Jmeter自动化测试工具从入门到进阶6小时搞定.黑马跟学
Jmeter自动化测试工具从入门到进阶6小时搞定.黑马跟学
- 一、JMeter-工具入门篇
-
- 1.JMeter简介
-
- 1.1 优点
- 1.2 缺点
- 2.JMeter安装
-
- 2.1 安装JDK
- 2.2 安装JMeter
- 2.3编码修改
- 3.JMeter基本使用
-
- 3.1 项目环境搭建
- 3.2 项目简介
- 3.3 API接口清单
- 3.4 JMeter的基本使用
- 4.JMeter线程组
-
- 4.1 JMeter并发执行和顺序执行
- 4.2 JMeter线程组常用属性
- 4.3 JMeter两个特殊线程组
- 4.4 http请求默认值
- 4.5 信息头管理器
- 5.参数化
-
- 5.1 参数化--用户定义的变量
- 5.2 参数化--CSV数据文件设置
- 5.3 参数化--用户参数
- 5.4 参数化--函数
-
- (1)计数器
- (2)随机数
- (3)时间函数
- (4)总结函数
- 6.直连数据库
- 7.断言
-
- 7.1 响应文本
- 7.2 响应代码
- 7.3 大小断言
-
- (1)完整响应
- (2)响应头
- (3)响应的消息体
- (4)响应代码
- (5)响应信息
- 7.4 断言持续时间
一、JMeter-工具入门篇
B站视频跟学,相关资料可以直接在这里提取,比较方便:
资料Download
提取码:m3cz

- 学习目标

1.JMeter简介
- JMeter 是 Apache 组织使用 Java 开发的一款测试工具:
- 1、可以用于对服务器、网络或对象模拟巨大的负载
- 2、通过创建带有断言的脚本来验证程序是否能返回期望的结果
1.1 优点
-
- 开源、免费
-
- 跨平台
-
- 支持多协议
-
- 小巧
-
- 功能强大
1.2 缺点
-
- 不支持IP欺骗
-
- 使用JMeter无法验证JS程序,也无法验证页面UI,所以要和Selenium配合来完成Web2.0应用的测试
2.JMeter安装
2.1 安装JDK
JMeter 是使用 Java 编写的,必须安装 Java 环境:
- JDK: Java SE Development Kit (java 开发工具包,为 JAVA 程序开发提供环境支持)
- JRE: Java Runtime Environment (java 运行环境,为 JAVA 程序运行提供环境支持)
2.2 安装JMeter
下载并安装 JMeter
下载: JMeter官网下载地址
安装: 直接解压缩即可

2.3编码修改
编码修改可以在我的博文中搜索
Apache JMeter 5.5 下载安装以及设置中文教程
或者跳转这里(可能会过期)
Apache JMeter 5.5 下载安装以及设置中文教程
3.JMeter基本使用
3.1 项目环境搭建
整个项目是python项目,所以要安装python,上面提供的资料中都有,直接双击.exe文件安装即可

安装的过程中注意勾选添加Path去环境变量中Add Python 3.5 to PATH
如果自定义路径安装的话选择第二个Customize installation

比如这里我是自定义安装

安装完后输入cmd
python
出现下图,说明安装成功

安装之后我们需要配置环境变量,把安装路径下的Scripts配置到环境变量中,这里我的Scripts文件夹在这个目录下:
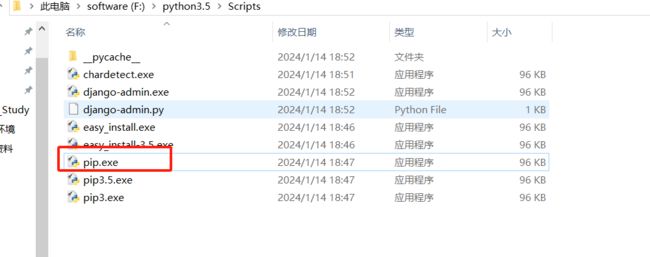
配置环境变量如下:
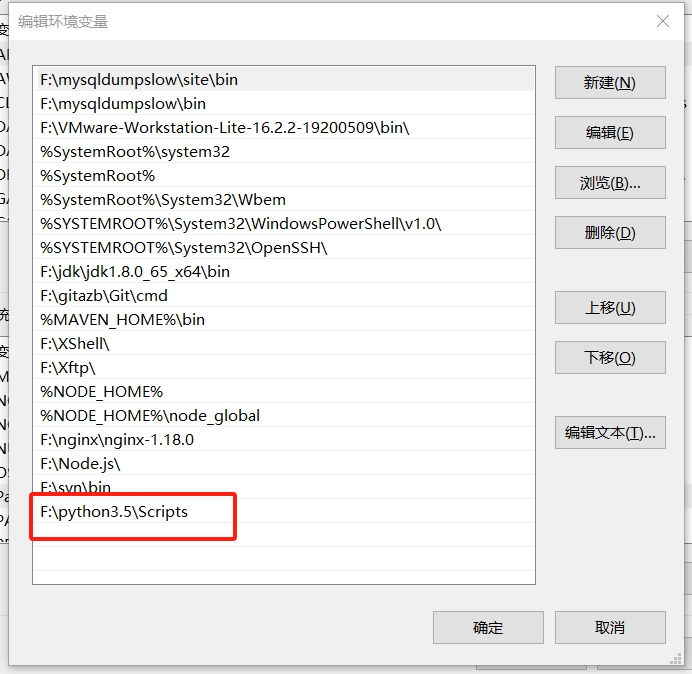
配置完成后,输入cmd,然后输入
pip
出现如下界面,说明环境变量配置成功

