求解最长回文子串问题及Manacher算法
题目:求字符串的最长回文子串
回文子串的定义: 给定字符串str,若s同时满足以下条件: s是str的子串 , s是回文串 则,s是str的回文子串。
思路一:暴力穷举
穷举字符串的所有子串,对每一个进行判断是否为回文串
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
暴力求解
"""
def Longpalindrome(src, slen):
if slen == 0:
return None
if slen == 1:
return src
max_length = 0
palindromic = ''
for i in range(slen):
for j in range(i+1, slen):
is_palindromic = True
for k in range(i, int((i+j)/2)+1):
if src[k] != src[j-k+i]:
is_palindromic = False
break
if is_palindromic and (j-i+1) > max_length:
max_length = j-i+1
palindromic = src[i:j+1]
return palindromic
if __name__ == '__main__':
src = 'abcdzdcab'
slen = len(src)
res = Longpalindrome(src, slen)
print(src,' 最长回文子串是:',res)时间复杂度为O(n*n*n)
思路二:最长公共子串
反转S,变成T,S与T的最长公共子串Y就是最长回文子串。
当S="abacdfgdcaba"时,T="abacdgfdcaba",Y="abacd",很明显Y不是回文串。
因此每当我们找到一个最长的公共子串的时候,要检查其是否是回文串。
代码略,可参考前面的公共子串相关博文自己写
思路三: 枚举中心位置
通过枚举字符串子串的中心而不是起点,向两边同时扩散,依然是逐一判断子串的回文性。这种优化算法比之前第一种算法在最坏的情况下(即只有一种字符的字符串)效率会有很大程度的上升。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
枚举中心位置
"""
def Longpalindrome2(src, slen):
if slen == 0:
return None
if slen == 1:
return src
max_length = 0
palindromic = ''
for i in range(slen):
x = 1 # 回文串长度为奇数
while (i - x) >= 0 and (i + x) < slen:
if src[i + x] == src[i - x]:
x += 1
else:
break
x -= 1
if 2 * x + 1 > max_length:
max_length = 2 * x + 1
palindromic = src[i - x:i + x + 1]
x = 0 # 回文串长度为偶数
if (i + 1) < slen:
while (i - x) >= 0 and (i + 1 + x) < slen:
if src[i + 1 + x] == src[i - x]:
x += 1
else:
break
x -= 1
if 2 * x + 2 > max_length:
max_length = 2 * x + 2
palindromic = src[i - x:i + x + 2]
return palindromic
if __name__ == '__main__':
src = 'abcdzdcab'
slen = len(src)
res = Longpalindrome2(src, slen)
print(src, ' 最长回文子串是:', res)
思路四:动态规划
优化方法一,我们可以在验证子字符串是否是回文串时避免不必要的重新计算。
对于子字符串"ababa",如果我们知道"bab"是一个回文,很明显左右字母相同,所以,"ababa"是一个回文串;

所以,在这种情况下,我们可以采用递归的方式解决问题。我们先初始化所有一个字母的回文串和两个字母的回文串,并找出所有三个字母的回文串,以此类推。
时间和空间复杂度为O(n*n),n为字符串的长度,会有(2n)个子字符串,验证每个子字符串是否是回文需要O(n)
空间复杂度为O(n*n),用来存储表
基本思路是对任意字符串,如果头和尾相同,那么它的最长回文子串一定是去头去尾之后的部分的最长回文子串加上头和尾。
如果头和尾不同,那么它的最长回文子串是去头的部分的最长回文子串和去尾的部分的最长回文子串的较长的那一个。
P[i,j]P[i,j]表示第i到第j个字符的回文子串数
dp[i,i]=1dp[i,i]=1
dp[i,j]=dp[i+1,j−1]+2|s[i]=s[j]
dp[i,j]=dp[i+1,j−1]+2|s[i]=s[j]
dp[i,j]=max(dp[i+1,j],dp[i,j−1])|s[i]!=s[j]
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
动态规划
