LLM之RAG实战(十七)| 高级RAG:通过使用LlamaIndex重新排序来提高检索效率
基本RAG的检索是静态的,会检索到固定数字(k)个相关文档,而如果查询需要更多的上下文(例如摘要)或更少的上下文,该怎么办?
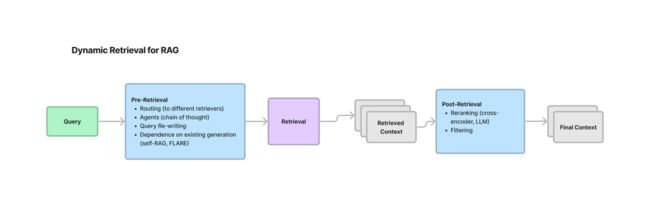
可以通过在以下两个阶段来实现动态检索:
- 预检索:检索器初步选择相关的上下文;
- 检索后:对相关的上下文进行重新排列,并进一步筛选结果
这种动态修剪不相关的上下文非常重要,它允许我们设置一个大的top-k,但仍然可以提高精度。
一、为什么要重排序?
重新排序是检索过程中的一个步骤,根据某些标准对最初检索到的结果进行进一步排序、细化或重新排序,以提高其相关性或准确性。
这里有一个例子:想象一下,你正在搜索有关企鹅的信息。当你输入搜索查询时,系统会很快弹出几篇关于不同类型企鹅的文章。这些结果是基于通用相关性检索获得的。
现在,假设前几篇文章是关于“南极企鹅”的,但你真正想要的是关于“动物园栖息地的企鹅”的信息,那么就需要对这几篇文章进行重新排序了,比如使用用户行为、特定关键字或更复杂的算法来进行该操作。这可能会使有关动物园栖息地的文章在列表中排名更高,降低有关南极洲的文章的排名。这一步骤确保最相关或最有用的信息出现在顶部,使您更容易找到您要查找的内容。
本质上,重新排序微调了最初检索到的结果,基于特定标准或用户偏好提供了一组更具针对性和相关性的文档或信息。
二、基于嵌入的检索有什么问题?
使用基于嵌入的检索有许多优点:
-
使用向量点积快速计算,并且在查询推理期间不需要调用任何模型;
-
嵌入可以对文档和查询进行语义编码,并可以根据查询检索出高度相关的文档。
然而,尽管有这些优点,基于嵌入的检索有时准确性不高,并返回与查询相关的无关上下文,这会大大降低RAG系统的整体质量。
针对上述问题,可以借鉴推荐系统召回和排序两个阶段来解决。第一阶段基于嵌入召回出相关性最高的top-k个文档,该阶段注重召回而非准确性。第二阶段是对召回的top-k个文档进行重新排序。

三、代码实现
大模型:zephyr-7b-alpha
嵌入模型:hkunlp/instructor-large
3.1 加载数据
LlamaIndex通过数据连接器Reader来加载数据,数据连接器可以加载不同数据源的数据,并将数据格式化为Document对象,Document对象会存储文本和对应的元数据(未来会存储图像和音频)。
PDFReader = download_loader("PDFReader")loader = PDFReader()docs = loader.load_data(file=Path("QLoRa.pdf"))
3.2 分块
我们将文本分割成512大小的分块来创建节点Node。Node是LlamaIndex中的原子数据单元,表示源文档的“块”。节点包含元数据以及与其他节点的关系信息。
node_parser = SimpleNodeParser.from_defaults(chunk_size=512)nodes = node_parser.get_nodes_from_documents(docs)
3.3 开源LLM和嵌入
我们将使用开源大模型zephyr-7b-alpha,并对其进行量化,量化后的模型可以运行在Colab免费的T4 GPU上。
在本例中,我们将使用hkunlp/instructor-large指令微调的文本嵌入模型,它可以通过简单地提供任务指令来生成针对任何任务(例如,分类、检索、聚类、文本评估等)定制的文本嵌入,而无需任何微调。在MTEB排行榜(https://huggingface.co/spaces/mteb/leaderboard)上排名第14!