安装完成之后,在项目文件夹中,安装依赖
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/

运行后报错如下:说明检测到当前目录下没有requirements这个文件

很简单,我们看一下下载的资料的项目目录,在这里再执行一次

发现报错信息如下:说明国内的镜像没有加入信任

我们更换一下指令,在后面加上–trust
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com

安装完成之后,验证一下是否安装成功
在项目路径中执行如下指令

python run_server.py
页面提示这个,说明成功了

3.2 项目简介
学生管理系统:对学生信息进行增删改查,对应的RESTful语法风格如下
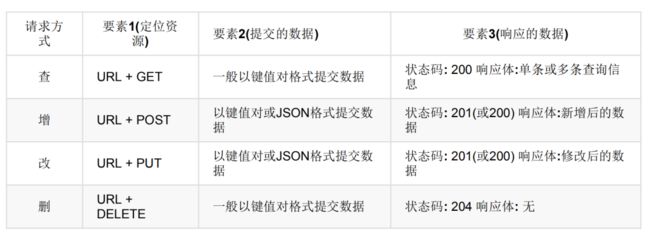
3.3 API接口清单
资料中提供了接口清单:

3.4 JMeter的基本使用
设置接口三要素查询所有学院信息:
1、测试计划–右键–线程–添加线程组
2、线程组–右键–取样器–http请求
3、测试计划–右键–添加监听器–查看结果树
4、点击运行,查看结果
目标如下:验证资料中的api接口

配置如下:

执行之前,要注意python的cmd窗口不能关闭

运行后,查看结果树

项目的数据库文件路径如下:db.sqlite3

资料中有sqlitestudio-3.1.1,可以打开

打开SQLiteStudio.exe文件,把db.sqlite3拖进来

也可以点击左上角数据库-添加数据库
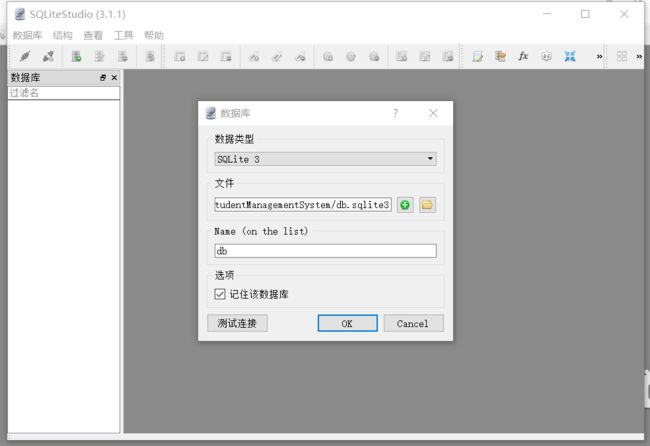
可以看到数据库中的数据和JMeter查询出来的结果一致

4.JMeter线程组
- 进程: 正在运行的程序
- 线程: 是进程中的执行线索
- 线程组: 进程中有许多线程,为了方便管理,可以对线程按照性质分组,分组的结果就是线程组。
PS: 三者关系,一个进程可以包含多个线程组,一个线程组可以包含多个线程
例:迅雷下载电影
- 喜剧片:西虹市首富、大话西游、喜剧之王
- 恐怖片:贞子、咒怨、生化危机

4.1 JMeter并发执行和顺序执行
并发执行: 多个线程同时执行
顺序执行: 多个线程顺序执行
以下是顺序执行的配置:

这里要注意:查看结果树是放到执行计划下的,这样可以看到两个线程组的查询结果

4.2 JMeter线程组常用属性
- 线程数:模拟的用户个数
- Ramp-Up时间(秒):
- 循环次数:每个人执行几遍
比如我这样设置,模拟2个用户,每个用户调用3次

查看结果树如下:一共调用了6次

如果勾选了永远,那么将会一直调用

勾选调度器后
- 持续时间:规定时间内,能跑几个算几个
- 启动延迟:几秒后才开始跑,类似于一个延迟动作
示例:比如我这里设置的是等待3秒,3秒之后开始执行线程组,但是只执行2秒。所以一共花费了5秒时间

调用结果如下:

具体参数介绍如下:

4.3 JMeter两个特殊线程组
- setUp线程组:最优先执行的线程组
- tearDown线程组:最后执行的线程组
我们在同一个执行计划下,创建2个线程组,一个是SetUp线程组,另一个是tearDown线程组。
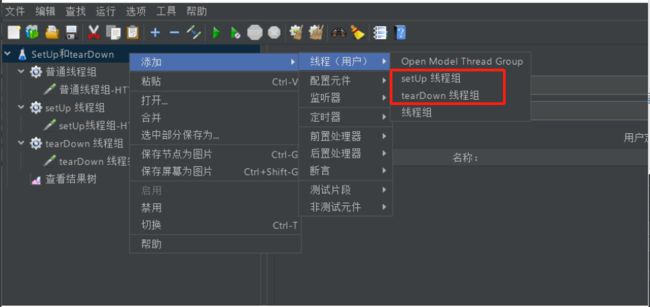
可以看到,在默认情况下,先执行了setUp线程组。

我们再添加一个普通线程组,发现执行顺序都是
- setUp线程组
- 普通线程组
- tearDown线程组

4.4 http请求默认值
http请求默认值:被复用的内容的封装
添加-配置元件-HTTP请求默认值

一般是设置4个地方,路径是不一样的,就不用写了

那么写HTTP请求的时候,就可以省略相同的信息

执行后查看结果树,结果一样

4.5 信息头管理器
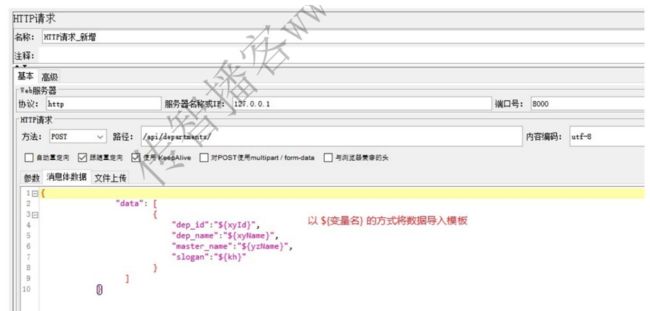
新增修改实现时提交的数据是 JSON 格式的,需声明提交的数据的内容类型
添加-配置元件-HTTP信息头管理器

这次我们要测试新增接口

注意,要在消息体中进行json的编写

如果我们直接调用,发现报错

因为我们需要在请求头中申明是json格式
添加
Content-Type application/json;character=utf-8

再调用一次,就发现成功了

5.参数化
当提交的数据量较大,怎么提交?每测试一次就修改一次吗?
定义:动态的获取、设置或生成数据,是一种由程序驱动代替人工驱动的数据设计方案,提高脚本的编写。
效率以及编写质量
以下四种方式实现参数化:
1、用户定义的变量
2、CSV 数据文件设置
3、用户参数
4、函数
5.1 参数化–用户定义的变量
比如我们调用的URL路径中,都包含了/api/departments/,那么我们就可以把这段路径作为一个变量来管理。
添加-配置元件-用户定义的变量
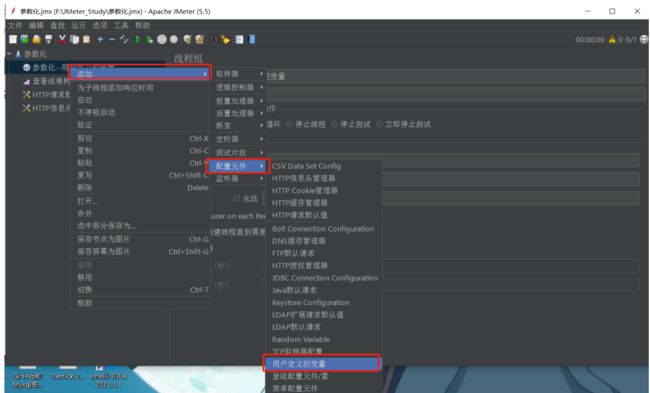
配置用户定义的变量

