计算机二级Python大题
文章目录
- 第一套
- 第二套
- 第三套
- 第四套
- 第五套
- 第六章
- 第七套
- 第八套
- 第九套
- 第十套
- 第十一套
- 第十二套
- 第十三套
- 第十四套
- 第十五套
- 第十六套
- 第十七套
- 新增1
- 新增2
- 新增3
第一套
6


fi = open("小女孩.txt", "r")
fo = open("PY301-1.txt", "w")
txt = fi.read()
d = {}
exclude = ", 。 ! ? 、 () 【】 《》 <> = : :+-*__“”..."
for word in txt:
if word in exclude:
continue
else:
d[word] = d.get(word, 0) + 1
ls = list(d.items())
ls.sort(key=lambda x:x[1], reverse=True)
fo.write("{}:{}".format(ls[0][0], ls[0][1]))
fo.close()
fi.close()
fi = open("小女孩.txt", "r")
fo = open("PY301-2.txt", "w")
txt = fi.read()
d = {}
for word in txt:
d[word] = d.get(word, 0) + 1
del d["\n"]
ls = list(d.items())
ls.sort(key=lambda x: x[1], reverse=True)
for i in range(10):
fo.write(ls[i][0])
fi.close()
fo.close()
fi = open("小女孩.txt", "r")
fo = open("小女孩-频次排序", "w")
txt = fi.read()
d = {}
for word in txt:
d[word] = d.get(word, 0) + 1
del d[" "]
del d["\n"]
ls = list(d.items())
ls.sort(key=lambda x: x[1], reverse=True) # 此行可以按照词频由高到低排序
fo.write(",".join(ls))
fo.close()
fi.close()
第二套
6


fi = open("PY301-vacations.csv", "r")
ls = []
for line in fi:
ls.append(line.strip("\n").split(","))
s = input("请输入节假日名称:")
for line in ls:
if s == line[1]:
print("{}的假期位于{}-{}之间".format(line[1], line[2], line[3]))
fi.close()
fi = open("PY301-vacations.csv","r")
ls = []
for line in fi:
ls.append(line.strip("\n").split(","))
s = input("请输入节假日序号:").split(" ")
while True:
for i in s:
for line in ls:
if i == line[0]:
print("{}({})假期是{}月{}日至{}月{}日之间".format((line[1]),(line[0]),line[2][:-2],line[2][-2:],line[3][:-2],line[3][-2:]))
s = input("请输入节假日序号:").split(" ")
fi.close()
fi = open("PY301-vacations.csv","r")
ls = []
for line in fi:
ls.append(line.strip("\n").split(","))
s = input("请输入节假日序号:").split(" ")
while True:
for i in s:
flag = False
for line in ls:
if i == line[0]:
print("{}({})假期是{}月{}日至{}月{}日之间".format((line[1]),(line[0]),line[2][:-2],line[2][-2:],line[3][:-2],line[3][-2:]))
flag = True
if flag == False:
print("输入节假日编号有误!")
s = input("请输入节假日序号:").split(" ")
fi.close()
第三套
6

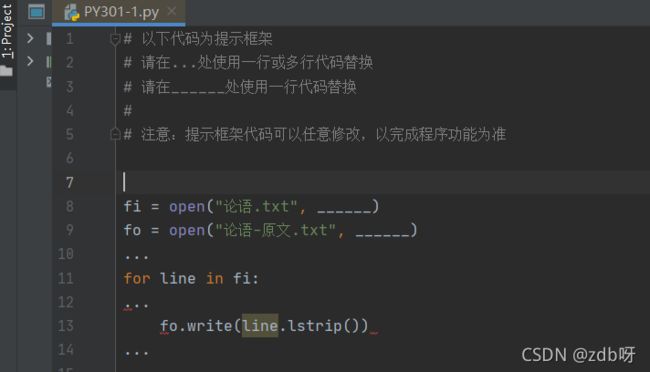
fi = open("论语.txt", "r")
fo = open("论语-原文.txt", "w")
flag = False
for line in fi:
if "【" in line:
flag = False
if "【原文】" in line:
flag = True
continue
if flag == True:
fo.write(line.lstrip())
fi.close()
fo.close()
fi = open("论语-原文.txt", 'r')
fo = open("论语-提纯原文.txt", 'w')
for line in fi:
for i in range(1,23):
line = line.replace("({})".format(i),"")
fo.write(line)
fi.close()
fo.close()
第四套
6

