wireshark:文件输入、输出和打印
引言
wireshark针对捕获到的数据,可以:
- 以各种捕获文件格式打开捕获文件
- 以各种格式保存和导出捕获文件
- 将捕获文件合并到一起
- 导入包含十六进制数据报转储的文本文件
- 打印数据包
打开捕获文件
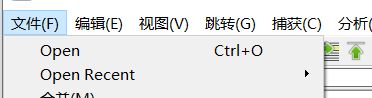
wireshark可以读取以前保存的文件。方法有二:
- 菜单栏的“文件->Open”或者工具栏
- 在文件管理器中拖动文件并将其放到Wireshark的主窗口中,就可以打开该文件。
“打开捕获文件”对话框
作用: 打开要查看的捕获文件
“打开捕获文件”对话框允许您搜索以前捕获的数据包的捕获文件,以便在wireshark中显示。

- “文件名”:选择一个文件就会自动填充这里
- “文件类型”:根据后缀名筛选可以选择的文件
- “打开”:打开选中的文件
- “取消”:返回到wireshark而不加载文件
- “帮助”:进入用户指南
- 查看文件预留信息,比如所选捕获文件中的数据包大小和数量
- “Read filter”:指定一个读取筛选器
- 此筛选器将在打开新文件时使用。
- 对于有效筛选器字符串,文本字段背景将变为绿色;对于无效筛选器字符串,文本字段背景将变为红色。
- 读取筛选器可用于排除各种类型的流量,这对于大的捕获文件非常有用。
- 它们使用与显示筛选器相同的语法
- “Automatically detect file type”:使用“Automatically detect file type”下拉列表强制wireshark将文件作为特定类型读取
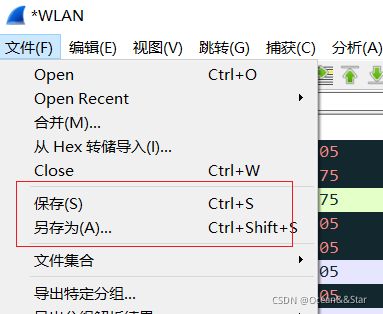
保存捕获的数据包
通过菜单栏【File → Save or File → Save As…】选择将数据报保存到某个文件中。
作用
- 将当前捕获保存到文本
- 如果您已经保存了当前捕获,此菜单项将变灰。
- 正在进行捕获时,无法保存实时捕获。你必须停止捕获才能保存。
保存 VS 另存为:
- 另存为是将当前的文本另存到一个文件中
并不是所有的信息都将保存在捕获文件中。比如,大多数文件格式不记录丢弃的数据包的数量
“将不会文件另存为”对话框

- “帮助”按钮将进入“用户指南”的这一部分
- “保存”按钮接收并保存所选文件
- “取消”按钮将返回wireshark而不保存任何数据包
- “Compress with gzip”将压缩正在写入磁盘的捕获文件。
wireshark可以将数据包数据以其本机文件格式(pcapng)和其他协议分析器的文件格式保存,以便其他工具可以读取不会数据
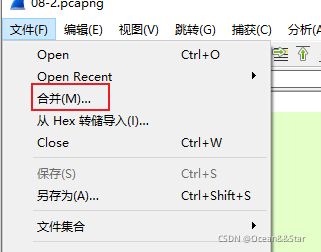
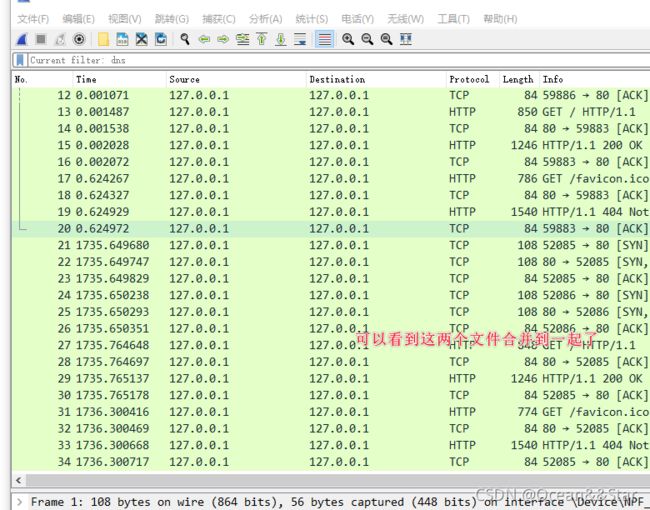
