全国计算机等级考试二级python相关知识点
PYTHON-计算机二级
本文章整理了全国计算机等级考试二级python的相关知识点,还在学习中,疏漏之处请予斧正!
2023/9/25考完更新,time库没有考到,序列类型的操作考察较多!
本文章参考视频:2021年考必看!全国计算机二级Python考试科目,全网最新的计算机真题知识点
数据类型、文件操作
基础数据类型
- Python中的整数是动态长度的,可以根据需要增加其精度,以容纳较大的整数值。
组合数据类型
集合类型(集合set)
特点:元素无序(输入输出顺序可能不同)、不可变(不能传变量),可用于去除重复元素
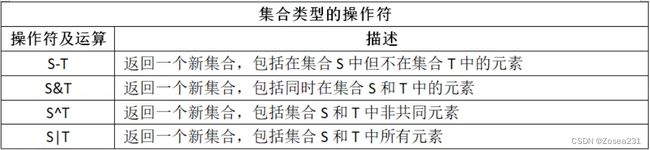
序列类型(字符串str、列表lst。元组tuple)(是一维元素向量)

特别注意切片操作语法:
<序列类型> [开始索引start=0 : 结束索引end : 步长step=1]
- start 是开始索引,默认为0
- end 是结束索引,但不包含end索引处的字符(左闭右开)
- step 是步长,默认为1,(-1时表示逆序输出)
字符串
字符串的处理方法
-
转换大小写:
str.lower() 全部小写、str.upper() 全部大写、str.capitalize() 首字母大写 -
查找、记数:
str.find(目标字符(串),查找起始位置)、str.count(目标字符(串),查找起始位置) -
特殊处理:
str.replace(s1,s2) 字符串s1换为字符串s2、str.center(width, 填充符fillchar)str.split(分隔符separator)按照指定separator(默认为空格)将字符串分割为列表,演示如下:
s = "hello,world,python"
s.split(",")
print(s,type(s)) # hello,world,python (此处仅对字符串 s 的拷贝进行split(),未更改 s)
s = s.split(",")
print(s,type(s)) # ['hello', 'world', 'python'] separator.join(序列sequence) 将序列中的元素用指定字符连接生成一个新的字符串,演示如下:
x=','.join(['hello', 'world'])
print(x,type(x)) # hello,world str.strip() 移除字符串头尾指定的字符或字符序列(默认移除头尾所有空白字符,包括空格、制表符、换行符等)
str.format() 字符串格式化,语法如下:
str{参数索引号:填充字符 对齐方式 槽输出宽度(若字符串长度超过设定槽宽度,则以字符串长度为准) 千位分隔符 精度或字符串的最大输出长度 数值类型}.format()
数值类型:b-二进制 d-十进制 o-八进制 x-十六进制 浮点数类型:e E %f
列表lst
操作方法:ls.append()、ls.insert()、ls.clear()、ls.pop()、ls.remove()、ls.reverse()、ls.copy()

注:
- 列表
ls = [1,2,3,4,[5,6,7]]可能是一维列表- 保留字
del也能对序列元素/片段进行删除
- 语法格式:del 序列对象[索引序号] 或 del 序列对象[start : end : step]
zip(ls):将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表
如以下代码中,用zip() 将列表、元组转换为字典:
t = ('python','java','c')
l = [123,345,789]
d = {}
for i in range(len(t)):
d[i] = [t[i],l[i]] # 组合 t 和 l 的元素,作为列表,给到字典 d 对应键的值
print(d,'\t',len(t)) # {0: ['python', 123], 1: ['java', 345], 2: ['c', 789]} 3
'''
若使用zip()函数,则会将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表.