调用格式: ${变量名}
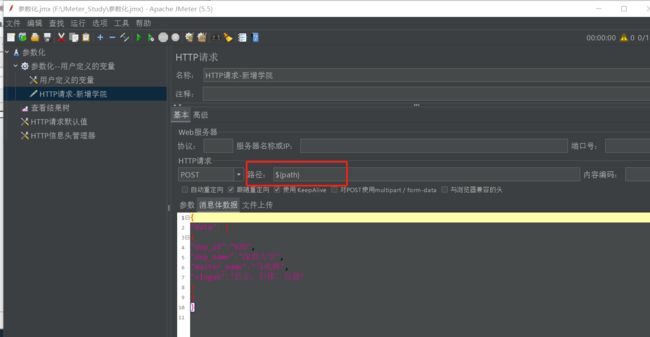
最后调用结果如下:
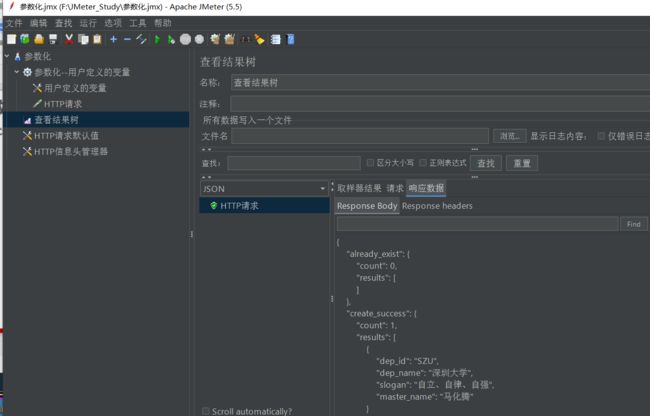
5.2 参数化–CSV数据文件设置
CSV :逗号分隔值,是一种简洁且常见的数据存储格式,存储语法如下图所示。
添加-配置元件-CSV数据文件设置
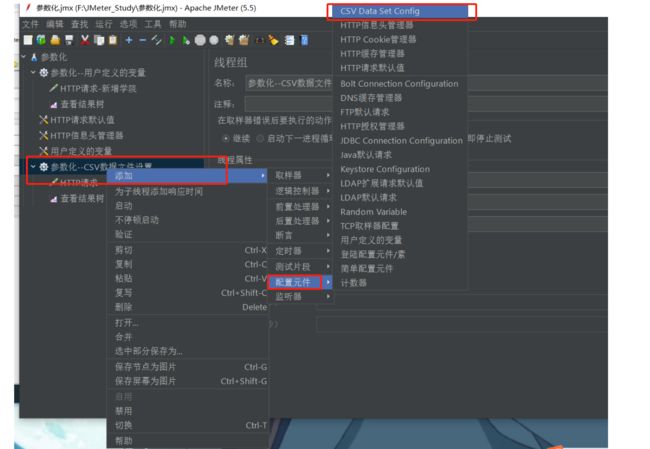
实现步骤:
1、使用 CSV 文件存储测试数据
2、编写被复用的学院新增脚本模板
注意2: 编码集使用 UTF-8 无 BOM 格式
3、关联脚本与数据(将文件数据导入脚本)
新建一个txt文件,内容如下,对应表里的三列字段,注意没有双引号
PDU, 北京大学, 北大校长, 北大校训
QDU, 清华大学, 清华校长, 清华校训
NDU, 南京大学, 南京校长, 南京校训
注意另存为的时候编码选择UTF-8

添加CSV数据文件设置,选择创建的CSV.txt这个文件
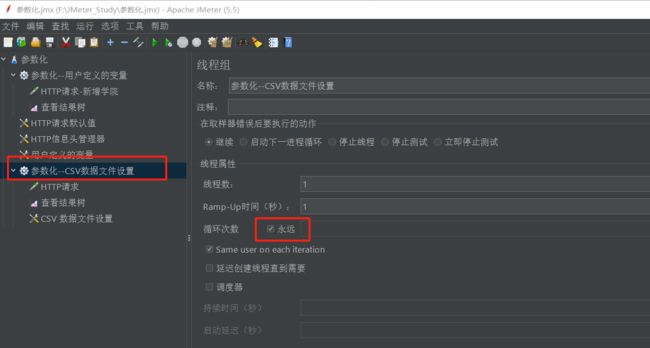
遇到文件结束符再次循环:要选择false,否则会一直循环读取
遇到文件结束符停止线程:要选择true,否则线程一直没有关

注意:线程组中循环次数设置为永远
原因是有多少条数据不一定,要让程序读取完之后再结束
运行,查看结果树,三条数据运行成功

查看数据库中3条插入成功

5.3 参数化–用户参数
实现步骤:
1、编写被复用的学院新增脚本模板
2、使用 用户参数存储测试数据
3、将数据导入脚本模板
4、设置执行次数
添加-前置处理器-用户参数

数据设计规则: 第一列声明每条数据的字段名称,第二列以及以后,每一列对应一条数据

注意:需要调整线程数控制数量
比如,这里我有2个用户,所以线程数设置的是2

查看结果树如下:
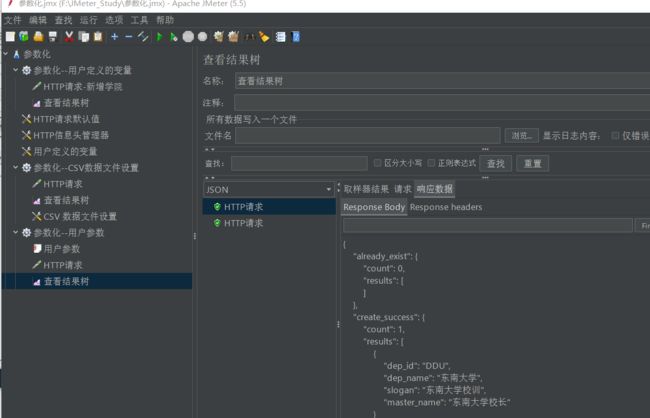
数据库中数据添加成功

5.4 参数化–函数
常见函数:
- __counter 计数器函数 TRUE(每个用户都有自己的计数器) FALSE(所有用户共用一个计数器)
- __Random 随机数函数 参数1:取值范围最小值(包含) 参数2:取值范围最大值(包含)
- __time 获取当前时间的函数 无参: 获取的是距离 1970/01/01 00:00:00 的毫秒值
参数1: yyyyMM_dd HH:mm:ss 格式化成 年\月_日 时:分:秒 格式
(1)计数器
点击函数助手