合并捕获文件
作用:将捕获文件合并到当前加载的文件中(多个捕获文件合并为一个)
有三种方法:
- 使用【File-Merge】菜单打开“合并”对话框。此菜单项将被禁用,除非您已经加载了捕获文件。
- 使用拖放在主窗口上拖放多个文件。Wireshark将尝试按照时间顺序将丢弃文件中的数据包合并到一个新创建的临时文件中。如果您删除一个文件,它将简单地替换现有的捕获。
- 从命令行使用mergecap工具合并捕获文件。此工具提供了合并捕获文件的大多数选项。
“合并捕获文件”对话框
这允许你选择要合并到当前加载的文件中的文件。如果你的当前数据尚未保存,系统会要求你先保存它。
有三种合并方式:
- Prepend packets(预先准备数据包):将所选文件的数据包放在当前加载的数据包之前
- Merge chronologically(按时间顺序合并):按照时间顺序合并选定文件和当前加载文件中的数据包
- Append packets(附加数据包):将选定文件中的数据包附加到当前加载的数据包之后

实践
操作1
注意:如果正在捕获流量,那么这个功能是禁用的

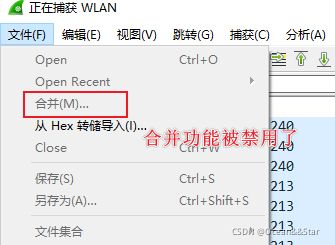
操作2

导入十六进制转储
作用:将包含十六进制转储的文本文件导入到新的临时捕获中
- wireshark可以读取十六进制转储,并将描述的数据写入到一个临时的libpcap捕获文件。
- 它可以读取包含多个包的十六进制转储文件,并构建多个包的捕获文件。
- 它还能够生成虚拟的以太网、IP和UDP、TCP或SCTP报头,以便仅从应用程序级数据的hexdumps构建完全可处理的包转储。
- 或者,可以添加一个Dummy PDU头来指定数据最初应该传递到的分析器。
支持两种转换输入的方法
标准ASCII十六进制转储
wireshark可以理解od -Ax -tx1 -v.格式的hexdump。换句话来说,每个字节都被单独显示,并被一个空格包围。每一行以一个偏移量开始,描述包中的位置,每个新包以0空为,并且有一个空格将偏移量与下面的字节分开。偏移量是一个十六进制数字(也可以是八进制或者十进制),超过两个十六进制数字。下面是可以可以导入的转储示例:
000000 00 e0 1e a7 05 6f 00 10 ........
000008 5a a0 b9 12 08 00 46 00 ........
000010 03 68 00 00 00 00 0a 2e ........
000018 ee 33 0f 19 08 7f 0f 19 ........
000020 03 80 94 04 00 00 10 01 ........
000028 16 a2 0a 00 03 50 00 0c ........
000030 01 01 0f 19 03 80 11 01 ........