fi = open("sensor.txt", "r")
fo = open("earpa001.txt", "w")
txt = fi.readlines()
for line in txt:
ls = line.strip("\n").split(",")
if " earpa001" in ls:
fo.write('{},{},{},{}\n'.format(ls[0], ls[1], ls[2], ls[3]))
fi.close()
fo.close()
fi = open("earpa001.txt", "r")
fo = open("earpa001_count.txt", "w")
d = {}
for line in fi:
split_data = line.strip("\n").split(",")
floor_and_area = split_data[-2] + "-" + split_data[-1]
d[floor_and_area] = d.get(floor_and_area, 0) + 1
# if floor_and_area in d:
# d[floor_and_area] += 1
# else:
# d[floor_and_area] = 1
ls = list(d.items())
ls.sort(key=lambda x: x[1], reverse=True) # 该语句用于排序
for i in range(len(ls)):
fo.write('{},{}\n'.format(ls[i][0], ls[i][1]))
fi.close()
fo.close()
第五套
6


fi = open("arrogant.txt","r")
fo = open("PY301-1.txt","w")
txt = fi.read()
d = {}
for s in txt:
d[s] = d.get(s,0)+1
del d["\n"]
ls =list(d.items())
for i in range(len(ls)):
fo.write("{}:{}\n".format(ls[i][0],ls[i][1]))
fo.close()
fi.close()
fi = open("arrogant.txt","r")
fo = open("arrogant-sort.txt","w")
txt = fi.read()
d = {}
for s in txt:
d[s] = d.get(s,0)+1
del d["\n"]
ls =list(d.items())
ls.sort(key=lambda x:x[1],reverse=True)
for i in range(10):
fo.write("{}:{}\n".format(ls[i][0],ls[i][1]))
fi.close()
fo.close()
第六章
6



fi = open("score.csv", "r")
fo = open("avg-score.txt", "w")
ls = []
x = []
sum = 0
for row in fi:
ls.append(row.strip("\n").split(","))
for line in ls[1:]:
for i in line[1:]:
sum = int(i) + sum
avg = sum / 3
x.append(avg)
sum = 0
fo.write("语文:{:.2f}\n数学:{:.2f}\n英语:{:.2f}\n物理:{:.2f}\n科学:{:.2f}".format(x[0], x[1], x[2], x[3], x[4]))
fi.close()
fo.close()
第七套
6

fo = open("PY301-1.txt","w")
class Horse():
def __init__(self, category, gender, age):
self.category = category
self.gender = gender
self.age = age
def get_descriptive(self):
self.info = "一匹" + self.category + str(self.age) + "岁的" + self.gender + "马"
def write_speed(self, new_speed):
self.speed = new_speed
addr = "在草原上奔跑的速度为"
fo.write(self.info + "," + addr + str(self.speed) + "km/h。")
horse = Horse("阿拉伯","公",12)
horse.get_descriptive()
horse.write_speed(50)
fo.close()
fo = open("PY301-2.txt","w")
class Horse():
def __init__(self, category, gender, age):
self.category = category
self.gender = gender
self.age = age
def get_descriptive(self):
self.info = "一匹" + self.category + str(self.age) + "岁的" + self.gender + "马"
def write_speed(self, new_speed):
self.speed = new_speed
addr = "在草原上奔跑的速度为"
fo.write(self.info + "," + addr + str(self.speed) + "km/h。")
class Camel(Horse):
def __init__(self, category, gender, age):
super().__init__(category, gender, age)
def write_speed(self,new_speed):
self.speed = new_speed
addr = "在沙漠上奔跑的速度为"
fo.write(self.info.replace("马","骆驼") + "," + addr + str(self.speed) + "km/h。")
camel = Camel("双峰驼","母",20)
camel.get_descriptive()
camel.write_speed(40)
fo.close()
第八套
5
![]()

