穿越Flink的时间隧道:解锁实时数据之窗,掌握流处理之巅
目录
Flink中的时间和窗口
1时间语义
1.1Flink中的时间语义
1.1.1处理时间
1.1.2事件时间
1.2那种时间语义更重要
2 水位线
2.1 事件时间和窗口
2.2 什么是水位线
2.3 如何生成水位线
2.3.1使用WatermarkGenerator
2.3.2使用SourceFunction
2.4 水位线的传递
2.5 水位线的总结
2.5.1水位线的作用如下
2.5.2水位线的特性包括
3 窗口
3.1 窗口的概念
3.2 窗口的分类
①时间窗口
②计数窗口
③会话窗口
④全局窗口
3.3 窗口API概述
3.4 窗口分配器
3.5 窗口函数
3.6 测试水位线和窗口的使用
3.7 其他API
3.8 窗口的生命周期
①创建阶段
②加载阶段
③显示阶段
④激活阶段
⑤失去焦点阶段
⑥关闭阶段
⑦销毁阶段
4 迟到数据的处理
4.1 设置水位线延迟时间
①基于时间窗口的水位线延迟
②基于数据量的水位线延迟
③动态调整水位线延迟
4.2 允许窗口处理迟到数据
Flink中的时间和窗口
1时间语义
1.1Flink中的时间语义
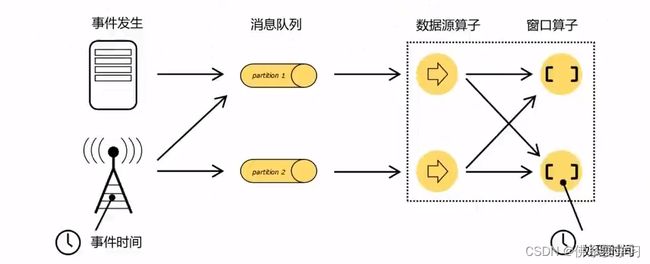
我们重新梳理一下流式数据处理的过程。在事件发生之后,生成的数据被收集起来,首先进入分布式消息队列,然后被Flink系统中的Source算子读取消费,进而向下游的转换算子(窗口算子)传递,最终由窗口算子进行计算处理。
1.1.1处理时间:
处理时间是指执行相应操作的机器的系统时间。当流程序在处理 时间上运行时,所有基于时间的操作(如时间窗口)将使用运行各自
操作符的机器 的系统时间。处理时间是最简单的时间概念,不需要在流和机器之间进行协调。它 提供了最佳的性能和最低的延迟。
但是,在分布式和异步环境中,处理时间不提供 确定性,因为它容易受到记录到达系统的速度(例如从消息队列到达系统)以及系统内算子之间流动速度的影响。
1.1.2事件时间:
事件时间是每个独立事件在产生它的设备上发生的时间,通常在 进入Flink之前就已经嵌入在记录中,可以从每个记录中提取该事件时间戳。在事件时间中,数据产生的时间决定了数据处理的过程,而不是当前系统时间。事件时 间程序必须指定如何生成事件Watermarks,用来保证事件时间的有序性。
1.2那种时间语义更重要
在流处理中,事件时间和处理时间都是重要的时间语义,各有其适用场景和优势。
事件时间基于事件的物理时间或者逻辑时间,可以消除不同系统或数据源之间的时间同步问题,使数据处理结果更符合实际情况。使用事件时间,可以将不同源产生的数据按照实际的时间顺序进行整合,这对于很多应用场景是非常关键的,比如实时分析、实时告警等。
处理时间则是基于当前系统处理记录的时间,具有简单易用的特点,不需要关心数据源的时间戳问题,对于数据的处理速度较快。但是处理时间容易受到数据流速率、系统负载等因素的影响,可能会造成时间的延迟或偏移。
因此,具体选择哪种时间语义要根据实际需求和应用场景来决https://xinghuo.xfyun.cn/desk定。在一些需要精确时间排序和时间相关的聚合操作中,事件时间更为重要;而在一些实时性要求较高但不需要精确时间排序的场景中,处理时间可能更加适合。