选择一个功能,比如我选择的counter

名称我们选择的是true,表示每个用户都有独立的计数器
点击生成变量名,然后拷贝产生的变量名

然后把自增的数字,替换成变量

设置线程数是2,循环3次
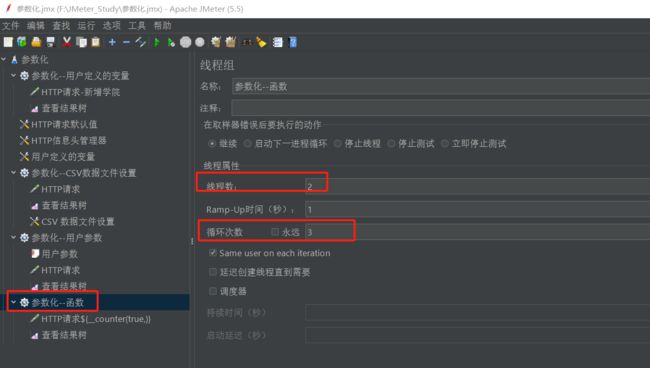
点击查看结果树,发现角标只有1到3,因为只有两个用户,每个用户循环了3次,符合要求

我们把名称更改为false,再来试一下

点击查看结果树,发现角标从1到6了
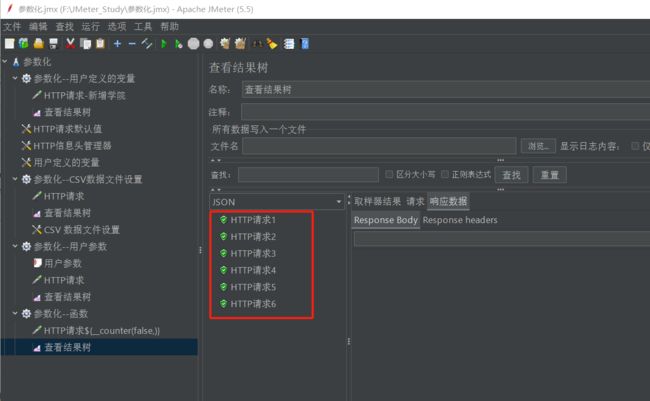
(2)随机数
选择random,可以设置一个最小值和最大值

同理,生成之后,把相应的函数复制到HTTP请求的名称后,查看结果树
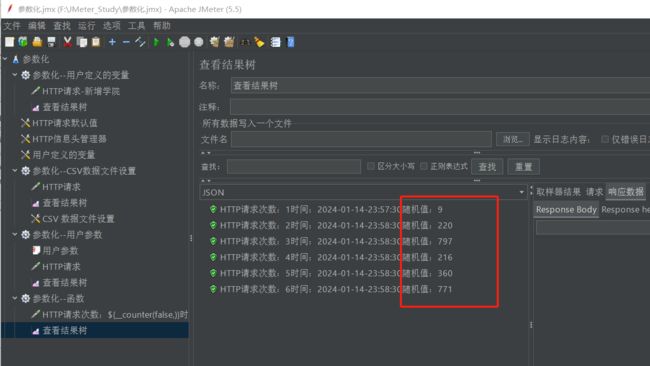
(3)时间函数
选择time,什么也不指定的话,默认是时间戳

如果指定了时间的格式,比如我指定的是
yyyy-MM-dd-HH:mm:ss

执行后看到的效果如下:
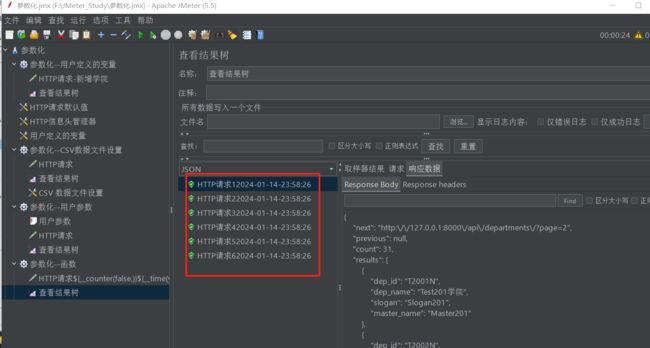
(4)总结函数
HTTP请求次数:${__counter(false,)}
时间:${__time(yyyy-MM-dd HH:mm:ss,)}
随机值:${__Random(1,1000,)}
时间戳:${__time(,)}
6.直连数据库
通过直连数据库让程序代替接口访问数据库,如果二者预期结果不一致,就找到了程序缺陷。
获取某条学院的名字,放在百度搜索:
1、Jmeter 不具备直连数据库功能,必须整合第三方(jar包)实现
2、配置数据库的连接
3、通过JDBC Request请求向数据库发送 SQL语句并接收提取响应结果
4、结果获取规则可以通过 Debug Sampler 组件查看
5、将提取到的响应结果,在百度上
在测试计划中,添加Jar包,这里我们选择数据库的jar包,资料中有