import math
try:
a = eval(input('请输入底数:'))
b = eval(input('请输入真数:'))
c = math.log(b, a)
except ValueError:
if a<=0 and b>0:
print("底数不能小于等于0")
elif b<=0 and a>0:
print("真数不能小于等于0")
elif a<=0 and b<=0:
print('真数和低数都不能小于等于0')
except ZeroDivisionError:
print('底数不能为1')
except NameError:
print('输入必须为实数')
else:
print(c)
6


intxt = input("请输入明文:")
for p in intxt:
if "a" <= p <= "z":
print(chr(ord("a") + (ord(p) - ord("a") + 3)%26), end="")
elif "A" <= p <= "Z":
print(chr(ord("A") + (ord(p) - ord("A") + 3)%26), end="")
else:
print(p,end="")
第九套
4

5
![]()

fo = open("PY202.txt","w")
for i in range(1,10):
for j in range(1,i+1):
fo.write("{}*{}={}\t".format(j,i,i*j))
fo.write("\n")
fo.close()

6

fi = open("关山月.txt","r")
fo = open("关山月-诗歌.txt","w")
for i in fi.read():
if i == "。":
fo.write("。\n")
else:
fo.write(i)
fi.close()
fo.close()
fi = open("关山月-诗歌.txt","r")
fo = open("关山月-反转.txt","w")
txt = fi.readlines()
txt.reverse()
for line in txt:
fo.write(line)
fi.close()
fo.close()
第十套
3
![]()

这题不会
import time
t = time.localtime()
print(time.strftime("%Y年%m月%d日%H时%M分%S秒",t))
4


有点东西
for i in range(0, 4):
for y in range(0, 4 - i):
print(" ", end="")
print("* " * i)
for i in range(0, 4):
for x in range(0, i):
print(" ", end="")
print("* " * (4 - i))
第十一套
1



f = open("poem.txt","r")
result = []
for line in f.readlines():
line = line.strip("\n")
if len(line) != 0 and line[0] != "#":
result.append(line)
result.sort()
for line in result:
print(line)
f.close()
5



def proc(stu_list):
d = {}
for item in stu_list:
r = item.split("_")
a,b = r[0],r[1].strip()
if a in d:
d[a] += [b]
else:
d[a] = [b]
lst = sorted(d.items(), key = lambda d:len(d[1]), reverse = True)
return lst
f = open("signup.txt","r")
stu_list = f.readlines()
result = proc(stu_list)
for item in result:
print(item[0], '->', item[1])
f.close()
6

d = {"lili": 80, "xiaoqiang": 75, "yunyun": 89, "yuanyuan": 90, "wanghao": 85}
d_sort = sorted(d.items(), key=lambda x: x[1], reverse=True)
for i in range(3):
print(d_sort[i][0] + " " + str(d_sort[i][1]))
第十二套
4


import turtle as t
ls = [69, 292, 33, 131, 61, 254]
X_len = 400
Y_len = 300
x0 = -200
y0 = -100
t.penup()
t.goto(x0, y0)
t.pendown()
t.fd(X_len)
t.fd(-X_len)
t.seth(90)
t.fd(Y_len)
t.pencolor('red')
t.pensize(5)
for i in range(len(ls)):
t.penup()
t.goto(x0 + (i+1)*50, -100)
t.seth(90)
t.pendown()
t.fd(ls[i])
t.done()
6

