【数据库】聊聊InnoDB存储引擎结构
在学习任何技术、框架、中间件的时候,我们都需要从一个宏观的角度先去了解一下大概视角,然后在通过剖定解牛的方式进行细分点的学习,同样对于任何存储结构来说,基本上都包含几块内容。
通信:解决信息传输问题、存储模型:是采用B+树、还是LSM等。高可用、高性能等。本篇主要从InnoDB切入,了解,一行数据在InnoDB中是如何存储的。
MySQL逻辑架构
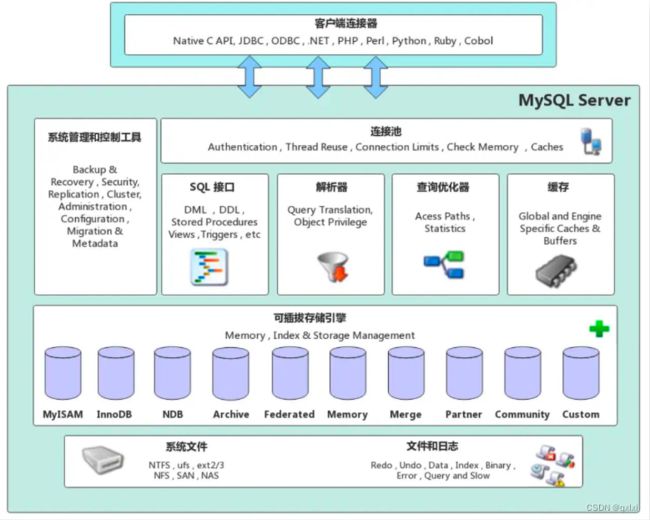
InnoDB架构
从架构上可以看出,主要分的是内存结构和磁盘结构,内存结构其实就是在内存中存储数据的形式。
内存结构:缓冲池 (buffer pool、change buffer)、自适应哈希索引、日志缓冲
磁盘结构:系统表空间、独立表空间,通用表空间等
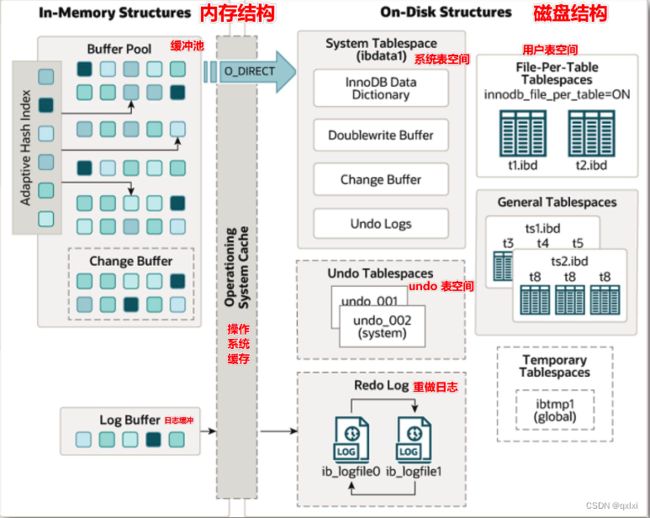
内存结构
buffer pool 缓冲池 主要用于加速数据的访问和修改。默认128M。减少磁盘IO,加速热点数据的读和写。通常有内存淘汰算法LRU。
change buffer : 加速非热点数据中二级索引的写入操作,修改会落入redo log中。定期进行marge。
自适应哈希索引:用于实现对热数据页的一次查询,建立在索引智商的索引。大小是 buffer pool的1/64。
Log buffer : 缓冲日志文件的写入操作,顺序写入。 buffer pool -> log buffer -> os buffer -> redo log
磁盘空间
上面简单描述了在内存中的结构,那么在磁盘中,是如何组织数据结构的。大多数的新手都会认为,数据库只存储数据和索引,其实不然,还存储表结构以及其他的缓存信息。而这个地方就是表空间。有段、区、页、行组成。
常见的表空间:
系统表空间:关闭独立表空间,所有表数据和索引都会存入系统表空间。
独立表空间:开启独立表空间,每张表都会写入独立表空间。
通用表空间:为了在系统表空间与独立表空间之间作出平衡
存储结构
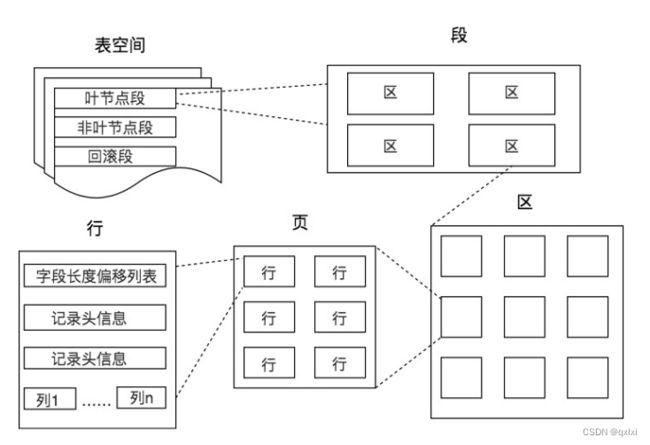