添加-配置元件-JDBC Connection Configuration
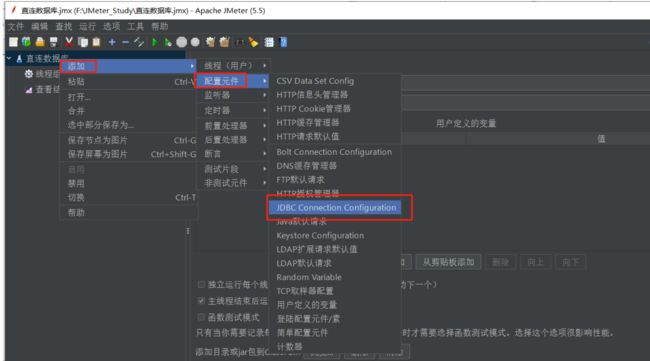
设置数据库连接池
Variable Name for created pool:起一个数据库连接池的名字

Database URL配置如下
Database URL: jdbc:sqlite:F:\JMeter_Study\studentManagementSystem/db.sqlite3
JDBC Driver class:配置如下
org.sqlite.JDBC

添加数据库请求
添加-取样器-JDBC Request
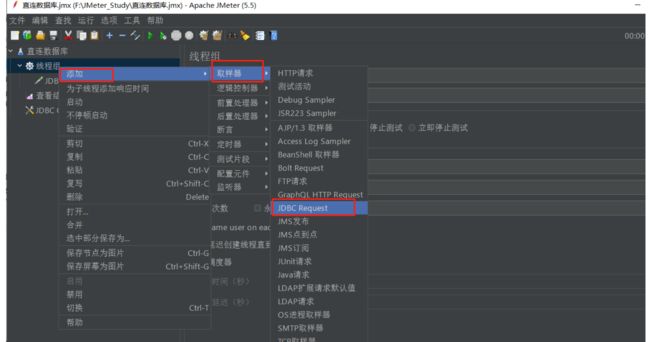
Query Type注意,查询是Select,增删改都是Update

Variable Name of Pool declared in JDBC Connection Configuration:填写的是数据库连接池配置的名字,我这里是myPool
![]()
书写sql如下:
select dep_name from departments;
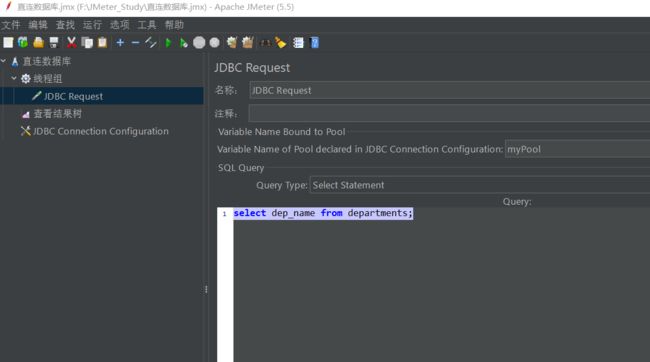
查看结果树如下:

添加-取样器-Dubug Sampler(调试取样器)
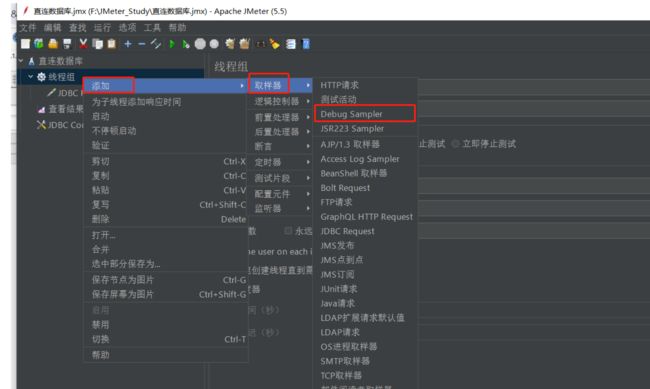
然后去JDBC Request中随便添加一个值
Variable names:dep_name

然后我们运行,查看结果树
发现调试取样器,都是以变量名称命名的

如果我们想访问百度的搜索,需要新建一个HTTP请求,配置如下
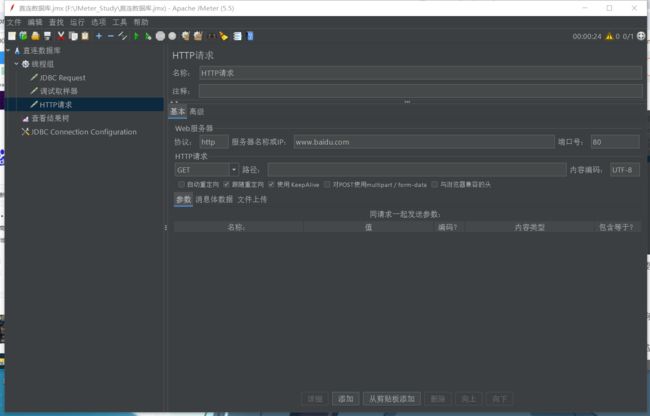
我们搜索黑马,可以看到百度接口是以/s?wd=搜索字段
来规定URL的