如将第5行语句替换为::d[i]=list(zip(t,l))
则输出结果为:
{0: [('python', 123), ('java', 345), ('c', 789)], 1: [('python', 123), ('java', 345), ('c', 789)], 2: [('python', 123), ('java', 345), ('c', 789)]} 3
'''
映射类型(字典dict)
- 特点:键值对中,由“键”去索引“值”
注:字典中“通过键(不可变类型)信息找对应的值”的过程,在python中称为“映射”,即语句
值=变量名[键]
定义:变量名(字典对象)={键1:值1,键2:值2,……,键n:值n}
操作函数:len()、min()、max()、dict() 注意:max(d) 和min(d),‘判断 key in d’ 仅和键有关
操作方法:d.keys(),d.values(),d.items(),d.get(),d.pop(),d.popitem,d.clear()
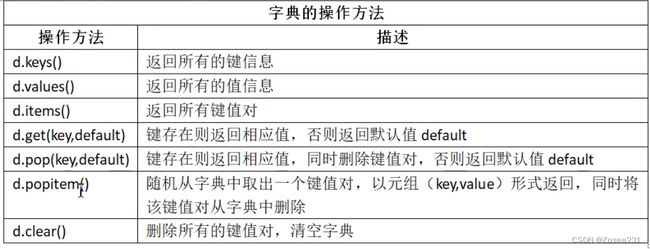
其中:
-
d.items():返回字典中的所有键值对信息,返回结果是Python的一种内部数据类型 “dict_items”,演示如下:d={'name':'zosea','age': 3} print(d,type(d)) # {'name': 'zosea', 'age': 3}print(d.items(),type(d.items())) # dict_items([('name', 'zosea'), ('age', 3)]) print(d['name']) # zosea d.items() 常用作反转键和值,以便进行查找、排序、最大/最小值的处理(处理见下文),演示如下:
dic = {"alice":1001,"john":1003,"kate":1002} reverse_dic = {} # 反转键值对存放字典 for key,val in dic.items(): # 遍历原字典每个键值对 reverse_dic[val] = key print(reverse_dic) # {1001: 'alice', 1003: 'john', 1002: 'kate'}
此外,用in可以判断某个键是否在字典中,常用来遍历字典,演示如下:
d={'规则':'就是用来打破的','随蝴蝶一起消散吧':'旧日的幻影'}
for key in d: # 遍历字典的键
print(key,d.get(key)) # d.get() :键存在则返回相应值,否则返回默认值(此处未指定)
'''运行结果
规则 就是用来打破的
随蝴蝶一起消散吧 旧日的幻影
'''
基于以上,字典还可用作统计键的出现次数、并进行排序处理,演示如下:
ls = ['综合','综合','综合','理工','理工','理工','理工','理工','农林','农林','师范']
# 统计出现次数(键的记数):
d = {} # 新建统计用字典
for word in ls: # 循环遍历列表
d[word] = d.get(word,0) + 1 # 若ls中元素不是d中的键,则新建该键值对,并对值+1,若存在,则值+1
print(d)
# 输出键值对:
for key,values in d.items(): # 通过 d.items() 遍历每个键值对
print("{}:{}".format(key,values))
# 次数排序(以降序为例)
ls = list(d.items()) # 以元组形式取出字典d中全部键值对,转换为列表
ls.sort(key=lambda x:x[1],reverse=True) # Lambda语法:Lanbda 函数传入参数:函数返回值 ( list.sort() 方法仅适用于列表)
print(ls)
# 执行结果:
{'综合': 3, '理工': 5, '农林': 2, '师范': 1}
综合:3
理工:5
农林:2
师范:1
[('理工', 5), ('综合', 3), ('农林', 2), ('师范', 1)]
注意:
list.sort()是列表的方法,而sorted()适用于所有序列
文件和数据格式化
开关/读写文件
打开语法:<变量名> = open ( <文件路径(用\\或/)+<文件名> , <打开模式> (均用字符串表示))(下文以 ‘f’ 作为变量名,以 ‘t’ 为打开模式来演示)open()函数打开一个文件,并返回一个操作该文件的变量
打开模式:
'r'(只读,默认)'w'(覆写write)'x'(新建写exist,文件不存在则创建,存在则返回异常)'a'(追加写,文件不存在则创建,存在则在原文件最后追加内容)'b'(以二进制只读打开文件,不能修改)'t'(文本文件模式,默认)+:与r/w/x/a一同使用,在原功能基础上增加同时读写功能,如:‘r+(可读并修改)’、‘w+’、‘x+’、‘a+’(追加内容、同时可读)
读取方法:
f.read(size=-1)读取整个文件,返回字符串,若size!=-1则读取前size长度的字符串/字节流f.readline(size=-1)读取一行,返回字符串, 若size!=-1则同上f.readlines(row=-1)读取所有行,返回列表,每行作为一个列表中的一个元素;若row!=-1则读取前row行
