一篇文章让你了解Mysql的InnoDB存储引擎中的锁!
本文主要内容:
介绍InnoDB中的锁的类型(X、S、IX、IS)。
解释为什么引入意向锁
行锁的三种算法:Record Lock,Gap Lock,Next-key Lock
一、InnoDB存储引擎中的锁
锁,在现实生活中是为我们想要隐藏于外界所使用的一种工具。在计算机中,是协调多个进程或县城并发访问某一资源的一种机制。在数据库当中,除了传统的计算资源(CPU、RAM、I/O等等)的争用之外,数据也是一种供许多用户共享访问的资源。如何保证数据并发访问的一致性、有效性,是所有数据库必须解决的一个问题,锁的冲突也是影响数据库并发访问性能的一个重要因素。从这一角度来说,锁对于数据库而言就显得尤为重要。
相对于其他的数据库而言,MySQL的锁机制比较简单,最显著的特点就是不同的存储引擎支持不同的锁机制。根据不同的存储引擎,MySQL中锁的特性可以大致归纳如下:

这里锁的对象是事务,用来锁定数据库中的对象,如:表、页、行。并且一般锁的对象仅在事务commit或rollback后进行释放。并且有死锁机制。
下面我们看InnoDB存储引擎中两种标准的行级锁:
-
共享锁(S Lock),允许事务读一行数据
-
排它锁(X Lock),允许事务删除或更新一行数据
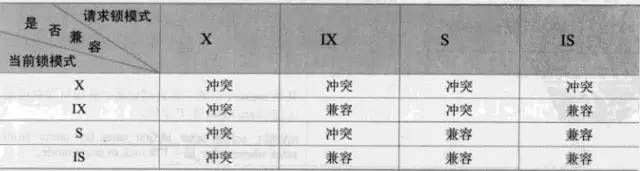
若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
若事务T对数据对象A加上X锁,事务T可以读A也可以修改A,其他事务不能再对A加任何锁,直到T释放A上的锁。
上述情况称为锁不兼容。
此外,InnoDB存储引擎还支持多粒度锁定,这种锁定允许事务在行级上的锁和表级上的锁同时存在。为了支持在不同粒度上进行加锁操作,InnoDB存储引擎支持一种额外的锁方式,称之为意向锁。
所谓意向锁,就是将要锁定的对象分成多个层次,意向锁意味着事务希望在更细粒度上进行加锁。如果把上锁的对象看成树形结构(从根到叶为从粗粒度到细粒度的顺序),那么对最下层的对象上锁,必须先对他的上层节点上锁。
举个例子,比如事务T要对某一行R1加X锁,必须先对R1所在的表T1加意向锁IX(Intention X Lock)。相应的也有IS(Intetion S Lock)锁。
刚开始我也是很懵的,不知道引入意向锁到底是干嘛的。后来再刷书的时候,才豁然开朗。下面我谈下我的理解。
因为引入意向锁是用来实现多粒度锁定的,即行锁和表锁同时存在。我们看看如果不引入意向锁,怎么判断。
如果事务T要对表T1加X锁,那么这是就必须要判断T1表下的每一行记录是否加了S锁或X锁(因为上面提到了锁有不兼容性)。这样做效率无疑很低。那么引入意向锁之后呢?
如果事务T要对表T1加X锁,在这之前,已经有事务对表T1中的行记录R加了S锁,那么此时在表T1上有IS锁,当事务T对表T1准备加X锁时,由于X锁与IS锁不兼容(关于兼容性后面会给出表格),所以事务T要等待行锁操作完成。你看,这样就省去了遍历的操作,提升了锁定父节点(本例为表T1)的效率。
下图就是X、S、IX、IS锁的兼容性了:
二、锁的算法
InnoDB存储引擎有3种行锁的算法,分别是:
-
Record Lock:单个行记录上的锁
-
Gap Lock:间隙锁,锁定一个范围,但不包含记录本身
-
Next-Key Lock:Gap Lock+Record Lock,锁定一个范围,并且锁定记录本身。
举例说明:
假如一个索引有10,11,13,20这四个值。那么该索引可能被Next-Key Locking的区间为:
(-∞,10]
(10,11]
(11,13]