对每行的宽度或字节数没有限制。此外,该行末尾的文本转储将被忽略。字节和十六进制数字可以是大写或小写。偏移量之前的任何文本将被忽略,包括电子邮件转发字符>。字节串行之间的任何文本行都将被忽略。偏移量用于跟踪字节,因此偏移量必须正确。任何只有字节而没有前导偏移量的行将被忽略。偏移量被识别为长度超过两个字符的十六进制数字。任何字节之后的文本将被忽略(例如字符转储)。此文本中的任何十六进制数字也会被忽略。偏移量为0表示开始一个新包,因此一个包含一系列hexdump的文本文件可以转换为一个包含多个包的包捕获。信息包的前面可以有一个时间戳。这些都是根据给出的格式来解释的。如果不是,则第一个包的时间戳是当前时间,导入就会发生。多个包的时间戳各有一纳秒的差异。一般来说,除了这些限制,Wireshark在读取hexdumps方面相当自由,并且已经测试了各种混乱的输出(包括通过电子邮件多次转发,换行受限等)。
还有一些其他的特殊特性需要注意。任何第一个非空白字符为#的行都将作为注释被忽略。任何以#TEXT2PCAP开头的行都是指令,可以在该命令后面插入选项,以便Wireshark处理。目前还没有实现任何指令。在未来,这些可能会被用来对转储和处理方式进行更细粒度的控制,例如时间戳、封装类型等。
常规文本转储
752/5000
Wireshark还能够使用GLib的GRegex指定的自定义perl正则表达式扫描输入。使用正则表达式捕捉单个数据包在给定文件wireshark将搜索给定的文件从开始到倒数第二个字符(\ n和最后一个字符将被忽略)的重叠(非空)字符串匹配给定的正则表达式,然后识别领域导入使用命名捕获子组。使用为每个字段提供的格式信息,然后将它们解码并翻译成标准的libpcap文件,并保持包的顺序。
注意,每个命名的捕获子组必须在一个包中匹配一次,但是它们可能在regex中出现多次。
例如如下转储:
> 0:00:00.265620 a130368b000000080060
> 0:00:00.280836 a1216c8b00000000000089086b0b82020407
< 0:00:00.295459 a2010800000000000000000800000000
> 0:00:00.296982 a1303c8b00000008007088286b0bc1ffcbf0f9ff
> 0:00:00.305644 a121718b0000000000008ba86a0b8008
< 0:00:00.319061 a2010900000000000000001000600000
> 0:00:00.330937 a130428b00000008007589186b0bb9ffd9f0fdfa3eb4295e99f3aaffd2f005
> 0:00:00.356037 a121788b0000000000008a18
可以被以下导入:
regex: ^(?<dir>[<>])\s(?<time>\d+:\d\d:\d\d.\d+)\s(?<data>[0-9a-fA-F]+)$
timestamp: %H:%M:%S.%f
dir: in: < out: >
encoding: HEX
“转储文件导入”对话框
此对话框允许您选择要导入的文本文件(包含packetdata的十六进制转储)并设置导入参数。

此导入对话框的特定控件分为三个部分:
(1)文件源:确定必须导入哪个输入文件
- 文件名/浏览:
(2) 输入格式:确定如何解释输入文件。 - 偏移量(准确的翻译应该是“数据编码”)
- 用于二进制数据的编码。支持的编码形式有:纯十六进制、-八进制、-二进制和base64。这里的Plain意味着在数据字段中除了空白之外没有其他字符,这些空白将被忽略。任何意想不到的字符将中止导入过程。
- 忽略的空白是\r, \n, \t, \v, ’ ',并且仅对于hex:,仅对于base64 =。
- 字段末尾的任何不完整字节都被认为是填充最后一个完整字节的填充。这些位应该是零,但是没有检查。
- 时间戳格式
- 这是用于解析要导入的文本文件中的时间戳的格式说明符。它使用与strptime(3)相同的格式,只是将%f添加到零秒填充分数中。%f的精度由它的长度决定。最常见的字段是%H、%M和%S,分别表示小时、分钟和秒。简单的HH:MM:SS格式由%T覆盖。要了解语法的完整定义,请查找strptime(3),
- 在Regex模式下,只有当(
?)组已存在是可用 - 在十六进制转储模式下,如果文本文件中没有要导入的时间戳,请将此字段留空,时间戳将根据导入的时间生成。
- 方向指示
- 表示传入和传出数据包的字符列表。这些字段仅在regex包含一个(
?)组时可用。…
(3)封装:确定如何封装数据
- 表示传入和传出数据包的字符列表。这些字段仅在regex包含一个(
- 封装类型:
- 选择要导入的帧类型。这完全取决于要导入的转储是从哪种介质中获取的
- 它列出了wireshark能够理解的所有类型,以便将不会文件的内容传递给rightdissector
- 无虚头部
- 当选择以太网封装时,必须选择在要导入的帧前添加dummyheader。
- 这些报头可以提供以太网、IP、UDP、TCP、SCTP报头或者SCTP数据块。
- 最大帧长:
- 你可能对文本文件中的完整帧不感兴趣,只对第一部分感兴趣
- 在这里,您可以定义从帧开始要导入的数据量。如果你把这个打开,最大值设置为256kiB。
设置好所有输入和导入参数后,单击import开始导入。如果您当前的数据之前没有保存,您将被要求先保存它。
如果import按钮没有解锁,请确保所有封装参数都在预期范围内,并且在使用regex模式时填充了所有解锁的字段(占位符文本不是默认使用的)。
完成后,将会有一个新的捕获文件,其中包含从文本文件中导入的帧。
文件集
在进行捕获时使用“多个文件”选项(捕获文件和文件格式目录)时,捕获数据分散在多个捕获文件上,称为文件集
由于手工处理一个文件集可能会变得乏味,Wireshark提供了一些功能以方便地处理这些文件集。
Wireshark如何检测文件集的文件?