于是我们也这么配置
/s?wd=${dep_name_30}
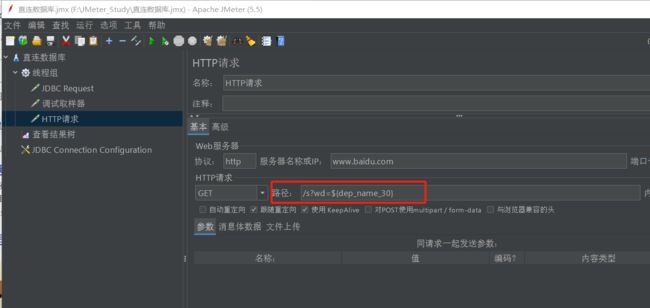
请求后查看结果树,测试结果成功,这里访问百度好像不太行,提示网络不给力

7.断言
- 断言:让程序代替人工判断响应结果是否符合预期
分类: - 响应断言 = 断言状态码和响应体
- 大小断言 = 判断响应内容的字节长度
- 断言持续时间 = 判断响应时间
步骤:
1、按照之前的实现编写测试脚本
2、为被判断的取样器添加断言组件
3、直接运行查看结果断言通过: 无提示
断言失败: 给出错误
添加-断言-响应断言

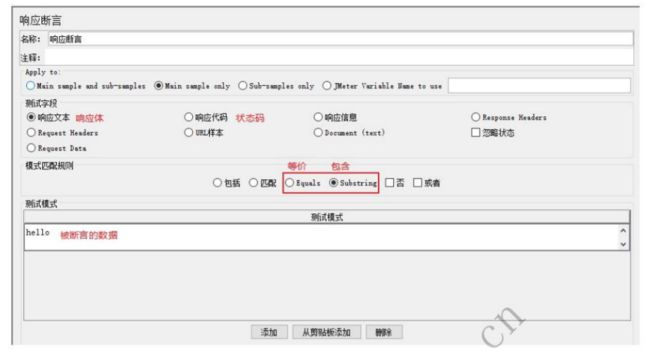
7.1 响应文本
创建好后没选择响应文本,然后选择包括,输入学院
意思就是检索响应结果是否包含学院
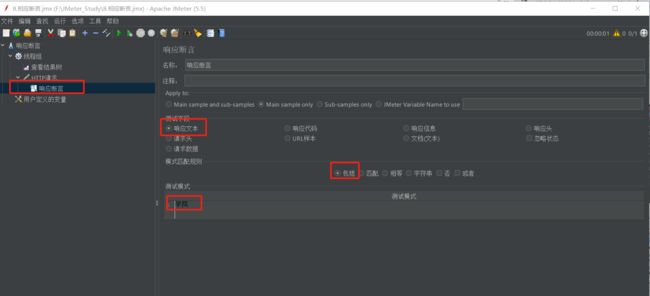
很显然结果是有学院的

如果我们输入一个结果没有的字符串,比如今天

可以看到,虽然返回了结果,但是结果没有今天,所以爆红了

下拉可以看到报错原因:响应断言

一些含义如下:
7.2 响应代码
选择响应代码,其实就是Http的状态码

运行后返回结果如下:

我们如果在模式匹配规则选择了或者

就表示为,响应结果是200或者201都正确
7.3 大小断言
添加-断言-大小断言

大小断言的界面如下:
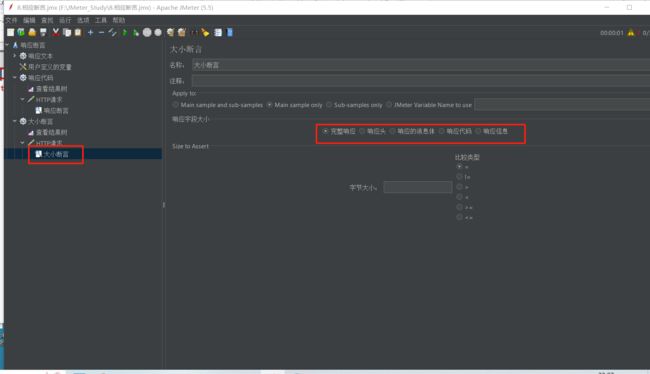
讲述大小断言之前,我们先空调用一次请求,看看结果树

对应关系如下:
| 大小断言名称 | 取样器结果名称 |
|---|---|
| 完整响应 | Size in bytes |
| 响应头 | Headers size in bytes |
| 响应的消息体 | Body size in bytes |
| 响应代码 | Response code |
| 响应信息 | Response message |
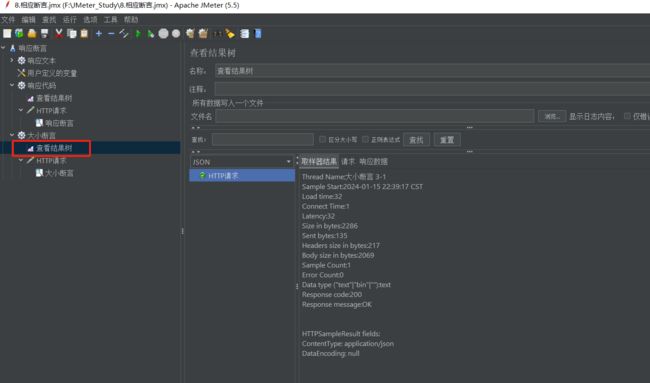
(1)完整响应
比如上面我们空调一次看到的字节长度是2286,那么这里我们就设置2286

