探索JAVA神秘运行机制:揭秘JVM内存区域
目录
1. 前文回顾
2.内存区域的划分
2.1 存放类的方法区
2.2 程序计数器
2.3 Java虚拟机栈
2.4 Java堆内存
2.5 其他内存区域
3. 核心内存区域运行流程
4. 总结
1. 前文回顾
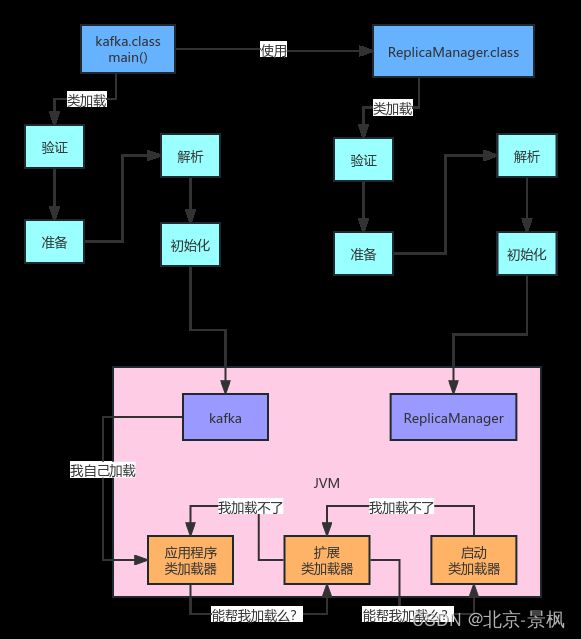
上一篇我们一起探索了Java的整体运行流程,类加载器以及类的加载机制,了解了从编译打包后生成的字节码文件,JVM启动后,类的加载时机,加载之后验证,准备,解析都是做什么的,以及尤为重要的是准备阶段和初始化阶段,是如何为类分配内存空间的?然后类加载器的规则是什么?来看下下图,简单回顾下内容
2.内存区域的划分
接上一篇的问题,我们编写的类在内存中到底是什么样子的,又是如何进行划分的呢?在看之前想一个问题,我们都知道,就是我们要用的类通过类加载器加载后,在内存中会分配一块空间出来进行存储,我们看一个类,主要分为类名称、属性、方法、代码块这几个部分,那么他们在内存中是如何存储的,是统一的放到一起,还是分开来放的?我们执行的代码,调用的方法是不是要一个个的执行他们在内存中是如何进行的,方法中的变量是不是要放到一起?我们带着这些问题,一起来看下内存区域的划分。
2.1 存放类的方法区
这个方法区是在JDK1.8以前的版本里,代表JVM中的一块区域。主要是放从".class"文件里加载进来的类,还会有一些类似常量池的东西放在这个区域里。但是在JDK1.8以后,这块区域的名字改了,叫做"Metaspace",可以认为是"元数据空间”这样的意思。当然这里主要还是存放我们自己写的各种类相关的信息(主要是包括类信息、常量、静态变量等类的结构信息)。其实,我倒是认为jdk1.8 升级后,改的名字更加的贴切,元数据信息空间,也就是主要存储类的元数据信息。
2.2 程序计数器
程序计数器这个的概念理解,其实说的简单点就是:我们写好的Java代码会被翻译成字节码,对应各种字节码指令。所以当JVM加载类信息到内存之后,实际就会使用自己的字节码执行引擎,去执行我们写的代码编译出来的代码指令,而在执行的过程中,由于是多个线程执行的,为了保证每个线程执行的不错误,能够方便的知道执行到那个字节码位置,需要有一个东西来记录下他们执行的位置,这个就引出来“程序计数器” 这一个概念了。那么我们现在明确了"程序计数器”这个概念:用来记录当前执行的字节码指令的位置的,也就是记录目前执行到了哪一条字节码指令。
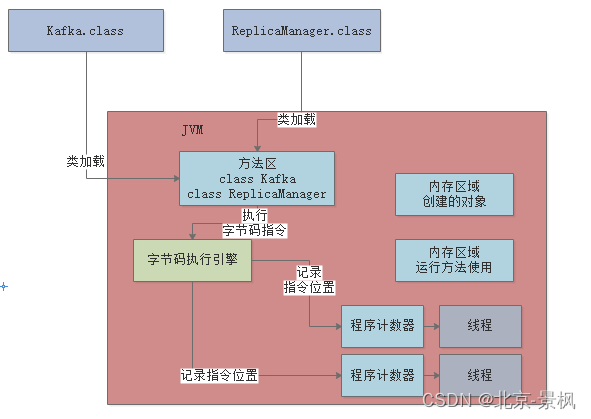
2.3 Java虚拟机栈
这个Java虚拟机栈概念也很好理解,我先一步一步的引入这个概念,首先我们都知道Java代码在执行的时候,一定是线程来执行某个方法中的代码,就是最主要的main线程执行main()方法的代码指令的时候,也会通过main线程对应的程序计数器记录自己执行的指令位置。但是呢,在执行方法内部是时候,我们通常会定义一些局部变量出来,此时问题来,我们用的这些局部变量,每个线程执行这个方法的时候都会使用这个局部变量,是不是要有个地方用来储存吧,因此,JVM必须有一块区域是来保存每个方法内的局部变量等数据的,这个区域就是Java虚拟机栈。
每个线程都有自己的Java虚拟机栈,比如这里的main线程就会有自己的一个Java虚拟机栈,用来存放自己执行的那些方法的局部变量。如果线程执行了一个方法,就会对这个方法调用创建对应的一个栈帧,栈帧里面包含的有方法的局部变量表、操作数栈、动态链接、方法出口等东西,这里大家先不用全都理解,我们先关注局部变量。
比如main线程执行了main()方法,那么就会给这个main()方法创建一个栈帧,压入main线程的Java虚拟机栈,同时在main()方法的栈帧里,会存放对应的"replicaManager"局部变量,我们称之为把局部变量压入栈帧, 等到方法执行完毕后,局部变量就会从这个Java虚拟机栈里面出栈。这个就是我们平常使用方法内部的局部变量的执行过程。