2 水位线
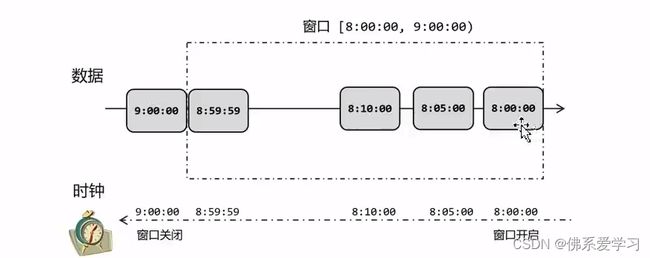
2.1 事件时间和窗口
事件时间和窗口在流处理中具有重要的作用。事件时间是指每个独立事件在其设备上发生的时间,通常在进入Flink之前就已经嵌入到消息中,并且可以从每条消息中提取出来。事件时间程序必须指定如何生成水印,以保持事件时间的有序性。
窗口是Flink中的一类算子,用于将许多事件按照时间或其他特征分组,从而将每一组作为整体进行分析。窗口是DataStream的逻辑边界,常用的窗口有基于时间的窗口和计数窗口。在时间窗口中,数据按照时间进行分组,每个窗口内的数据可以在同一时间进行计算。计数窗口则根据元素的数量进行分组,分为滚动计数窗口和滑动计数窗口。
事件时间是指每个独立事件在产生它的设备上发生的时间,通常在进入Flink之前就已经嵌入在记录中,可以从每条记录中提取该事件时间戳。而窗口则是Flink中的一类算子,用于将许多事件按照时间或其他特征分组,从而将每一组作为整体进行分析。
在事件时间中,窗口的触发和结束是基于时间戳的,需要考虑到时间戳的排序和延迟问题,以保证计算结果的准确性。同时,事件时间语义和窗口也是相互影响的。在使用事件时间时,需要指定如何生成水印,以保持事件时间的有序性。而窗口的边界则可以看作是事件时间的逻辑边界,用于将事件数据分组进行分析。
2.2 什么是水位线
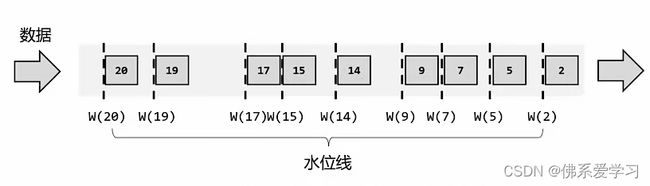
水位线是一种衡量事件时间进展的机制,用于处理实时数据中的乱序问题。它通常与窗口操作结合使用,以确保在窗口计算时能够正确处理乱序到达的数据。
水位线本质上是一个时间戳,用于指示当前的事件时间进展。在数据流中加入一个时钟标记,记录当前的事件时间,这个标记可以直接广播到下游。当下游任务收到这个标记,就可以更新自己的时钟。

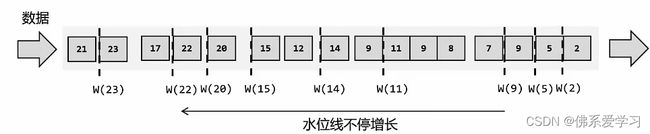

通过水位线,Flink可以在处理乱序数据时,避免无限期地等待延迟数据到达。当到达特定水位线时,Flink认为在那个时间点之前的数据已经全部到达,即使后面还有延迟到达的数据。这样可以触发窗口计算,确保所有并行子任务都能够及时更新事件时间并进行窗口计算。
2.3 如何生成水位线



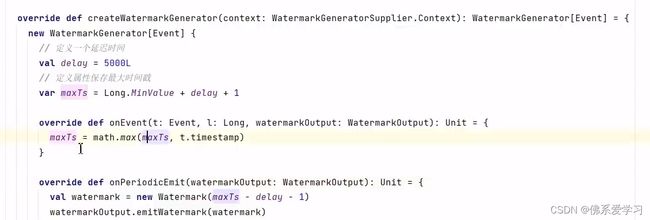
2.3.1使用WatermarkGenerator:
WatermarkGenerator是Flink提供的用于生成水位线的接口。通过实现该接口,可以根据应用程序的需求自定义水位线的生成逻辑。例如,可以根据数据源的时间戳特性来生成相应的水位线。
2.3.2使用SourceFunction:
SourceFunction是Flink中的一种特殊类型的输入数据源,可以用于生成水位线。通过实现SourceFunction,可以自定义一个水位线生成器,根据特定的时间间隔或时间序列生成水位线。