段:表空间由多个段组成,数据段、索引段、回滚段。数据段是叶子结点,索引段是非叶子结点。
区:连续的页组成,大小是1MB,默认是64个页组成。
页:页是InnoDB的基本存储单位,默认是16K。操作系统读写磁盘的最小单位是页,4K。
行:数据以行为单位存储,一页包含多行。有不同的行格式、默认是Dynamic。
-- innodb的表空间类型 innodb_file_per_table=ON,这就意味着每张表都会单独保存为一个.ibd 文件
show variables like 'innodb_file_per_table';
-- 页大小
show variables like '%innodb_page_size%';
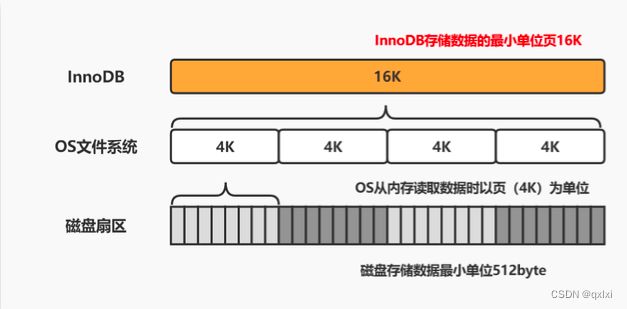
数据页结构
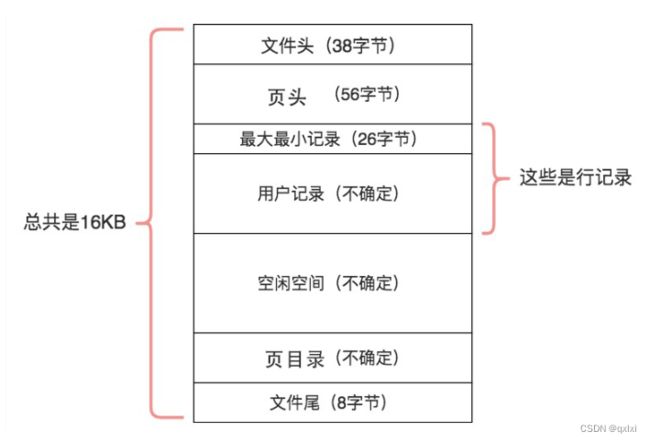
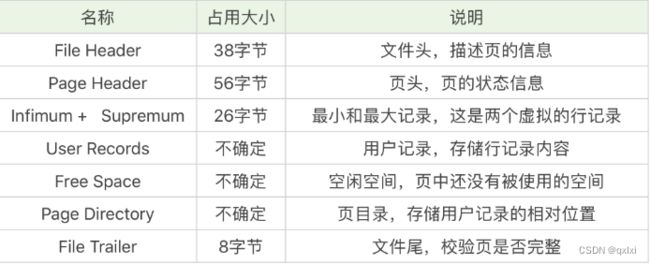
实际上我们进行划分为3部分。
文件通用部分: 文件头和文件尾。将页的内容进行封装,通过文件头和文件尾校验的方式来确保页传输是完整的。
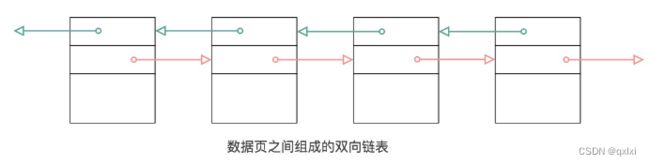
文件头有两个字段,FIL_PAGE_PREV、FIL_PAGE_NEXT.他们的作用相当于指针,分别指向上一个数据页和下一个数据页。形成一个双向链表。
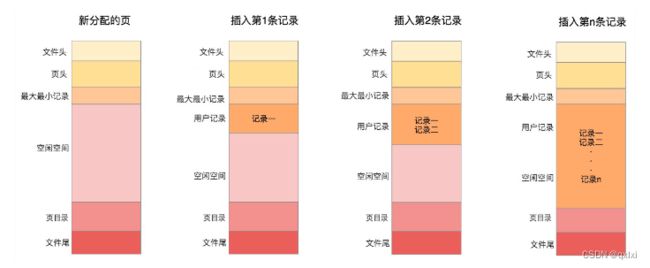
记录部分:主要作用是存储记录,第三部分基友说页目录,记录的是索引的记录,通过二分查找。
内存中的数据如何进入磁盘
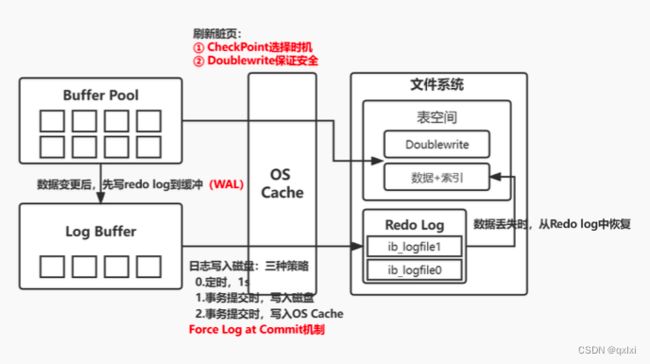
在修改一条数据的时候,其实是先从磁盘获取数据或者从buffer pool中,然后写入 undo log、更新buffer pool数据,使用两阶段提交修改redo log\bin log。但是写入buffer pool中的数据以及redo log都是先写入内存中的,并没有写入磁盘。
为什么要这样设计?如何保证数据被持久化的?