import jieba
def fenci(txt):
f = open(txt, "r")
datas = f.read()
f.close()
data = jieba.lcut(datas)
d = {}
for i in data:
if len(i) >= 2:
d[i] = d.get(i, 0) + 1
lt = list(d.items())
lt.sort(key=lambda x: x[1], reverse=True)
return lt
def show(lt):
for i in lt[:9]:
print(i[0], ":", i[1], end=',',sep="")
print(lt[9][0], ":", lt[9][1],sep="")
l1 = fenci("data2018.txt")
l2 = fenci("data2019.txt")
print(2019, end=':')
show(l2)
print(2018, end=':')
show(l1)
import jieba
def fenci(txt):
f = open(txt, "r")
datas = f.read()
f.close()
data = jieba.lcut(datas)
d = {}
for i in data:
if len(i) >= 2:
d[i] = d.get(i, 0) + 1
lt = list(d.items())
lt.sort(key=lambda x: x[1], reverse=True)
ls = [x[0] for x in lt[:10]]
return ls
def show(lt):
print(','.join(lt))
l1 = fenci("data2018.txt")
l2 = fenci("data2019.txt")
l3 = []
for i in l1:
if i in l2:
l3.append(i)
for i in l3:
l1.remove(i)
l2.remove(i)
print("共有词语:", end='')
show(l3)
print('2019特有:', end='')
show(l2)
print('2018特有:', end='')
show(l1)
第十三套
4


import turtle as t
import random as r
color = ['red','orange','blue','green','purple']
r.seed(1)
for i in range(5):
rad = r.randint(20,50)
x0 = r.randint(-100,100)
y0 = r.randint(-100,100)
t.color(r.choice(color))
t.penup()
t.goto(x0,y0)
t.pendown()
t.circle(rad)
t.done()
5


img = [0.244, 0.832, 0.903, 0.145, 0.26, 0.452]
filter = [0.1,0.8,0.1]
res = []
for i in range(len(img)-2):
k = 0
for j in range(len(filter)):
k += filter[j] * img[j+i]
print("k={:.3f} ,filter[{}]={:.3f} ,img[{}{}{}]={:.3f}".format(k,j,filter[j],i,'+',j,img[i+j]))
res.append(k)
for r in res:
print('{:<10.3f}'.format(r),end = '')
6

import jieba
fi = open("data.txt","r",encoding='utf-8')
data = fi.read()
fo = open("clean.txt","w")
s = ''
except_word = ",。?、‘’“”;:()\n--!"
for i in data:
if i not in except_word:
s += i
fo.write(s)
fi.close()
fo.close()
import jieba
fi = open("clean.txt", "r")
data = fi.read()
words = jieba.lcut(data)
d = {}
for word in words:
if len(word)>=3:
d[word] = d.get(word, 0) + 1
lt = list(d.items())
lt.sort(key=lambda x: x[1], reverse=True)
for i in lt[:9]:
print(i[0], ":", i[1], end=',', sep='')
print(lt[9][0], ":", lt[9][1], sep='')
fi.close()
第十四套
3
![]()
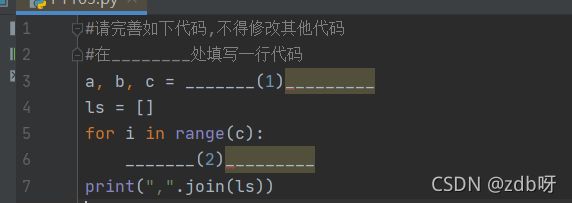
a, b, c = [eval(x) for x in input().split(",")]
ls = []
for i in range(c):
ls.append(str(a*(b**i)))
print(",".join(ls))
4


import turtle
turtle.pensize(2)
for i in range(4):
turtle.fd(200)
turtle.left(90)
turtle.left(-45)
turtle.circle(100*pow(2,0.5))
6