总之无论使用哪种方法,生成的水位线都需要传递给Flink的WatermarkInput的SourceFunction。通过WatermarkInput,Flink可以检测到水位线的到达,并根据水位线更新事件时间戳,以确保乱序数据的正确处理。
2.4 水位线的传递
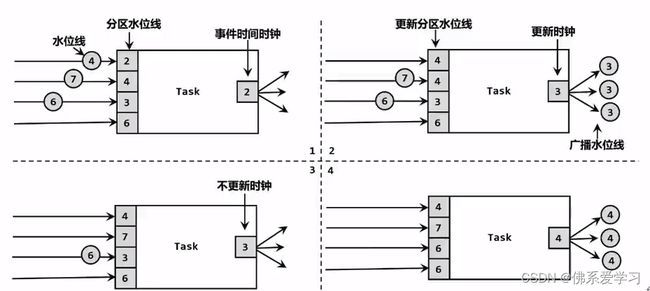
水位线是通过数据流进行传递的。当数据流经过Flink的算子时,水位线会随着数据一起传递给下游算子。下游算子接收到数据和对应的水位线后,会根据当前时钟和水位线的比较结果来决定如何处理数据。
对于每个并行子任务,水位线被用作时间基准,以确保数据按照时间顺序进行计算。通过维护一个时钟变量,每个并行子任务可以跟踪当前的时间戳,并根据水位线来更新自己的时钟。
在Flink中,水位线的传递是必要的,因为它可以帮助解决乱序数据处理问题。当数据在分布式系统中传输时,由于网络延迟、数据源延迟等原因,数据可能会乱序到达。通过使用水位线,Flink可以正确地处理这些乱序数据,确保数据的正确性和实时性。
2.5 水位线的总结
水位线是Flink流处理中保证结果正确性的核心机制,可以看作一条特殊的数据记录,它被插入到数据流中作为一个时间戳的标记点,用于衡量事件时间(Event Time)的进展。
2.5.1水位线的作用如下:
①作为衡量事件时间进展的标记,直接广播到下游。
②保证所有并行子任务都可以及时更新事件时间,进行窗口计算。
③在事件时间的流中,唯一的时间尺度。通过观察水位线的大小,可以知道 当前的时间进展。
④用于触发窗口的闭合以及定时器的触发。
水位线的产生基于数据的时间戳,从数据中提取时间戳作为水位线的时间戳。水位线的默认计算公式是“水位线 = 观察到的最大事件时间 - 最大延迟时间 - 1 毫秒”。在数据流开始之前,Flink会插入一个初始水位线,而在数据流结束时,Flink会插入一个终止水位线。
2.5.2水位线的特性包括:
①单调递增的时间戳,确保任务的事件时间时钟一直向前推进。
②可以周期性地生成,不一定在每个数据之后。
③在上下游任务之间传递时,巧妙地避免了分布式系统中没有统一时钟的问题。每个任务都以“处理完之前所有数据”为标准来确定自己的时钟,从而保证窗口处理的结果总是正确的。
3 窗口
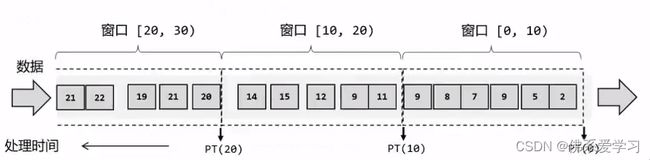
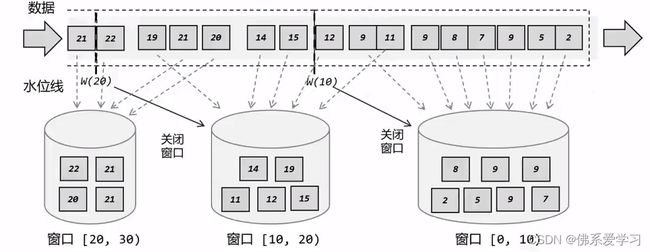
3.1 窗口的概念
窗口是一种处理无界流数据的方式,将无限数据切割成有限的“数据块”进行处理。窗口是用来处理无界流的核心,可以很容易地想象成一个固定位置的“框”,数据源源不断地流过来,到某个时间点窗口该关闭了,就停止收集数据、触发计算并输出结果。
窗口的分类包括时间窗口、计数窗口、会话窗口和全局窗口等。其中,时间窗口是最常用的一种窗口,它支持滚动和滑动两种类型。滚动窗口是在固定时间生成一个窗口,例如每小时生成一个窗口;滑动窗口则是在滑动时间生成一个窗口,例如每5分钟生成一个窗口。
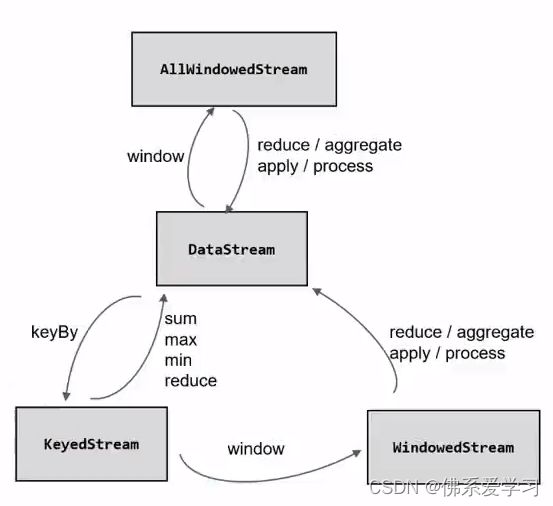