脏页
当我们将数据更新到 buffer pool中,此时这个数据对应的页和磁盘中的页 数据不一致,那么就成为脏页。将更新的数据写入磁盘的过程,是通过checkPoint 机制实现的。
提升性能:内存中写,顺序写入日志,在批量写入磁盘
持久化数据:checkpoint 机制进行脏页落盘,日志先行,先写redo log、force Log at Commit
安全性保证:两阶段提交、WAL、check point机制,double write机制
为什么不直接写入磁盘
因为对于数据的操作,有很多的随机IO,而随机IO的性能是非常低。所以为了提升性能,采用顺序IO,也就是通过WAL 以及force Log at Commit 来保证数据可以有效持久化到磁盘。而redo log的同步磁盘策略,使用了3种不同的机制,需要我们根据自己业务场景进行决定。数据丢失与性能之间权衡。而Redis中AOF机制,也有appendfsync对应的策略。你看都是相同的思想。
【Redis】聊一下持久化机制-AOF
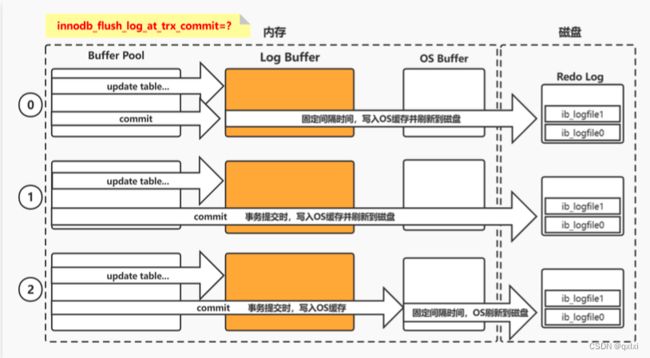
- redo log写入磁盘的时机
- 0.定时写入,每个1s中,同步一次。
- 最多丢失1s的事务操作,写入效率高,安全性最低。
- 1.事务提交时,写入磁盘。
- 不会丢失数据,但是写入效率低
- 2.事务提交时,写入os cache
- 依赖于系统,安全性剧中。
- 0.定时写入,每个1s中,同步一次。
# 查看写入时机参数配置
show VARIABLES like 'innodb_flush_log_at_trx_commit';
checkPoint机制
checkPoint是将缓冲池中脏页数据刷到磁盘上的机制,决定脏页落盘的时机,条件选择。
可以通过如下命令来观察。
show engine innodb status;
方式
- sharp checkpoint:关闭数据库时将脏页全部刷新到磁盘中
- fuzzy checkpoint:默认方式,在运行时选择不同时机将脏页刷盘,只刷新部分脏页