其他方法:
f.seek(OFFSET)改变当前文件操作指针的位置,0-文件开头 1-文件的当前位置 2-文件结尾f.close()文件使用结束时,释放文件的使用授权
- CSDN-read、readline、readlines 详细用法
# 指针操作演示:
>>>f = open("D://b.txt", "r")
>>>s = f.read() # 直接读成字符串(包含 \n )
print(s)
'''执行结果
劝君莫惜金缕衣, 劝君须惜少年时。
花开堪折直须折, 莫待无花空折枝。
'''
>>>f.seek(0) # 将读取指针重置到文件开头
>>>ls = f.readlines() # 读成列表,每个元素是文件中的一行
>>>print(ls)
['劝君莫惜金缕衣, 劝君须惜少年时。 \n', '花开堪折直须折, 莫待无花空折枝。 \n']
>>>f.close()
#也可用遍历循环,逐行读取文件:
f = open("D://b.txt", "r")
for line in f: # 直接遍历文件中每一行
print(line)
f.close()
'''执行结果:(源文件第一行后有换行符/n,print()默认end='\n',故两行字符串ds会隔一行)
劝君莫惜金缕衣, 劝君须惜少年时。
花开堪折直须折, 莫待无花空折枝。
'''
写入方法:
f.write(str)写入一个字符串f.writelines(lst)将一个元素为字符串的列表写入文件
# 写入操作如:
f = open("C:/Users/ZOSEA/Desktop/新建 文本文档.txt", "w+")
f.write('劝君莫惜金缕衣\n') # 单行写入字符串
f.write('劝君须惜少年时\n')
lst = ['花开堪折直须折\n','莫待无花空折枝']
f.writelines(lst) # 写入由每行元素组成的列表
f.seek(0)
print(f.read())
f.close()
'''执行结果:
劝君莫惜金缕衣
劝君须惜少年时
花开堪折直须折
莫待无花空折枝
'''
-
文件还可用
with实现自动调用f.close()方法,示例语句如:'''语法 with 表达式 [as 变量名]: with-block(with代码块) ''' with open(file, "w") as f: f.write("hello python") # 写入单行字符串,注意缩进
多维数据(列表)
一维数据(AKA数组/向量,采用线性方式组织)
注:逗号分割的存储格式叫做CSV格式(Comma-Separated-Values, 即逗号分隔值),一维数据保存为CSV格式后, 各元素采用逗号分隔, 形成一行。 结合
s.join()可将列表输出为CSV,结合s.strip()和s.split()可将CSV读取为列表
# 写一维数据:
lst = ['北京', '上海', '天津', '重庆']
f = open("C:/Users/ZOSEA/Desktop/新建 文本文档.txt", "w")
f.write(",".join(lst)+ "\n") # 用','连接字符串列表lst,返回字符串,并在末尾连接字符'\n'
f.close()
# 写入内容:
北京,上海,天津,重庆
# 读一维数据:
f = open("C:/Users/ZOSEA/Desktop/新建 文本文档.txt", "r")
lst = f.read().strip('\n').split(",")
f.close()
print(lst) # ['北京', '上海', '天津', '重庆']
二维数据(AKA矩阵,采用二维表格方式组织,以一维数组表示)
注:高维数据由键值对类型的数据构成, 采用对象方式组织, 可以多层嵌套,如以下代码中的二维列表有两层嵌套,而三维列表会有三层嵌套。
# 写二维数据:
f = open("C:/Users/ZOSEA/Desktop/新建 文本文档.txt", "w")
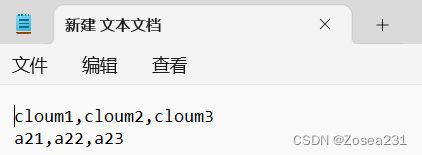
lst = [ ['cloum1','cloum2','cloum3'], ['a21','a22','a23']] # 2x3的矩阵
for line in lst:
f.write(",".join(row)+ "\n")
f.close()
# 读二维数据:
f = open("C:/Users/ZOSEA/Desktop/新建 文本文档.txt", "r")
lst = []
for line in f: # 直接遍历读入文件的每一行
lst.append(line.strip('\n').split(",")) # line 被 strip() 后是字符串,被 split() 后是列表
f.close()
print(lst) # [['cloum1', 'cloum2', 'cloum3'], ['a21', 'a22', 'a23']]
文件写入内容:
Python生态
基本内置函数
基本操作
| 序号 | 函数名 | 描述 |
|---|---|---|
| 1 | input() |