在Flink中,窗口是通过WindowedStream来定义的,WindowedStream是DataStream和KeyedStream的组合。通过将数据流划分成多个窗口,可以对每个窗口内的数据进行聚合、分析等操作。
3.2 窗口的分类
窗口的分类主要有以下几种:
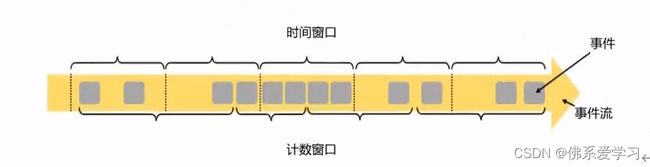
①时间窗口:
时间窗口是以时间点来定义窗口的开始与结束,截取出的就是某一段时间的数据。时间窗口的时间范围都是左闭右开的原则,即[start,end)。
②计数窗口:
计数窗口基于元素的个数来截取数据,到达固定的个数时就触发计算并关闭窗口。计数窗口相比时间窗口更加简单,只需要指定窗口大小,就可以把数据分配到对应的窗口当中。
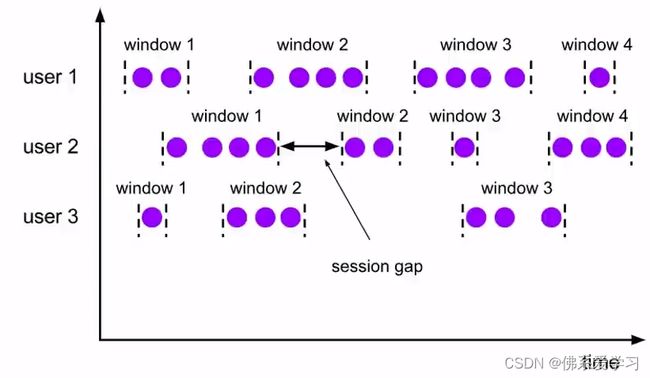
③会话窗口:
会话窗口由一系列事件组合一个指定事件长度的timeout间隔组成,即一段时间没有收到新数据就会生成新的窗口。会话窗口的特点是时间不对齐。
④全局窗口:
全局窗口是一个按照指定的数据条数生成一个Window,与时间无关。
此外,根据窗口分配数据的规则,时间窗口和计数窗口又可以分为滚动窗口和滑动窗口。

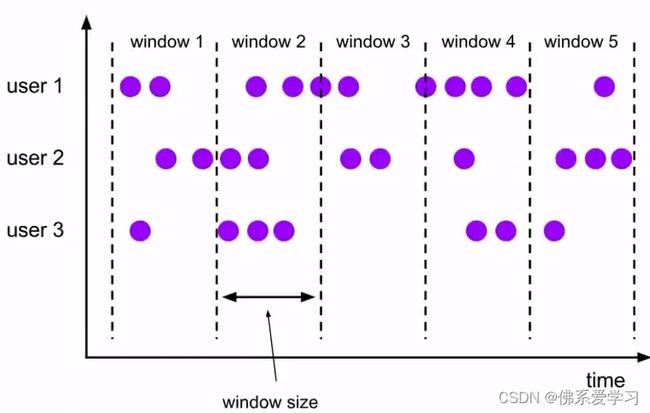
滚动窗口:
滑动窗口:
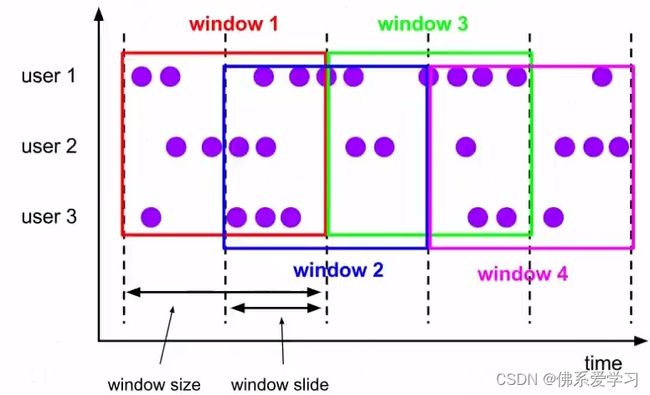
滚动窗口有固定的大小,是一种对数据进行“均匀切片”的划分方式,窗口之间没有重叠,也不会有间隔。滑动窗口滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成,特点为窗口长度固定,可以有重叠。
3.3 窗口API概述
窗口API是Flink中用于处理无界流数据的重要工具,它提供了对窗口操作的封装和定义。
在Flink中,可以通过WindowedStream来定义窗口操作,它是DataStream和KeyedStream的组合。通过将数据流划分成多个窗口,可以对每个窗口内的数据进行聚合、分析等操作。
窗口API的调用包括以下几个步骤:
①定义窗口:使用WindowedStream来定义窗口操作,并指定窗口的类型、大小、滑动距离等参数。
②定义窗口函数:窗口函数是用于处理每个窗口内数据的函数,可以根据具体需求选择不同的窗口函数,如计数器、累加器等。
③触发窗口计算:根据需要选择合适的触发条件,如时间触发、计数触发等,来触发窗口计算。
④输出结果:将计算结果输出到目标系统中,如数据库、文件等。
3.4 窗口分配器
窗口分配器是Flink中用于分配窗口的组件,用于将数据流划分成多个窗口,以便对每个窗口内的数据进行处理和分析。
在Flink中,有两种常见的窗口分配器:时间窗口分配器和计数窗口分配器。时间窗口分配器基于时间戳来分配窗口,将数据流按照时间划分为不同的窗口。计数窗口分配器则基于元素的个数来分配窗口,将数据流按照固定的大小划分为不同的窗口。
3.5 窗口函数
窗口函数是Flink中用于处理窗口内数据的函数,可以对每个窗口内的数据进行聚合、分析等操作。
常见的窗口函数包括计数器、求和、平均值、最大值、最小值等,可以根据具体需求选择不同的窗口函数。