from google.colab import userdata# huggingface and cohere api tokenhf_token = userdata.get('hf_token')quantization_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_compute_dtype=torch.float16,bnb_4bit_quant_type="nf4",bnb_4bit_use_double_quant=True,)def messages_to_prompt(messages):prompt = ""for message in messages:if message.role == 'system':prompt += f"<|system|>\n{message.content}\n"elif message.role == 'user':prompt += f"<|user|>\n{message.content}\n"elif message.role == 'assistant':prompt += f"<|assistant|>\n{message.content}\n"# ensure we start with a system prompt, insert blank if neededif not prompt.startswith("<|system|>\n"):prompt = "<|system|>\n\n" + prompt# add final assistant promptprompt = prompt + "<|assistant|>\n"return prompt# LLMllm = HuggingFaceLLM(model_name="HuggingFaceH4/zephyr-7b-alpha",tokenizer_name="HuggingFaceH4/zephyr-7b-alpha",query_wrapper_prompt=PromptTemplate("<|system|>\n\n<|user|>\n{query_str}\n<|assistant|>\n"),context_window=3900,max_new_tokens=256,model_kwargs={"quantization_config": quantization_config},# tokenizer_kwargs={},generate_kwargs={"temperature": 0.7, "top_k": 50, "top_p": 0.95},messages_to_prompt=messages_to_prompt,device_map="auto",)# Embeddingembed_model = HuggingFaceInstructEmbeddings(model_name="hkunlp/instructor-large", model_kwargs={"device": DEVICE})
3.4 配置索引和检索器
首先,我们将设置ServiceContext对象,并使用它来构造索引和查询。
索引是一种由Document对象组成的数据结构,大模型可以使用该索引进行查询相关上下文。
VectorStoreIndex是最常见和最易于使用的索引,支持在大规模数据语料库上进行检索,包括获取“top-k”个最相似的节点,并将它们传递到“响应合成”模块。
# ServiceContextservice_context = ServiceContext.from_defaults(llm=llm,embed_model=embed_model)# indexvector_index = VectorStoreIndex(nodes, service_context=service_context)# configure retrieverretriever = VectorIndexRetriever(index=vector_index,similarity_top_k=10,service_context=service_context)
3.5 初始化重排序器
我们会评估以下3个重新排序器的性能:
- CohereAI(https://txt.cohere.com/rerank/)
- bge-reranker-base(https://huggingface.co/BAAI/bge-reranker-base)
- bge-reranker-large(https://huggingface.co/BAAI/bge-reranker-large)
# Define all embeddings and rerankersRERANKERS = {"WithoutReranker": "None","CohereRerank": CohereRerank(api_key=cohere_api_key, top_n=5),"bge-reranker-base": SentenceTransformerRerank(model="BAAI/bge-reranker-base", top_n=5),"bge-reranker-large": SentenceTransformerRerank(model="BAAI/bge-reranker-large", top_n=5)}
3.6 检索比较
检索器定义了在给定查询时如何有效地从索引中检索相关上下文。
节点后处理器:节点后处理器接收一组检索到的节点,并对它们进行转换、过滤或重新排序操作。节点后处理器通常在节点检索步骤之后和响应之前应用于查询引擎中。
让我们创建一些助手函数来执行我们的任务:
# helper functionsdef get_retrieved_nodes(query_str, reranker):query_bundle = QueryBundle(query_str)retrieved_nodes = retriever.retrieve(query_bundle)if reranker != "None":retrieved_nodes = reranker.postprocess_nodes(retrieved_nodes, query_bundle)else:retrieved_nodesreturn retrieved_nodesdef pretty_print(df):return display(HTML(df.to_html().replace("\\n", "
")))def visualize_retrieved_nodes(nodes) -> None:result_dicts = []for node in nodes:node = deepcopy(node)node.node.metadata = Nonenode_text = node.node.get_text()node_text = node_text.replace("\n", " ")result_dict = {"Score": node.score, "Text": node_text}result_dicts.append(result_dict)pretty_print(pd.DataFrame(result_dicts))
让我们可视化查询的结果:
query_str = "What are the top features of QLoRA?"# Loop over rerankersfor rerank_name, reranker in RERANKERS.items():print(f"Running Evaluation for Reranker: {rerank_name}")query_bundle = QueryBundle(query_str)retrieved_nodes = retriever.retrieve(query_bundle)if reranker != "None":retrieved_nodes = reranker.postprocess_nodes(retrieved_nodes, query_bundle)else:retrieved_nodesprint(f"Visualize Retrieved Nodes for Reranker: {rerank_name}")visualize_retrieved_nodes(retrieved_nodes)