-
文件集中的文件名使用Prefix_Number_DateTimeSuffix格式,可能类似于test_00001_20210714183910.pcap。一个文件集的所有文件共享相同的前缀(如“test”)和后缀(如“。pcap”)以及不同的中间部分。
-
为了找到文件集的文件,Wireshark会扫描当前加载文件所在的目录,并检查是否有与当前加载文件的文件名模式(前缀和后缀)匹配的文件。
-
这种简单的机制通常工作得很好,但也有其缺点。如果捕获了多个具有相同前缀和后缀的文件集,Wireshark会将它们作为单个文件集进行检测。如果文件被重命名或分散在多个目录中,该机制将无法找到集合中的所有文件。
File→File set子菜单中的以下功能可以方便地使用文件集:
- 列出文件:显示文件集中的文件列表
- 下一文件:
- 如果当前加载的文件是文件集的一部分,请跳到文件集中的下一个文件。
- 如果它不是文件集的一部分或只是该文件集中的最后一个文件,则此项将灰显。
- 上一文件:
- 如果当前加载的文件是文件集的一部分,请跳转到该文件集中的上一个文件。
- 如果它不是文件集的一部分或只是该文件集中的第一个文件,则此项将灰显。
“列出文件对话框”

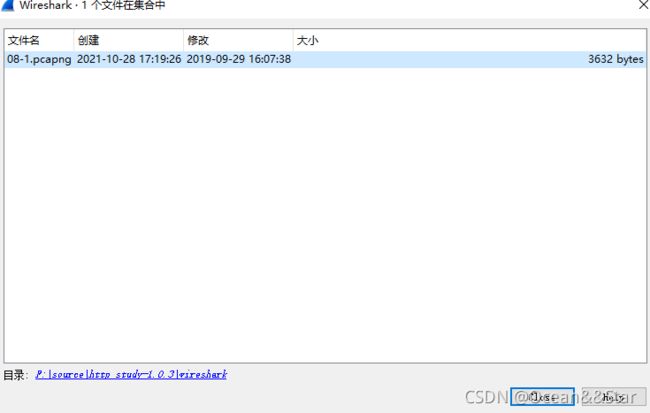
每行包含有关文件集的文件的信息
- 文件名:文件的名称。如果单击文件名(或其左侧的单选按钮),当前文件将关闭,相应的捕获文件将打开。
- 创建:文件的创建时间
- 修改:上次修改文件的时间
- 大小:文件的大小
最后一行将包含有关当前使用的目录的信息,在该目录中可以找到文件集中的所有文件。
每次打开/关闭捕获文件时,此对话框的内容都会更新。
导出数据
wireshark提供了多种导出数据包数据的选项。
导出特定分组(数据包)对话框
作用:
- 将捕获文件中的所有(或部分)数据包导出到文件
- 它将弹出对话框
“导出指定数据包”对话框

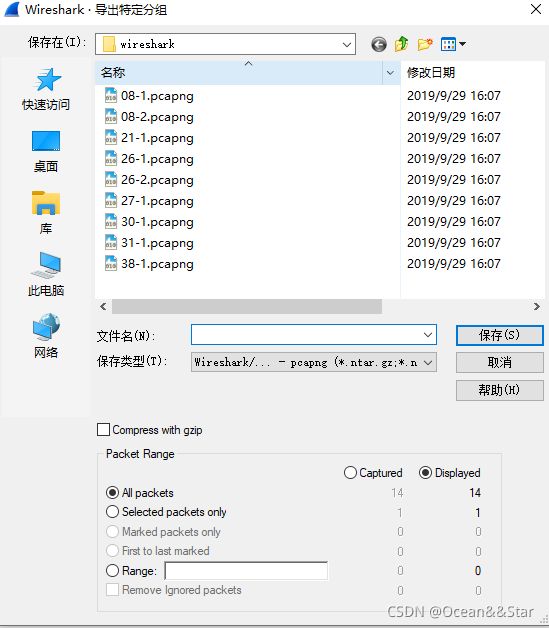
这可以保存特定的数据。对于从捕获文件中删除不相关或者不需要的数据包非常有用
导出分组(数据包)解析结果对话框
可以将数据包列表、数据包详细信息和数据包字节保存为纯文本、CSV、JSON和其他格式
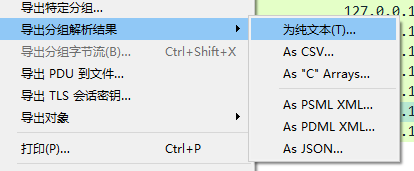
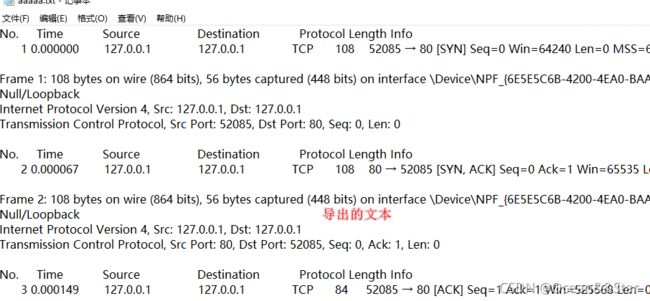