"""
def Longpalindrome3(s):
n = len(s)
maxl = 0
start = 0
for i in range(n):
if i - maxl >= 1 and s[i - maxl - 1: i + 1] == s[i - maxl - 1: i + 1][::-1]:
start = i - maxl - 1
maxl += 2
continue
if i - maxl >= 0 and s[i - maxl: i + 1] == s[i - maxl: i + 1][::-1]:
start = i - maxl
maxl += 1
return s[start: start + maxl]
if __name__ == '__main__':
src = 'abcdzdcab'
res = Longpalindrome3(src)
print(src, ' 最长回文子串是:', res)思路五:Manacher算法(本文重点介绍)
该算法可以把时间复杂度提升到O(n)
算法过程分析:
1,预处理:由于回文分为偶回文(比如 bccb)和奇回文(比如 bcacb),而在处理奇偶问题上会比较繁琐,所以这里我们使用一个技巧,具体做法是:在字符串首尾,及各字符间各插入一个字符(前提这个字符未出现在串里)。
长度为n的字符串,共有n-1个 “邻接” ,加上首字符的前面,和末字符的后面,共 n+1的“空”(gap)。因此,字符串本身和gap一起,共 有2n+1个,必定是奇数;
举个例子:s="abbahopxpo",转换为s_new="$#a#b#b#a#h#o#p#x#p#o#"(这里的字符 $ 只是为了防止越界,下面代码会有说明),如此,s 里起初有一个偶回文abba和一个奇回文opxpo,被转换为#a#b#b#a#和#o#p#x#p#o#,长度都转换成了奇数。
定义一个辅助数组int p[],其中p[i]表示以 i 为中心的最长回文的半径,例如:
| i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| s_new[i] | $ | # | a | # | b | # | b | # | a | # | h | # | o | # | p | # | x | # | p | # |
| p[i] | 1 | 2 | 1 | 2 | 5 | 2 | 1 | 2 | 1 | 2 | 1 | 2 | 1 | 2 | 1 | 4 | 1 | 2 | 1 |
可以看出,p[i] - 1正好是原字符串中最长回文串的长度。
证明,首先在转换得到的字符串s_new中,所有的回文字串的长度都为奇数,那么对于以p[i]为中心的最长回文字串,其长度就为2*p[i]-1,经过观察可知,s_new中所有的回文子串,其中分隔符的数量一定比其他字符的数量多1,也就是有p[i]个分隔符,剩下p[i]-1个字符来自原字符串,所以该回文串在原字符串中的长度就为p[i]-1。
2,接下来的重点就是求解 p 数组,如下图:
思考过程:
这个算法的最核心的一行如下:
p[i] = mx > i ? min(p[2 * id - i], mx - i) : 1;
如果mx > i, 则 p[i] = min( p[2 * id - i] , mx - i )
否则, p[i] = 1

当 mx - i > P[j] 的时候,以S[j]为中心的回文子串包含在以S[id]为中心的回文子串中,由于 i 和 j 对称,以S[i]为中心的回文子串必然包含在以S[id]为中心的回文子串中,所以必有 P[i] = P[j],见下图。

当 P[j] >= mx - i 的时候,以S[j]为中心的回文子串不一定完全包含于以S[id]为中心的回文子串中,但是基于对称性可知,下图中两个绿框所包围的部分是相同的,也就是说以S[i]为中心的回文子串,其向右至少会扩张到mx的位置,也就是说 P[i] >= mx - i。至于mx之后的部分是否对称,就只能老老实实去匹配了。

对于 mx <= i 的情况,无法对 P[i]做更多的假设,只能P[i] = 1,然后再去匹配了。
详细解释:根据回文的性质,p[i]的值基于以下三种情况得出:
(1):j 的回文串有一部分在 id 的之外,如下图: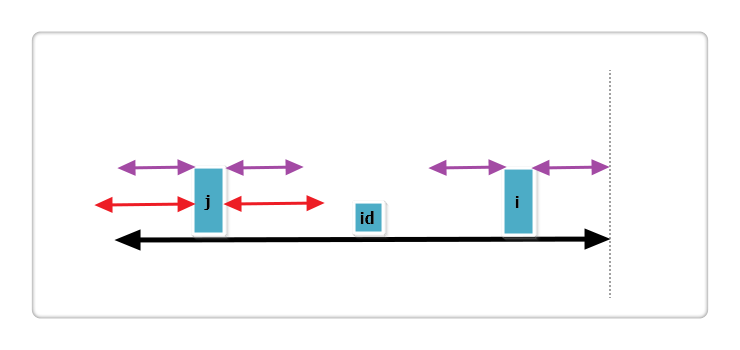
上图中,黑线为 id 的回文,i 与 j 关于 id 对称,红线为 j 的回文。那么根据代码此时p[i] = mx - i,即紫线。那么p[i]还可以更大么?答案是不可能!见下图:
假设右侧新增的紫色部分是p[i]可以增加的部分,那么根据回文的性质,a 等于 d ,也就是说 id 的回文不仅仅是黑线,而是黑线+两条紫线,矛盾,所以假设不成立,故p[i] = mx - i,不可以再增加一分。
(2):j 回文串全部在 id 的内部,如下图: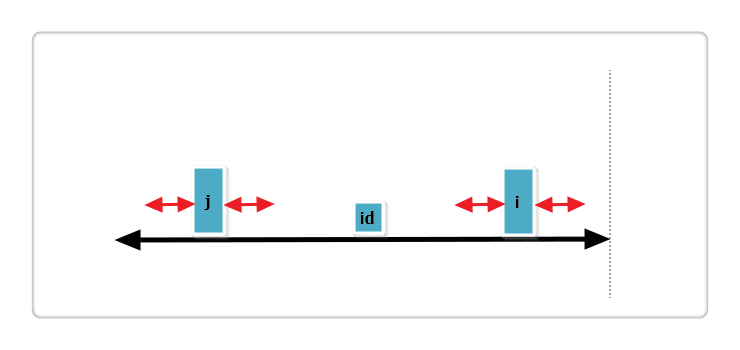
根据代码,此时p[i] = p[j],那么p[i]还可以更大么?答案亦是不可能!见下图: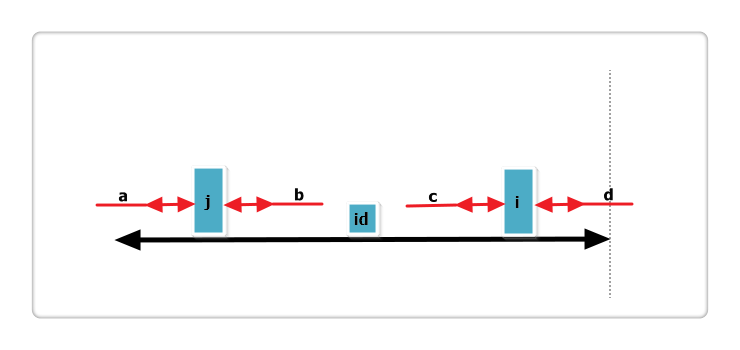
假设右侧新增的红色部分是p[i]可以增加的部分,那么根据回文的性质,a 等于 b ,也就是说 j 的回文应该再加上 a 和 b ,矛盾,所以假设不成立,故p[i] = p[j],也不可以再增加一分。