- Master Thread Checkpoint:异步操作,固定频率刷新。
- FLUSH_LRU_LIST Checkpoint:缓冲池淘汰非热点Page,如果该Page是脏页会执行CheckPoint
- Async/Sync Flush Checkpoint:redo log不可用时,强制刷新。
- Dirty Page too much Checkpoint:达到一定阈值
show variables like 'innodb_max_dirty_pages_pct';查看阈值
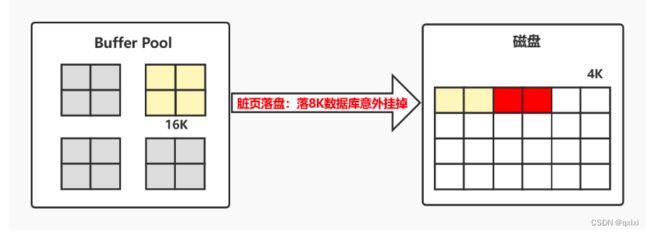
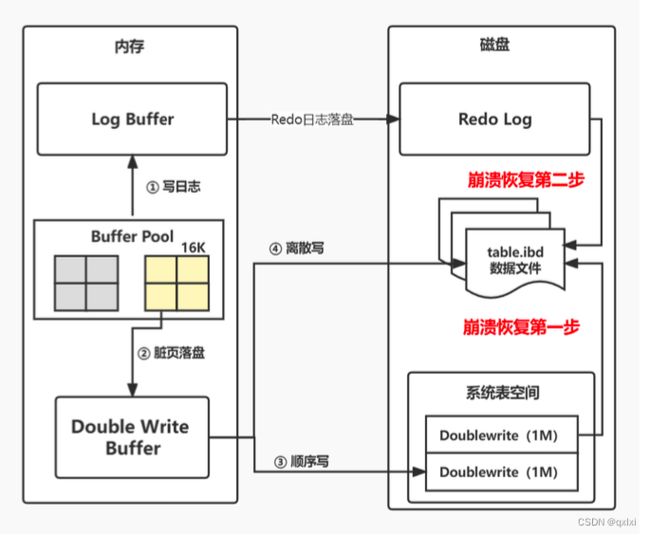
DoubleWrite机制
因为InnoDB是16KB一页,但是如果只写了一半的数据8KB,系统宕机怎么办? 这个其实就是写失效Partial Page Write
redo log不能解决写失效问题,因为redo log日志记录的是对页的修改记录而不是数据本身。
**核心流程:**其实先进行将数据复制到Double Write Buffer中, 然后在顺序写入系统表空间和离散写入磁盘。
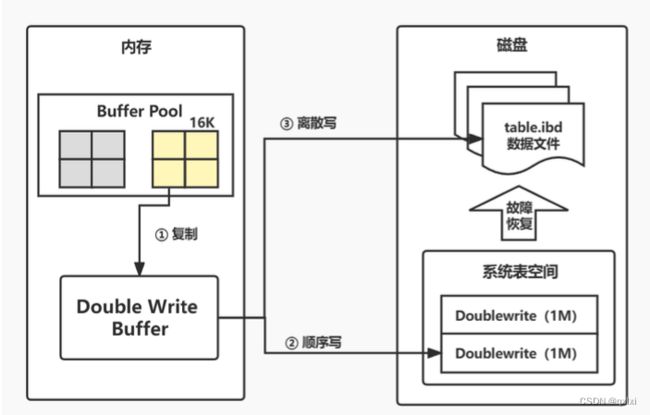
当系统故障的时候,通过找到系统表空间Dubble Write区域对应的页副本数据,将其复制到独立表空间。
总结
本篇从InnoDB存储结构分析,系统表空间->段->区->页->行。然后接着介绍了数据是如何写入磁盘中,以及引出的脏页问题,通过check point解决。但是check point 没有办法针对 写失效问题解决。索引引出了双写机制。
其实从设计点上,我们可以分析出,设计一个存储中间件的目的其实就是通过各种方式保证数据的安全,以及高可用,高性能。从中我们可以学到WAL 机制、异步刷盘操作等。
这里顺便总结下,其实从MySQL角度来看的话,其实就是
- InnoDB存储结构
- 索引优化
- 事务机制 MVCC等
- 锁机制
- 日志分类
- 读写分离、分库分表
总这几点出发,就可以很快掌握面试重点以及掌握MySQL。