(1)纯文本
(2)CSV
"No.","Time","Source","Destination","Protocol","Length","SSID","Info","Win Size"
"1","0.000000","200.121.1.131","172.16.0.122","TCP","1454","","10554 > 80 [ACK] Seq=1 Ack=1 Win=65535 Len=1400 [TCP segment of a reassembled PDU]","65535"
"2","0.000011","172.16.0.122","200.121.1.131","TCP","54","","[TCP ACKed unseen segment] 80 > 10554 [ACK] Seq=1 Ack=11201 Win=53200 Len=0","53200"
"3","0.025738","200.121.1.131","172.16.0.122","TCP","1454","","[TCP Spurious Retransmission] 10554 > 80 [ACK] Seq=1401 Ack=1 Win=65535 Len=1400 [TCP segment of a reassembled PDU]","65535"
"4","0.025749","172.16.0.122","200.121.1.131","TCP","54","","[TCP Window Update] [TCP ACKed unseen segment] 80 > 10554 [ACK] Seq=1 Ack=11201 Win=63000 Len=0","63000"
"5","0.076967","200.121.1.131","172.16.0.122","TCP","1454","","[TCP Previous segment not captured] [TCP Spurious Retransmission] 10554 > 80 [ACK] Seq=4201 Ack=1 Win=65535 Len=1400 [TCP segment of a reassembled PDU]","65535"
(3)json
{
"_index": "packets-2014-06-22",
"_type": "doc",
"_score": null,
"_source": {