fi = open("data.txt", "r")
f = open("univ.txt", "w")
L = []
lines = fi.readlines()
for line in lines:
if 'alt=' in line:
begin = line.find('alt=')
end = line.find('"', begin + 5)
L.append(line[begin + 5:end])
for i in L:
f.write(i + "\n")
fi.close()
f.close()
# 请在______处使用一行或多行代码替换
#
# 注意:其他已给出代码仅作为提示,可以修改
f = open("univ.txt", "r")
n = 0 # 包含大学的名称数量
m = 0
L = []
names = f.readlines()
for name in names:
name = name.strip("\n")
if "大学生" not in name:
if "大学" in name:
L.append(name)
elif "学院" in name:
L.append(name)
for name in L:
if name[-2:] == "学院":
m += 1
else:
n += 1
print(name)
f.close()
print("包含大学的名称数量是{}".format(n))
print("包含学院的名称数量是{}".format(m))
第十五套
5
![]()
f = open("vote.txt")
names = f.readlines()
f.close()
n = 0
for name in names:
num = len(name.split())
if num == 1:
n += 1
print("有效票{}张".format(n))
f = open("vote.txt")
names = f.readlines()
f.close()
L = []
for name in names:
num = len(name.split())
if num == 1:
L.append(name.strip("\n"))
d = {}
for name in L:
d[name] = d.get(name,0) + 1
ls = list(d.items())
ls.sort(key=lambda x:x[1], reverse=True) # 此行可以按照词频由高到低排序
print("{}:{}".format(ls[0][0],ls[1][1]))
6

# 请在...处使用多行代码替换
#
# 注意:其他已给出代码仅作为提示,可以修改
import jieba
fi = open("data.txt", "r")
f = open('out1.txt', 'w')
txt = fi.read()
words = jieba.lcut(txt)
words = list(set(words))
for word in words:
if len(word)>=3:
f.write(word+"\n")
fi.close()
f.close()
import jieba
fi = open("data.txt", 'r')
fo = open('out2.txt', 'w')
txt = fi.read()
words = jieba.lcut(txt)
d = {}
for word in words:
if len(word) >= 3:
d[word] = d.get(word, 0) + 1
ls = list(d.items())
ls.sort(key=lambda x: x[1], reverse=True) # 此行可以按照词频由高到低排序
for i in ls:
a = i[0]+":"+str(i[1])
fo.write(a+"\n")
fi.close()
fo.close()
第十六套
2


s = input("请输入中文和字母的组合: ")
count = 0
for c in s:
if '\u4e00' <= c <= '\u9fff':
count += 1
print(count)
5

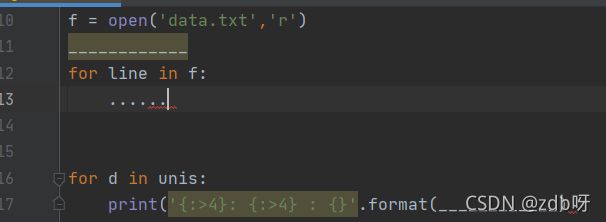
f = open('data.txt','r')
dic={}
for line in f:
l=line.strip().split(',')
if len(l)<3:
continue
dic[l[-1]]=dic.get(l[-1],[])+[l[1]]
unis=list(dic.items())
unis.sort(key=lambda x:len(x[1]),reverse=True)
for d in unis:
print('{:>4}: {:>4} : {}'.format(d[0],len(d[1]),' '.join(d[1])))
6