(3):j 回文串左端正好与 id 的回文串左端重合,见下图:
根据代码,此时p[i] = p[j]或p[i] = mx - i,并且p[i]还可以继续增加,所以需要
while (s_new[i - p[i]] == s_new[i + p[i]])
p[i]++;#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
manacher算法
"""
def Manacher(s):
lens = len(s)
f = [] # 辅助列表:f[i]表示i作中心的最长回文子串的长度 p
maxj = 0 # 记录对i右边影响最大的字符位置j id
maxl = 0 # 记录j影响范围的右边界 mx
maxd = 0 # 记录最长的回文子串长度
for i in range(lens): # 遍历字符串
if maxl > i:
count = min(maxl - i, int(f[2 * maxj - i] / 2) + 1) # 这里为了方便后续计算使用count,其表示当前字符到其影响范围的右边界的距离
else:
count = 1
while i - count >= 0 and i + count < lens and s[i - count] == s[i + count]: # 两边扩展
count += 1
if (i - 1 + count) > maxl: # 更新影响范围最大的字符j及其右边界
maxl, maxj = i - 1 + count, i
f.append(count * 2 - 1)
maxd = max(maxd, f[i]) # 更新回文子串最长长度
return int((maxd + 1) / 2) - 1 # 去除特殊字符
def manacher(s: str) -> list:
# s = '#' + '#'.join(s0) + '#'
l = len(s)
r = [0] * l
mx, pos = 0, 0
for i in range(l):
if i > mx:
r[i] = 1
else:
r[i] = min(r[2 * pos - i], mx - i)
while i - r[i] >= 0 and i + r[i] < l and s[i + r[i]] == s[i - r[i]]:
r[i] += 1
if r[i] + i - 1 > mx:
mx = r[i] + i - 1
pos = i
return r
if __name__ == '__main__':
src = 'abcdzdcab'
src = '#' + '#'.join(src) + '#' # 字符串预处理,用特殊字符隔离字符串,方便处理偶数子串
res = Manacher(src)
print(src, ' 最长回文子串是:', res)
res1 = manacher(src)
print(src, ' 最长回文子串是:', res1)Manacher复杂度分析
文章开头已经提及,Manacher算法为线性算法,即使最差情况下其时间复杂度亦为O(n),
根据上面的分析,很容易推出Manacher算法的最坏情况,即为字符串内全是相同字符的时候。在这里我们重点研究Manacher()中的for语句,推算发现for语句内平均访问每个字符5次,即时间复杂度为:T_{worst}(n)=O(n)。
同理,我们也很容易知道最佳情况下的时间复杂度,即字符串内字符各不相同的时候。推算得平均访问每个字符4次,即时间复杂度为:T_{best}(n)=O(n)。
综上,Manacher算法的时间复杂度为O(n)。
思路六:
while k < lenS - 1 and s[k] == s[k + 1]: k += 1 is very efficient and can handle both odd-length (abbba) and even-length (abbbba).
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
__mtime__ = '2018/9/29'
"""
def Longpalindrome4(s):
lenS = len(s)
if lenS <= 1: return s
minStart, maxLen, i = 0, 1, 0
while i < lenS:
if lenS - i <= maxLen / 2: break
j, k = i, i
while k < lenS - 1 and s[k] == s[k + 1]: k += 1
i = k + 1
while k < lenS - 1 and j and s[k + 1] == s[j - 1]: k, j = k + 1, j - 1
if k - j + 1 > maxLen: minStart, maxLen = j, k - j + 1
return s[minStart: minStart + maxLen]
if __name__ == '__main__':
src = 'abcdzdcab'
res = Longpalindrome4(src)
print(src, ' 最长回文子串是:', res)