以字符串形式返回输入结果 |
| 2 | len() |
字符串长度 |
| 3 | eval() |
去掉字符串引号,执行剩余python表达式,如eval(‘1+99’)的结果是100;或:x=eval(input(‘请输入:’))` |
| 4 | exec() |
去掉字符串引号,执行剩余python语句,如exec('a=1+99')的结果是变量a的值为100 |
| 5 | ord() |
返回Unicode编码 |
| 6 | range(start,end,step=1) |
创建整数序列(左闭右开),如range(1,10,3)的结果是[1,4,7] |
| 7 | reversed(序列) |
反转序列,如**list(reversed([10,20,30]))**的结果是[30,20,10];注意要用list()! |
| 8 | repr() |
获取任意数据的原始格式字符串 |
# repr()函数:
a="123"
print(a) # 123
print(repr(a)) # '123'
-
sorted(iterable, key=None, reverse=False),返回一个排序后的列表参数:
- iterable: 可迭代对象(列表、元组、集合等)
- key: 主要用于定制排序的关键字提取函数,默认None
- reverse: 排序结果是否反转,默认False升序,True降序
# 列表排序: nums = [5,3,2,4,1] print(sorted(nums)) # [1,2,3,4,5] # 字典排序: users = [{"name":"c","age":30},{"name":"b","age":28},{"name":"a","age":26}] out = sorted(users, key=lambda x:x["age"]) # 按age排序 Lambda语法:Lambda 参数:返回值 print(out) # [{'name': 'a', 'age': 26}, {'name': 'b', 'age': 28}, {'name': 'c', 'age': 30}] '''排序也能这样写: users = [{"name":"c","age":30},{"name":"b","age":28},{"name":"a","age":26}] users.sort(key=lambda x:x["age"]) # 按age排序 Lambda语法:Lambda 参数:返回值 print(users) # 结果相同 ''' # 按绝对值/字符串ASCII大小排序: lst1 = (5,4,3,-2,1) lst2 = ('F','D','Y','e','a','v') # 字符串类型的排序按照ASCII的大小进行比较 L1 = sorted(lst1) L2 = sorted(lst2) L3 = sorted(lst1,key=abs) L4 = sorted(lst2,key=str.lower) L5 = sorted(lst1,reverse=True) print(L1) print(L2) print(L3) print(L4) print(L5) # 执行结果: [-2, 1, 3, 4, 5] ['D', 'F', 'Y', 'a', 'e', 'v'] [1, -2, 3, 4, 5] ['a', 'D', 'e', 'F', 'v', 'Y'] [5, 4, 3, 1, -2]
数值运算
| 序号 | 函数名 | 描述 |
|---|---|---|
| 1 | abs(x) |
x的绝对值/模 |
| 2 | divmod(x,y) |
输出:(x//y,x%y) 即:元组形式的商和余数 |
| 3 | pow(x,y,z=1) |
输出:(x**y)%z 即:幂运算并取余 |
| 4 | round(x,d=0) |
保留d位小数 |
| 5 | max(x1,x2,...xn) |
最大值 |
| 6 | min(x1,x2,...xn) |
最小值 |
| 7 | sum() | 求和 |
进制/数字类型转换
| 序号 | 函数名 | 描述 |
|---|---|---|
| 1 | hex() | 10进制整数转为16进制整数 |
| 2 | oct() | 转为8进制字符串 |
| 3 | bin() | 二进制表示 |
| 4 | int()、float() | 转换为整型、浮点型 |
| 5 | chr() | 将ascii编码转化为字符 65~90为26个大写英文字母,97~122号为26个小写英文字母 ,48~57 为数字(0开始)(从小到大:数字、大写、小写) |
| 6 | ord() | 将字符转化为ascii编码 |
| 7 | bool()、list()、str() | 转换为布尔类型、列表类型、字符串类型 |
| 8 | complex(re,[,im]) |
生成一个复数,实部re(整数/浮点数/字符串)虚部im(整数/浮点数),如complex(10,10)生成:10+10j |
| 9 | dict() |
创建字典 |
注:
复数操作示例:
二进制转十进制:
s = input("请输入一个由1和0组成的二进制数字串:") # 不使用 eval() , s 实际上是字符串 d = 0 while s: # 当 s 还未被切为空时循环 d = d*2 + (ord(s[0]) - ord('0')) # 将上一次录入的二进制数左移,空出来的位置录入新的二进制数 s = s[1:] print("转换成十进制数是:{}".format(d))

判断
# 判断数据类型:
a= 2
isinstance(a,(str,int,list)) # 是元组中的一个返回 True
# 运行结果为:True
type(1) # 验证得结果为,验证成功
#类似地,还有“字符串是否全为数字”的判断:
"12345".isnumeric() # 返回值:True
all(x)判断真假(组合类型变量 x 中元素全为真则真,否则假;(x为空是真))any(x)判断真假(一个真则真)
标准库
turtle库
导入库的方式有:
# 1.import turtle,如: import turtle turtle.circle(200) # 2.import turtle as t,如: import turtle as t t.circle(200) # 3.from turtle import *,如: from turtle import * circle(200) # 直接采用“函数名()”调用
基本操作函数:
setup(width(整数是单位像素,小数是和屏幕的比例),height,startx=None(屏幕中心),starty=None(屏幕中心))clear()清空图形,但不改变turtle位置和角度reset()清空图形,同时重置turtlescreensize(width,height,background_color)设置画布窗口,若无参数,返回当前(width,height)hideturtle()隐藏画笔、showturtle()显示画笔、isvisible()判断画笔是否显示
绘图函数:
pendown()、penup()、pensize(若参数空,返回当前画笔宽度)以及对应别名pd()、pu()、width()write(str,font=None),写str,如:turtle.write('hello',font=('Arial',40,'normal'))
颜色控制函数:
-
pencolor()、color(填充颜色,预定义颜色字符串(如'red')或RGB值的元组(r,g,b))- 注:color()函数也可同时设置画笔和背景填充的颜色,如:
color(colorstr_pen,colorstr_background)或color((r1,g1,b1),(r2,g2,b2))
- 注:color()函数也可同时设置画笔和背景填充的颜色,如:
-
begin_fill()开始填充图形、end_fill()结束填充图形、turtle.filling()返回当前填充状态
运动控制函数:
forward()、backward()、right()、left()、setheading()以及对应别名fd()、bk()、rt()、lt()、seth()goto(x,y)移动到绝对坐标x,y处、setx(x)和sety(y)分别设置画笔的x,y坐标、home()画笔返回原点、setangle()设置画笔角度、speed(0~10)绘制速度circle(radius,e,step)绘制一个半径radius、角度e、内切多边形边数step(默认为0,即画圆)的圆弧;dot(r,color)绘制一个半径r、颜色color的圆点undo()撤销画笔的最后一步操作
random库
-
r.seed(a=None)初始化随机数种子,默认系统时间 -
r.random()生成[0,1)之间的随机浮点数、randint(a,b)生成[a,b]之间的随机整数 -
r.uniform(a,b)生成[a,b]之间的随机浮点数 -
r.randrange(start,end,step)生成[start,end]之间步长step的随机整数 -
r.getrandbits(k)生成k比特长度的随机整数 -
r.choice(seq)从序列类型中随机返回一个元素 -
r.shuffle(seq)打乱序列 -
r.sample(pop,k)从pop类型中随机选取k个元素,以列表形式返回import random as r print(r.sample([1,2,3,4,5],3)) # 执行结果:[5, 1, 2]
time库
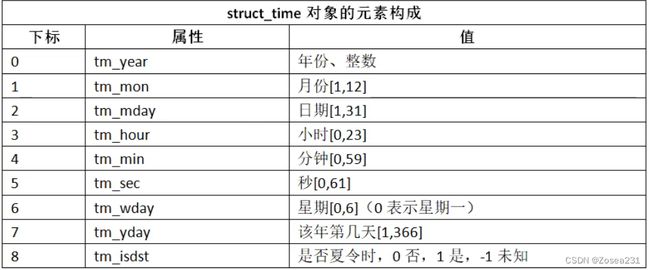
时间处理函数:
time()获取当前时间戳time.gmtime()获取当前时间戳所对应的struct_time对象time.localtime()获取当前时间戳对应的本地时间的struct_time对象time.ctime()获取当前时间戳对应的字符串(会调用localtime()获取当地时间)
- 注意!只有struct_time对象可使用mktime()和strftime()方法
时间格式化函数:
-
time.mktime(t)将代表当地时间的struct_time对象t转换为时间戳import time t=time.localtime() print(time.mktime(t)) print( time.ctime(time.mktime(t)) ) # 执行结果: 1693496300.0 Thu Aug 31 23:38:20 2023 -