- 没有重新排序--顶部节点的相似性得分为0.87,这是baseline分数。

- CohereRebank——顶部节点的相似性得分为0.988。

- bge reranker base——顶部节点的相似性得分为0.72。

四、性能评价
现在,我们将使用RetrieverEvaluator来评估我们的Retriever的质量。
我们定义了各种评估指标,如命中率hit-rate和MRR,这些指标根据每个特定问题的ground-truth文本来评估检索结果的质量。为了简化评估数据集的构造,我们采用了合成数据生成方法。
MRR( Mean Reciprocal Rank)表示平均倒数排名,是一个国际上通用的对搜索算法进行评价的机制,并且只评估排名前10个的排名感知相关性得分。第一个结果匹配,分数为1,第二个匹配分数为0.5,第n个匹配分数为1/n,如果没有匹配的句子分数为0。最终的分数为所有得分之和。
hit-rate衡量检索到的结果中至少包含一个与基本事实相关的项目的查询的比例或百分比。例如,想象一个搜索引擎返回一个文档列表来响应用户的查询。这里的基本事实是指该查询的已知相关文档,通常由人类判断或标记数据确定。hit-rate计算搜索结果至少包含一个相关文档的频率。
4.1 构建(查询、上下文)对的评估数据集
我们可以手动构建问题+Node id的检索评估数据集。Llamaindex通过generate_question_context_pairs函数在现有文本语料库上提供合成数据集生成。使用大模型根据每个上下文块自动生成问题,可以参阅:https://docs.llamaindex.ai/en/stable/module_guides/evaluating/usage_pattern_retrieval.html。
这里,我们使用Zephr-7B在现有的文本语料库上构建一个简单的评估数据集,返回的结果是一个EmbeddingQAFinetuneDataset对象(包含queries、relevant_docs和corpus)。
# Prompt to generate questionsqa_generate_prompt_tmpl = """\Context information is below.---------------------{context_str}---------------------Given the context information and not prior knowledge.generate only questions based on the below query.You are a Professor. Your task is to setup \{num_questions_per_chunk} questions for an upcoming \quiz/examination. The questions should be diverse in nature \across the document. The questions should not contain options, not start with Q1/ Q2. \Restrict the questions to the context information provided.\"""# Evaluatorqa_dataset = generate_question_context_pairs(nodes, llm=llm, num_questions_per_chunk=2, qa_generate_prompt_tmpl=qa_generate_prompt_tmpl)
# helper function for displaying resultsdef display_results(reranker_name, eval_results):"""Display results from evaluate."""metric_dicts = []for eval_result in eval_results:metric_dict = eval_result.metric_vals_dictmetric_dicts.append(metric_dict)full_df = pd.DataFrame(metric_dicts)hit_rate = full_df["hit_rate"].mean()mrr = full_df["mrr"].mean()metric_df = pd.DataFrame({"Reranker": [reranker_name], "hit_rate": [hit_rate], "mrr": [mrr]})return metric_df
Llamaindex提供了一个函数,用于在批处理模式下对数据集运行RetrieverEvaluator。
query_str = "What are the top features of QLoRA?"results_df = pd.DataFrame()# Loop over rerankersfor rerank_name, reranker in RERANKERS.items():print(f"Running Evaluation for Reranker: {rerank_name}")query_bundle = QueryBundle(query_str)retrieved_nodes = retriever.retrieve(query_bundle)if reranker != "None":retrieved_nodes = reranker.postprocess_nodes(retrieved_nodes, query_bundle)else:retrieved_nodesretriever_evaluator = RetrieverEvaluator.from_metric_names(["mrr", "hit_rate"], retriever=retriever)eval_results = await retriever_evaluator.aevaluate_dataset(qa_dataset)current_df = display_results(rerank_name, eval_results)results_df = pd.concat([results_df, current_df], ignore_index=True)
4.2 结果
WithoutReranker:为每个嵌入提供了baseline;
CohereRerank:是SOTA结果;
bge-reranker-base:结果比CohereRerank差,也许是因为该模型对这种重新排序无效;
bge-reranker-large:结果比bge-reranker-base差,也许是因为该模型对这种重新排序无效。
结果表明重新排序在优化检索过程中的重要性,尤其是CohereRebank模型。
五、结论
为搜索选择适当的嵌入至关重要;即使是最有效的重新排序也无法弥补较差的基本搜索结果(比如bge-rerankers)。
最大限度地提高检索器的性能取决于发现嵌入和重新排序的最佳组合。这仍然是一个活跃的研究领域,来确定最有效的组合。
参考文献:
[1] https://akash-mathur.medium.com/advanced-rag-enhancing-retrieval-efficiency-through-evaluating-reranker-models-using-llamaindex-3f104f24607e
[2] https://github.com/akashmathur-2212/LLMs-playground/blob/main/LlamaIndex-applications/Advanced-RAG/reranker_models_evaluation/LLM_rerankers_evaluation.ipynb
[3] https://github.com/akashmathur-2212/LLMs-playground/tree/main/LlamaIndex-applications/Advanced-RAG?source=post_page-----3f104f24607e--------------------------------