式集群教程
首先:我们需要下载一些关于Hadoop伪分布式集群需要的工具与tar包
链接:
https://pan.baidu.com/s/1oUw1jDCxfghWsnaWauSHKg
提取码:6s5a
接下来打开虚拟机终端,先创建一个文件夹用来解压Hadoop的tar包

接着使用xshell远程连接到虚拟机传输Hadoop的tar包(不会使用xshell可以参考这篇文章)http://t.csdn.cn/2fJ9m
 输入命令:tar -zvxf hadoop-3.3.0 tar.gz开始解压tar包
输入命令:tar -zvxf hadoop-3.3.0 tar.gz开始解压tar包

接下来输入命令:ll就可以查看我们解压好的文件hadoop-3.3.0

接下来我们需要创建一个空文件夹hadooptmp用来装hadoop格式化hdfs时产生文件

紧接着我们需要进入hadoop文件下编辑hadoop-env.sh配置jdk的路径(黑色背景的图片为在xhell中操作的命令直接在虚拟机的终端中输入命令也可以)
 在hadoop-env.sh中加入export JAVA_HOME=/.../..(这里的自己安装的jdk的路径)
在hadoop-env.sh中加入export JAVA_HOME=/.../..(这里的自己安装的jdk的路径)
 接下来我们需要配置四个文件,第一个是 core-site.xml,输入命令: vim core-site.xml
接下来我们需要配置四个文件,第一个是 core-site.xml,输入命令: vim core-site.xml

进入 core-site.xml之后配置以下内容

第二个需要配置的文件是hdfs-site.xml,输入命令 vim hdfs-site.xml
 进入后输入配置内容:
进入后输入配置内容:
 第三个需要配置的文件为mapred-site.xml输入命令:vim mapred-site.xml进行配置
第三个需要配置的文件为mapred-site.xml输入命令:vim mapred-site.xml进行配置
 进入文件后输入配置内容
进入文件后输入配置内容
 第四个文件是yarn-site.xml输入命令 :vim yarn-site.xml进行配置
第四个文件是yarn-site.xml输入命令 :vim yarn-site.xml进行配置
 配置内容为:
配置内容为:

接下来我们需要编辑workers中的内容,输入命令:vim workers进入编辑
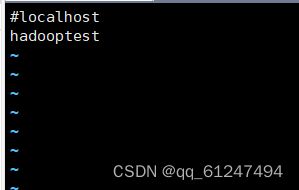
 把localhost注释掉(前面加入#),然后加入自己的主机名(hadooptest是我的主机名)
把localhost注释掉(前面加入#),然后加入自己的主机名(hadooptest是我的主机名)
紧接着我们开始配置环境变量,输入命令:vim ~/.bash_profile

进入后输入内容
expoet JAVA_HOME=.....(自己的jdk的安装路径)
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=.....(自己的hadoop安装路径)
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH

配置好环境变量之后记得输入命令:source ~/.bash_profile 加载环境变量使环境变量生效
 接下来我们需要格式化hdfs输入命令:hadoop namenode -format
接下来我们需要格式化hdfs输入命令:hadoop namenode -format

格式化完成之后输入命令:start-all.sh启动hadoop
 启动完成之后输入命令:jps查看启动正在进行的进程(除jps之外中共有五个进程)
启动完成之后输入命令:jps查看启动正在进行的进程(除jps之外中共有五个进程)

接着进入浏览器中输入192.168.0.107:9870进行访问(192.168.0.107为自己虚拟机配置的IP地址)
 再把9870改为8088就会出现访问如图所示网页
再把9870改为8088就会出现访问如图所示网页
 这样Hadoop部署伪分布式集群就部署完成了!!!
这样Hadoop部署伪分布式集群就部署完成了!!!