import jieba
f = "红楼梦.txt"
sf = "停用词.txt"
f1 = open(f, "r", encoding='utf-8')
datas = f1.read()
f1.close()
f2 = open(sf, "r", encoding='utf-8')
words = f2.read()
f2.close()
data = jieba.lcut(datas)
d = {}
word = ["一个", "如今", "一面", "众人", "说道", "只见", "不知",
"两个", "起来", "二人", "今日", "听见", "不敢", "不能",
"东西", "只得", "心中", "回来", "几个", "原来", "进来",
"出去", "一时", "银子", "起身", "答应", "回去"]
for i in data:
if len(i) < 2 or i in words or i in word:
continue
if i in ['凤姐', "凤姐儿", "凤丫头"]:
i = "凤姐"
elif i in ["宝玉", "二爷", "宝二爷"]:
i = "宝玉"
elif i in ["黛玉", "颦儿", "林妹妹", "黛玉道"]:
i = "黛玉"
elif i in ["宝钗", "宝丫头"]:
i = "宝钗"
elif i in ["贾母", "老祖宗"]:
i = "贾母"
elif i in ["袭人", "袭人道"]:
i = "袭人"
elif i in ["贾政", "贾政道"]:
i = "贾政"
elif i in ["贾琏", "琏二爷"]:
i = "贾琏"
d[i] = d.get(i, 0) + 1
l = list(d.items())
l.sort(key=lambda x: x[::-1], reverse=True)
f = open("result.csv", "w")
for i in l:
if i[1] < 40:
break
f.write(i[0] + ',' + str(i[1]) + '\n')
f.close()
第十七套
2


import time
t = input("请输入一个浮点数时间信息: ")
s = time.ctime(eval(t))
ls = s.split()
print(ls[3].split(':')[0])
5

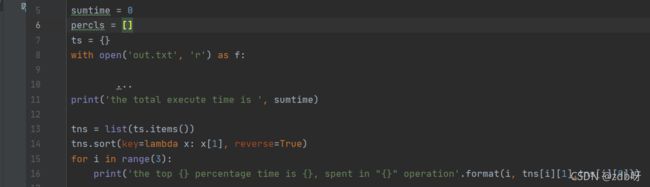
sumtime = 0
percls = []
ts = {}
with open('out.txt', 'r') as f:
for i in f:
i = i.strip().split(',')
ts[i[0]] = i[2]
sumtime += eval(i[1])
print('the total execute time is ', sumtime)
tns = list(ts.items())
tns.sort(key=lambda x: x[1], reverse=True)
for i in range(3):
print('the top {} percentage time is {}, spent in "{}" operation'.format(i, tns[i][1], tns[i][0]))
6

f = open("八十天环游地球.txt")
fo = open("八十天环游地球-章节.txt","w")
txt = f.readlines()
for line in txt:
line = line.strip()
if line[0]=="第" and line[2]=="章":
fo.write(line+"\n")
fo.close()
f.close()
import jieba
f = open("八十天环游地球.txt")
datas = f.readlines()
l = []
for i in range(len(datas)):
if datas[i][0] == "第" and datas[i][2] == "章":
l.append(i) # 每章节所在索引
# line = datas[i].split(' ')
# if datas[i][0] == "第" and "章" in line[0]:
# l.append(i)
for i in range(len(l)):
if i != len(l) - 1: # 最后一章节
data = ''.join(datas[l[i]:l[i + 1]])
else:
data = ''.join(datas[l[i]:])
s = data.split()[0] # 第几章
words = jieba.lcut(data)
d = {}
for y in words:
if len(y) < 2:
continue
d[y] = d.get(y, 0) + 1
lis = list(d.items())
lis.sort(key=lambda x: x[1], reverse=True)
print(s, lis[0][0], lis[0][1])
f.close()
新增1
6

L = []
fo = open("score.txt", "r")
fi = open("candidate0.txt", "w")
lines = fo.readlines()
for line in lines:
line = line.strip()
student = line.split(' ')
sum = 0
for i in range(1, 11):
sum += int(student[-i])
student.append(str(sum))
L.append(student)
L.sort(key=lambda x: x[-1], reverse=True)
for i in range(10):
fi.write(' '.join(L[i][:-1]) + '\n')
fo.close()
fi.close()
fi = open("candidate0.txt", "r")
fo = open("candidate.txt", 'w')
L = []
lines = fi.readlines()
for line in lines:
line = line.strip()
student = line.split(' ')
for i in student[2:]:
if int(i) < 60:
break
else:
L.append(student[:2])
for i in L:
fo.write(' '.join(i) + '\n')
fi.close()
fo.close()
新增2
5