time.strftime(格式化字符串,struct_time对象)时间格式化(str-format-time)import time print( time.strftime( '%Y-%m-%d %H:%M:%S',time.localtime() ) ) # 执行结果: 2023-08-31 23:05:20注意:格式化字符串**%D表示以 “月份/日期/年份” 格式输出日期**
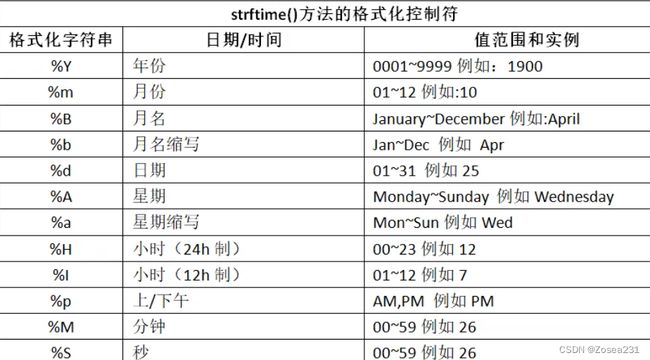
与之作用相反的有
time.strptime()(str-parse-time),提取字符串中时间以生成struct_time对象:# 语法如:time.strptime(timestring,对应的格式化字符串) >>> time.strptime("2019-9-1", "%Y-%m-%d") time.struct_time(tm_year=2019, tm_mon=9, tm_mday=1, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=6, tm_yday=244, tm_isdst=-1) # 经常结合索引来使用,索引规则: ''' strptime(str, tpl)[0]: 4位数年 strptime(str, tpl)[1]: 月( 1 到 12) strptime(str, tpl)[2]: 日( 1到31) strptime(str, tpl)[3]: 小时 0到23 strptime(str, tpl)[4]: 分钟 0到59 strptime(str, tpl)[5]: 秒 ( 0到61 , 60或61 是闰秒) 重要!:strptime(str, tpl)[6]: 一周的第几日 (0到6,0是周一) strptime(str, tpl)[7]: 一年的第几日 (1到366) strptime(str, tpl)[8]: 夏令时( -1, 0, 1, -1是决定是否为夏令时的标志) ''' # 索引使用示例: import time t = '2019-9-2' print(t + "是星期" + str(time.strptime(t,"%Y-%m-%d")[6]+1)) -
strptime()
计时函数:sleep()、perf_counter()
第三方库
掌握
- pip常用的命令有:install、download、uninstall、freeze、list、show、search、wheel、hash、completion、help。
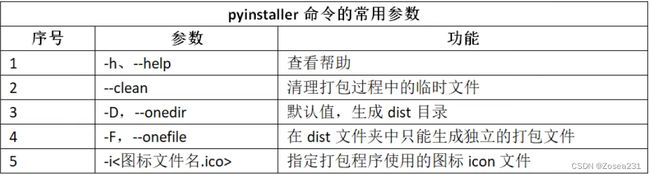
pyInstaller库
安装并配置环境变量后,可用指令pyinstaller -F 文件路径单独对源文件生成exe
jieba库(中文分词)
jieba.lcut(str,cut_all=False)精确模式,返回字符串分词后的列表jieba.lcut(str,True)全模式(返回所有可能)jieba.lcut_for_search(str)搜索引擎模式jieba.add_word(word)向分词字典中增加新词word(添加新词后,该词语不会被切分)
wordcloud库
了解
| 类别 | 名称 |
|---|---|
| 网络爬虫 | requests(处理HTTP请求,如访问网页)、scrapy(Web获取框架)、pyspider |
| 数据分析 | numpy(N维矩阵运算等)、pandas(基于np,增加了了数据模型、处理函数和方法)、scipy(基于np,增加了科学和工程计算相关模块)json(程序间交换数据) |
| 文本处理 | pdfminer(PDF)、openpyxl(Excel)python-docx、beautifulsoup4(HTML和XML) |
| 数据可视化 | matplotlib(二维)、seaborn、mayavi(三维)、TVTK |
| 用户图形界面 | PyQt5(GUI库)、wxPython、PyGObject、PyGTK |
| 机器学习 | scikit-learn(分类、回归、聚类、数据姜维、模型选择和数据预处理,AKA:sklearn)、TensorFlow(Tensor张量-Flow流指:基于数据流图的计算,描述张量从流图的一段流动到另一端的计算过程)、mxnet/Theano |
| Web开发 | Django(Model-Template-Views编写模式)、pyramid(比Django轻、灵活)、flask(极轻) |
| 游戏开发 | pygame(访问外设、图形硬件)、Panda3D(3D游戏引擎)、cocos2d(2D游戏) |
| 其他 | PIL (图像处理)、SymPy (支持符号计算)、NLTK (自然语言处理)、WeRoBot (微信机器人框架)、MyQR |
ASCII码表

数字09对应的ASCII码(十进制)为“48”“57”
大写字母AZ对应的ASCII码(十进制)为“65”“90”
小写字母az对应的百ASCII码(十进制)为"97"“122”