(13,20]
(20,+∞)
注
对于Next_Key Lock,如果我们锁定了一个行,且查询的索引含有唯一属性时(即有唯一索引),那么这个时候InnoDB会将Next_Key Lock优化成Record Lock,也就是锁定当前行,而不是锁定当前行加一个范围;如果我们使用的不是唯一索引锁定一行数据,那么此时InnoDB就会按照本来的规则锁定一个范围和记录。还有需要注意的点是,当唯一索引由多个列组成时,如果查询仅是查找其中的一个列,这时候是不会降级的。还有注意的点是,InnoDB存储引擎还会对辅助索引的下一个键值区间加上gap lock(这么做也是为了防止幻读)。Next_Key Lock是为了解决数据库出现幻读的问题。
关于如何加锁详见我的这篇文章:Mysql的一致性非锁定读和一致性锁定读
有关脏读、不可重复读、幻读详见我的这篇文章浅析Mysql的隔离级别及MVCC
InnoDB存储引擎默认的事务隔离级别是RR级别,即可重复读。在该级别下,采用next-key locking的方式加锁。故而可以防止幻读现象。
举例一下,为什么next-key locking 可以解决幻读问题吧:
所谓幻读,就是在同一事务下,连续执行两次同样的SQL语句可能导致不同的结果,第二次的SQL语句可能会返回之前不存在的行。
创建表t:
create table t (a int primary key);
insert into t select 1;
insert into t select 2;
insert into t select 5;
这时有三行记录,分别是1,2,5。
假设有如下执行序列:
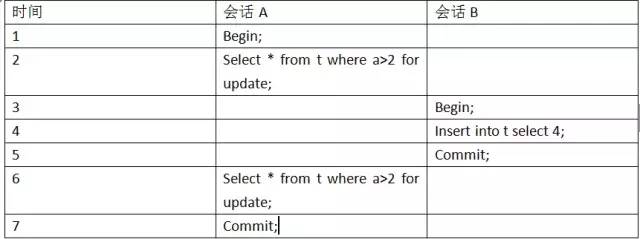
我们分析一下,会话A在时间2查询的结果为5,由于使用了select…for update语句,为(2,+∞)这个范围加了X锁。因此任何对于这个范围的插入都是不被允许的,由于4在这个范围,所以不允许插入,也就避免了幻读。
参考资料
《mysql技术内幕–InnoDB存储引擎》
这里是每天都很困的JAVA爱好者,如果您跟我一样每天睡不饱却依然热爱JAVA!
那就关注我吧!
言尽于此,完结
无论是一个初级的 coder,高级的程序员,还是顶级的系统架构师,应该都有深刻的领会到设计模式的重要性。
- 第一,设计模式能让专业人之间交流方便,如下:
程序员A:这里我用了XXX设计模式
程序员B:那我大致了解你程序的设计思路了
- 第二,易维护
项目经理:今天客户有这样一个需求…
程序员:明白了,这里我使用了XXX设计模式,所以改起来很快
- 第三,设计模式是编程经验的总结
程序员A:B,你怎么想到要这样去构建你的代码
程序员B:在我学习了XXX设计模式之后,好像自然而然就感觉这样写能避免一些问题
- 第四,学习设计模式并不是必须的
程序员A:B,你这段代码使用的是XXX设计模式对吗?
程序员B:不好意思,我没有学习过设计模式,但是我的经验告诉我是这样写的
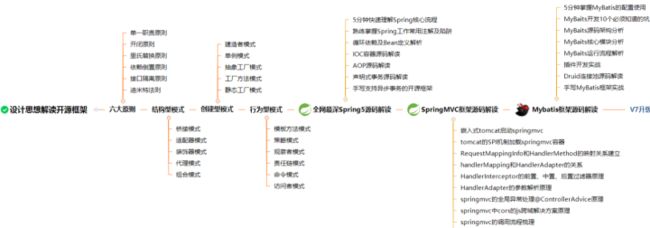
从设计思想解读开源框架,一步一步到Spring、Spring5、SpringMVC、MyBatis等源码解读,我都已收集整理全套,篇幅有限,这块只是详细的解说了23种设计模式,整理的文件如下图一览无余!
资料领取方式:点击这里下载
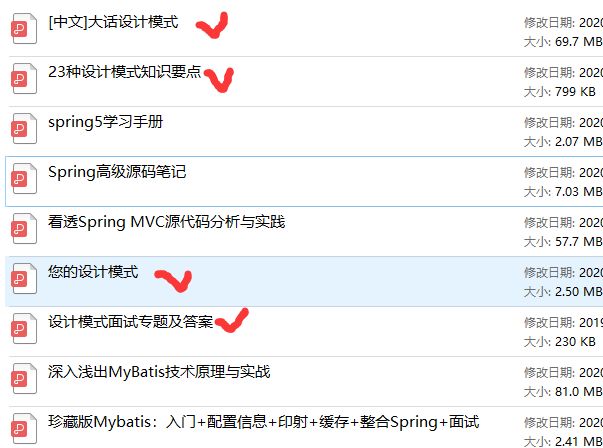
解说了23种设计模式,整理的文件如下图一览无余!
资料领取方式:点击这里下载
[外链图片转存中…(img-LLxq35an-1623611775679)]
搜集费时费力,能看到此处的都是真爱!