f=open("name.txt")
names=f.readlines()
f.close()
f=open("vote.txt")
votes=f.readlines()
f.close()
f=open("vote1.txt","w")
D={}
NUM=0
for vote in votes:
num = len(vote.split())
if num==1 and vote in names:
D[vote[:-1]]=D.get(vote[:-1], 0)+1
NUM+=1
else:
f.write(vote)
f.close()
l=list(D.items())
l.sort(key=lambda s:s[1],reverse=True)
name=l[0][0]
score=l[0][1]
print("有效票数为:{} 当选村长村民为:{},票数为:{}".format(NUM,name,score))
6

import jieba
f = open('data.txt','r')
lines = f.readlines()
f.close()
f = open('out.txt','w')
for line in lines:
line=line.strip(' ') #删除每行首尾可能出现的空格
wordList = jieba.lcut(line) #用结巴分词,对每行内容进行分词
f.writelines('\n'.join(wordList)) #将分词结果存到文件out.txt中
f.close()
import jieba
f = open('out.txt','r') #以读的方式打开文件
words = f.readlines()
f.close()
D={}
for w in words: #词频统计
D[w[:-1]]=D.get(w[:-1], 0) + 1
print("曹操出现次数为:{} ".format(D["曹操"]))
新增3
3


def f(n):
s = 0
if n%2==1:
for i in range(1, n+1, 2):
s += 1/i
else:
for i in range(2, n+1, 2):
s += 1/i
return s
n = int(input())
print('{:.2f}'.format(f(n)))
5

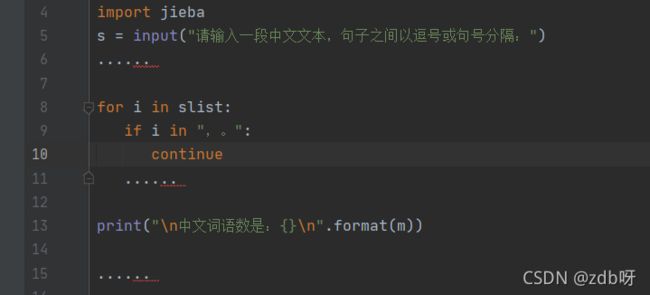
import jieba
s = input("请输入一段中文文本,句子之间以逗号或句号分隔:")
slist = jieba.lcut(s)
m = 0
for i in slist:
if i in ",。":
continue
m += 1
print(i, end='/')
print("\n中文词语数是:{}\n".format(m))
ss = ''
for i in s:
if i in ',。':
print('{:^20}'.format(ss))
ss = ''
continue
ss += i
6

fi = open("data.txt",'r')
fo = open("studs.txt",'w')
datas = fi.readlines()
for data in datas:
data1 = data.strip().split(':')
data2 = data1[1].split(',')
name = data1[0]
score = data2[1]
fo.write(name+":"+score+"\n")
fi.close()
fo.close()
fi = open("data.txt",'r')
datas = fi.readlines()
d = {}
for data in datas:
data1 = data.strip().split(':')
data2 = data1[1].split(',')
name = data1[0]
score = data2[1]
d[name] = score
lst = list(d.items())
lst.sort(key=lambda x:x[1], reverse=True)
print(lst[0][0]+":"+lst[0][1])
fi.close()
fi = open("data.txt", 'r')
datas = fi.readlines()
d = {}
for data in datas:
data1 = data.strip().split(':')[1]
banji, score = data1.split(',')
d[banji] = d.get(banji, []) + [int(score)]
for i in d.items():
print(i[0] + ":" + "{:.2f}".format(sum(i[1]) / len(i[1])))
fi.close()