窗口函数的实现通常包括以下几个步骤:
①定义窗口函数:根据业务需求和数据特性,选择合适的窗口函数,并实现相应的计算逻辑。
②绑定窗口函数到窗口:将窗口函数绑定到具体的窗口上,以便在触发计算时能够调用该函数对窗口内的数据进行处理。
③触发计算:根据触发条件,触发窗口内的数据计算,并调用相应的窗口函数进行数据处理。
④输出结果:将计算结果输出到目标系统中,如数据库、文件等。
总之,窗口函数是Flink中处理无界流数据的重要工具,它可以根据具体需求选择不同的窗口函数,对每个窗口内的数据进行聚合、分析等操作。通过使用合适的窗口函数,可以更好地处理和分析无界流数据,为业务决策提供有力支持。
3.6 测试水位线和窗口的使用
要测试水位线和窗口的使用,可以按照以下步骤进行:
①准备数据源:创建一个数据源,用于生成模拟数据。可以使用随机数生成器或其他方式生成模拟数据,确保数据源能够按照时间戳顺序生成数据。
②创建Flink程序:使用Flink API编写程序,实现水位线和窗口操作。首先定义窗口分配器和窗口函数,然后使用WindowedStream将窗口操作应用到数据流上。
③定义水位线:根据数据源的时间戳特性,定义合适的水位线生成策略。可以使用WatermarkGenerator或SourceFunction生成水位线,并将其传递给下游任务。
④启动Flink程序:将编写好的Flink程序提交给Flink集群执行。确保Flink集群配置正确,能够接收和处理数据。
⑤观察结果:监控Flink程序的执行过程和结果。可以通过查看日志、监控界面或使用打印函数等方式输出结果,观察水位线和窗口操作是否正确执行,并验证计算结果的准确性。
⑥分析和优化:根据观察结果,分析水位线和窗口操作的使用是否符合预期,是否存在问题或瓶颈。根据分析结果进行优化,调整窗口大小、触发条件等参数,提高处理性能和准确性。
3.7 其他API
①DataStream API:DataStream API是Flink中最基本的API,用于处理无界数据流。它提供了丰富的操作符和函数,可以对数据进行各种转换、过滤、聚合等操作。
②KeyedStream API:KeyedStream API是DataStream API的子类,用于处理具有键值的数据流。它提供了基于键的聚合、窗口等操作,可以对具有相同键的数据进行分组、聚合等操作。
③ConnectedStream API:ConnectedStream API用于处理两个相关联的数据流,可以在这两个数据流之间进行关联、组合等操作。它能够将两个数据流中的数据关联起来,以便更好地分析和处理。
④Table API:Table API是Flink中用于处理结构化数据的API,它可以方便地将数据流转换成表格形式,并进行查询和计算。Table API基于SQL语言,支持各种SQL查询和聚合函数。
⑤SQL API:SQL API是Flink中用于处理结构化数据的另一种API,它支持标准的SQL查询和聚合函数。通过使用SQL API,开发人员可以方便地编写SQL查询语句来处理数据流。
3.8 窗口的生命周期
窗口的生命周期主要包括以下几个阶段:
①创建阶段:
当数据流进入Flink程序时,首先会通过PreCreateWindow函数进行预处理,然后通过OnGetMinMaxInfo函数获取每个数据项的最小和最大时间戳。接下来,会调用OnNcCreate函数进行窗口的创建。在这个阶段,窗口的资源还没有完全生成,例如窗口的句柄、图标、光标和背景等。
②加载阶段:
当窗口创建完成后,会进入加载阶段。在这个阶段,Flink会根据窗口的类型和配置,将窗口加载到内存中,并完成窗口的绘制和界面元素的初始化。这个阶段是自动完成的,开发人员通常不需要关心这个阶段的实现细节。
③显示阶段:
当窗口加载完成后,会进入显示阶段。在这个阶段,窗口会显示在屏幕上,并且可以进行各种用户交互操作,例如点击、拖拽等。
④激活阶段:
当用户激活某个窗口时,该窗口就会进入激活状态。在Flink中,窗口的激活状态是通过任务栏和系统菜单来管理的。当用户单击窗口的标题栏或在任务栏中选择该窗口时,系统会将焦点切换到该窗口并将其激活。
⑤失去焦点阶段:
当用户切换到其他窗口或最小化当前窗口时,当前窗口就会失去焦点并进入失去焦点状态。在Flink中,当窗口失去焦点时,会触发失去焦点事件。
⑥关闭阶段:
当用户单击窗口右上角的关闭按钮或在任务栏中选择关闭窗口时,会触发关闭事件。在这个阶段,Flink会执行一些清理操作,例如释放窗口占用的资源。
⑦销毁阶段:
当窗口被销毁时,会触发销毁事件。在这个阶段,窗口对象占用的内存空间会被系统回收。
4 迟到数据的处理
4.1 设置水位线延迟时间
设置水位线延迟时间是为了处理分布式网络传输导致的数据乱序问题。在网络传输中,由于各种原因,数据可能会乱序到达。设置合适的水位线延迟时间,可以确保数据的顺序正确,提高流处理的实时性。
具体设置水位线延迟时间的方法可能因不同的应用程序和数据处理需求而有所不同。一些常见的方法包括:
①基于时间窗口的水位线延迟:
根据时间窗口的大小,设置一个合适的时间延迟作为水位线。例如,如果使用小时时间窗口,可以将水位线延迟设置为几分钟到几秒钟,以确保大部分数据在窗口内到达。
②基于数据量的水位线延迟:
根据数据流的大小,设置一个合适的数据量作为水位线。例如,如果处理的数据量较大,可以将水位线延迟设置为几百毫秒到几秒,以确保大部分数据在触发计算前到达。
③动态调整水位线延迟:
根据实际的数据到达情况和计算结果,动态调整水位线延迟。这种方法需要对数据流进行实时监控和分析,以确定最优的水位线延迟时间。
4.2 允许窗口处理迟到数据
Flink的窗口允许设置延迟时间,允许继续处理迟到数据。当水位线已经到了窗口结束时间,默认窗口就会关闭,那么之后再来的数据就要被丢弃。但是,如果设置了延迟时间,窗口会保持开启状态,等待迟到的数据。每来一条数据,窗口就会再次计算,并将更新后的结果输出。这样就可以逐步修正计算结果,最终得到准确的统计值。
Flink还提供了多种窗口函数来处理迟到数据,如TUMBLE、HOP、OVER、CUMULATE等。这些窗口函数支持延迟时间设置,并且还支持在窗口接收到迟到数据时输出当前窗口的开始时间和结束时间。这可以帮助开发人员更好地了解和处理迟到数据,提高处理结果的准确性。