"layers": {
"frame": {
"frame.encap_type": "1",
"frame.time": "Jun 22, 2014 13:29:41.834477000 PDT",
"frame.offset_shift": "0.000000000",
"frame.time_epoch": "1403468981.834477000",
"frame.time_delta": "0.450535000",
"frame.time_delta_displayed": "0.450535000",
"frame.time_relative": "0.450535000",
"frame.number": "2",
"frame.len": "86",
"frame.cap_len": "86",
“导出(所选)分组(数据包)字节流”对话框
将“数据包字节”窗格中选择的字节岛主到原始二进制文件中
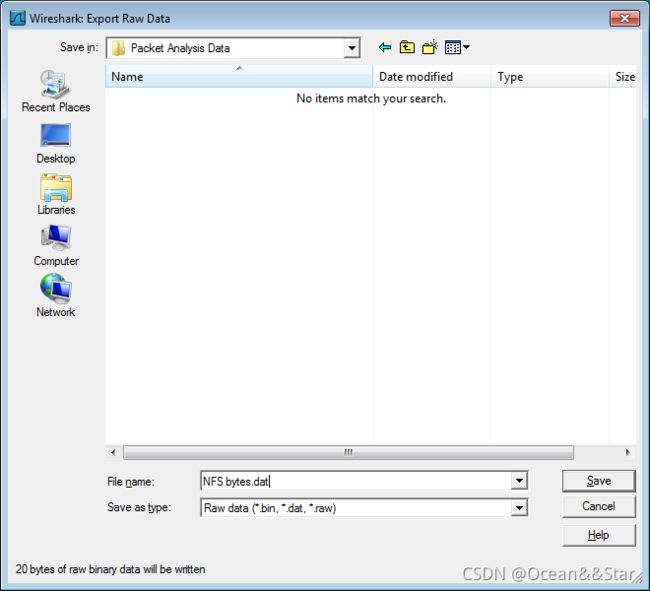
- 文件名:要将数据包数据导出到的文件名
- 另存为类型:文件扩展名
“导出PDU到文件”对话框(没用过)
“将pdu导出到文件…”对话框允许您过滤捕获的协议数据单元(pdu)并将它们导出到文件中。它允许您导出重新组装的pdu,避免不使用TCP的HTTP等较低的协议,以及解密的pdu,不使用HTTP等较低的协议,不使用TLS和TCP。
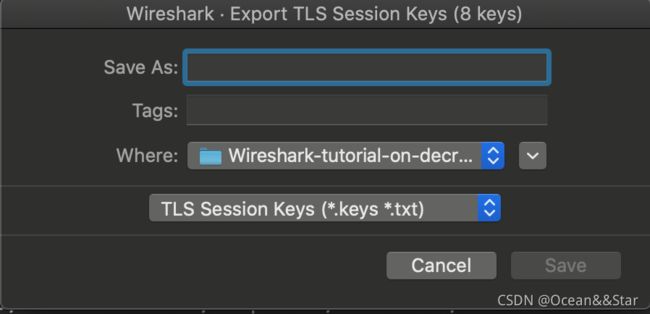
“导出TLS会话密钥”对话框
传输层安全(Transport Layer Security, TLS)加密客户端和服务器之间的通信。它最常见的用途是通过HTTPS浏览网页。
解密TLS通信需要TLS秘密。您可以以存储在“密钥日志文件”中的会话密钥的形式获得它们,或者使用RSA私钥文件。要了解更多细节,请参阅TLS wiki页面。
“File→Export TLS Session Keys…”菜单选项生成一个新的“key log File”,其中包含Wireshark知道的TLS会话秘密。如果您通常使用RSA私钥文件解密TLS会话,则此特性非常有用。RSA私钥非常敏感,因为它可以用来解密其他TLS会话并模拟服务器。会话密钥只能用于解密数据包捕获文件中的会话。然而,会话密钥是在Internet上共享数据的首选机制。
要导出捕获的TLS会话密钥,请执行以下步骤:
- File → Export TLS Session Keys…
- 在“Save as”字段中键入所需的文件名。
- 在Where字段中选择文件的目标文件夹。
- “Save ”导出文件
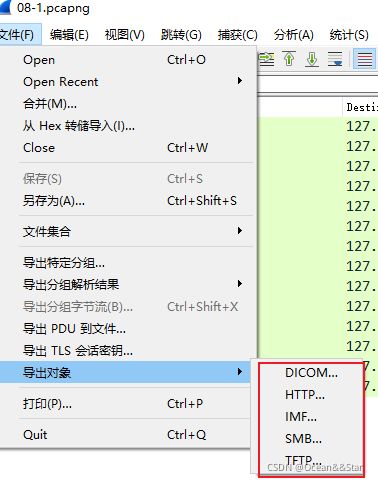
导出对象
作用:
- 将捕获的DICOM、HTTP、IMF、SMB或ftp对象导出到本地文件中
- 它会弹出一个相应的对象列表
说明:
- 此功能扫描当前打开捕获文件或者运行捕获中选定协议的流,并允许用户将重新组合的对象导出到磁盘
- 比如,如果选择HTTP,则可以将HTMLdocuments、images、executables和通过HTTP传输的任何其他文件导出到磁盘。如果您有一个捕获正在运行,此列表每隔几秒钟就会自动更新一次,并显示任何新对象。然后,可以独立于Wireshark打开或检查保存的对象。
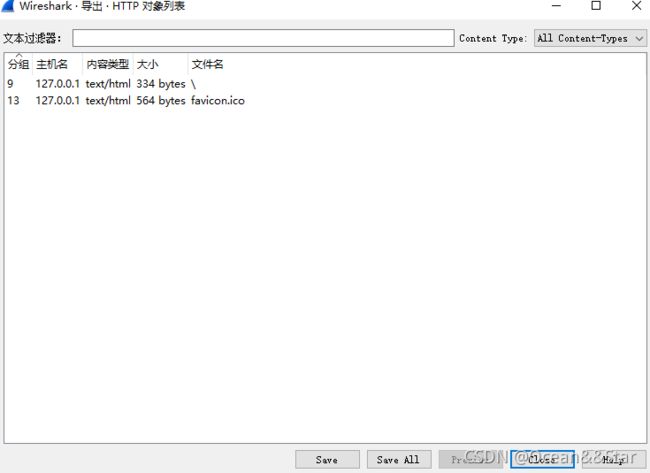
输入:
- 文本过滤器:
- 仅显示包含指定文本字符串的对象
- Content Type:
- 只导出指定类型的内容
接下来:
- 分组:
- 在其中找到此对象的数据包编号
- 在某些情况下,同一数据包中可能有多个对象。
- 主机名
- 发送此对象的服务器的主机名
- 内容类型
- 此对象的内容类型
- 大小
- 此对象的大小(以字节为单位)
- 文件名
- 此对象的文件名。
- 每个协议生成的文件名不同。
- 例如,HTTP使用URI的最后部分,IMF使用电子邮件的主题。
最后:
- 保存:
- 将当前选定的对象另存为指定的文件名。
- 另存为的默认文件名取自objectslist的filename列
- 保存所有:将全部的保存到一个文件夹中
- Preview:预览
- Close:关闭对话框而不导出
- 帮助:打开用户指南的此部分
打印
作用:
- 打印捕获文件中的所有(或部分)数据包
- 它将弹出Wireshark Print(Wireshark打印)对话框
Close
作用:
- 关闭当前菜单项
- 如果您还没有保存捕获,系统会要求您先保存(这可以通过首选项设置禁用)。
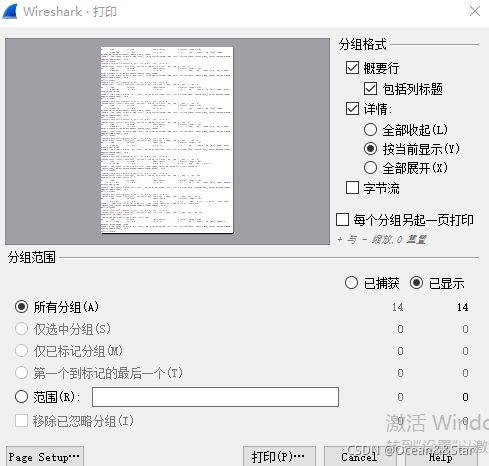
操作1


操作2:设置禁用
不建议这样做
Quit
作用:
- 退出Wireshark。
- Wireshark将要求保存您的捕获文件,如果您以前没有保存它(这可以通过引用设置禁用)。