查看结果树如下:

(2)响应头
上面空调一次响应头长度是217,这里不妨设置217

查看结果树如下:
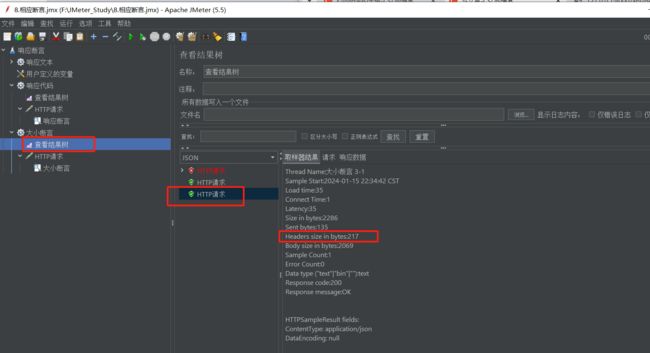
(3)响应的消息体
上面空调一次响应头长度是2069,这里不妨设置2069

查看结果树如下:

(4)响应代码
上面空调一次响应代码是200,这里是填写200吗?
答案是否定的
原因是,这里的响应代码,指的是相应代码的长度,所以我们应该设置的是3
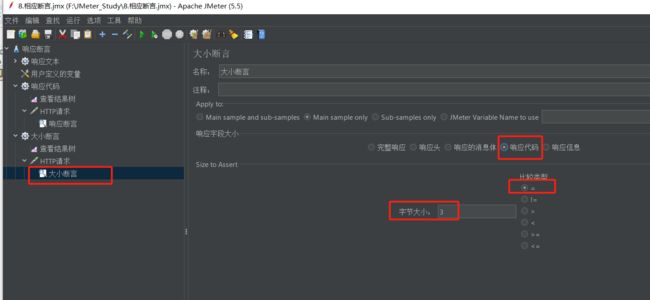
查看结果树如下:

(5)响应信息
上面空调一次响应信息是OK,这里不妨设置OK的长度是2
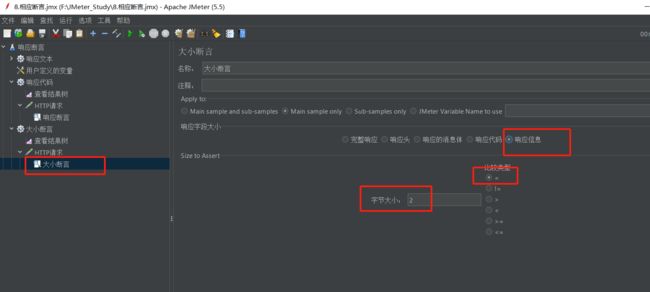
查看结果树:
7.4 断言持续时间
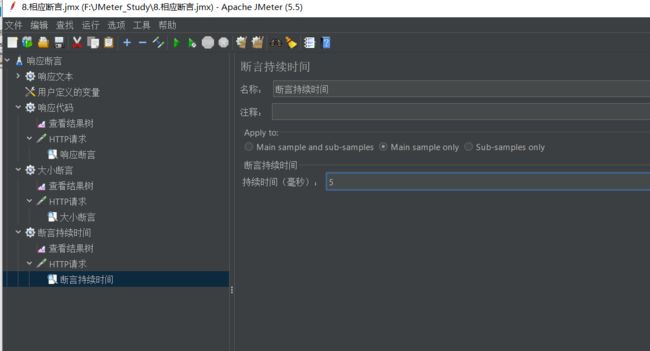
添加-断言-断言持续时间

这里设置持续时间:5毫秒
意思是在5毫秒内,请求到响应是否能够结束
直接运行,查看结果树

我们调整一下持续时长,更改为50
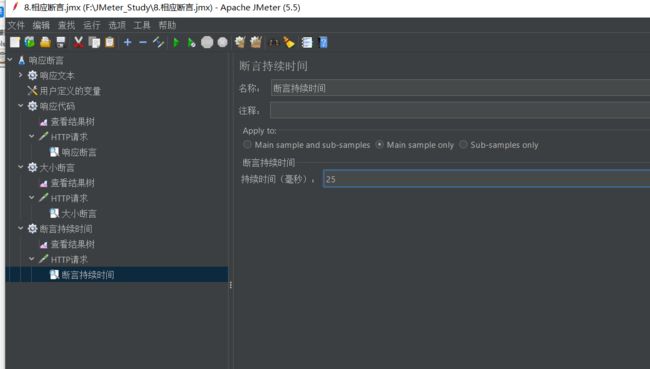
查看结果树就正确了