简单的理解这个是我们写的类里面执行的方法,中间使用到的局部变量这些东西,有个客栈或者理解成工具箱,专门储存这些东西,等到方法执行的时候,会把局部变量进来,等待使用,使用完了就移除来了,这个过程就是局部变量的入栈出栈。
2.4 Java堆内存
我们前面说了,Java的类结构等信息存在了方法区,线程执行的字节码执行的位置信息在程序计数器中,类的方法内局部变量信息在运行时,存储在Java虚拟机栈中,那么还剩下什么呢?我们类写好了,也都已经加载完了,但是我们还有个操作是什么呢?对象的实例化,对象实例化我们放在那呢?JVM也为我们想到了,这块区域就是堆内存。Java堆内存,这里就是存放我们在代码中创建的各种对象的。
public class Kafka {
public static void main(String[] args){
ReplicaManager replicaManager = new ReplicaManager();
replicamanager.loadReplicasFromDisk();
}
}我们在代码中用的时候呢,其实是结合着来的,Java堆内存是存放实例化的对象,例如,我们写的代码执行的main() 方法,里面的局部变量被放入到了Java虚拟机栈中,然后又进行了实例化对象,Java堆内存区域里会放入类似ReplicaManager的对象,然后我们因为在main方法里创建了ReplicaManager对象的,那么在线程执行main方法代码的时候,就会在main方法对应的栈顿的局部变量表里,让一个引用类型的"replicaManager"局部变量来存放ReplicaManager对象的地址。 相当于你可以认为局部变量表里的"eplicaManager"指向了Java堆内存里的ReplicaManager对象。
2.5 其他内存区域
上面说了平常我们主要用到的一些区域,我们其实还有其他的一些区域,比如IO相关的,NIO相关的,网络Socket相关的,如果大家去看他内部的源码,会发现很多地方都不是Java代码了,而是走的native方法去调用本地操作系统里面的一些方法,可能调用的都是c语言写的方法,或者一些底层类库,比如下面这样的:public native int hashCode(); 在调用这种native方法的时候,就会有线程对应的本地方法栈,这个里面也是跟Java虚拟机栈类似的,也是存放各种native方法的局部变量表之类的信息。
还有一个区域,是不属于JVM的,通过NIO中的alocateDirect这种AP,可以在Java堆外分配内存空间。然后,通过Java虚拟机里的DirectByteBuffer来引用和操作堆外内存空间。其实很多技术都会用这种方式,因为有一些场景下,堆外内存分配可以提升性能。
3. 核心内存区域运行流程
jvm内存区域的划分,我们已经讲完了,那么我串起来整体过下他的流程,这样就更能加深印象,先来一个图:
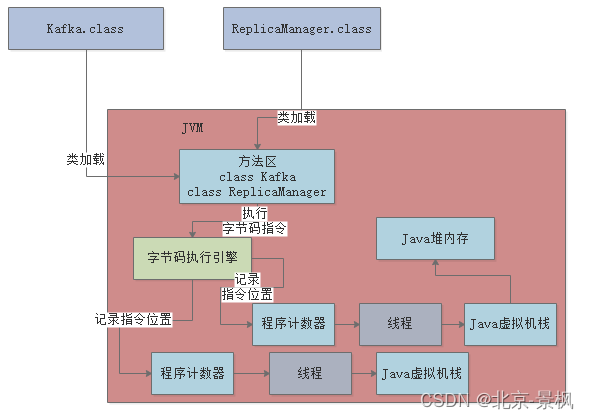
根据上图我们再来一段代码,整体的说下流程:
public class Kafka {
public static void main(String[] args){
ReplicaManager replicaManager = new ReplicaManager();
replicamanager.loadReplicasFromDisk();
}
public class ReplicaManager{
private long replicaCount;
public void loadReplicasFromDisk(){
Boolean hasFinishedLoad = false;
if(isLocalDatacorrupt()) {}
}
public Boolean isLocalDatacorrupt(){
Boolean isCorrupt = false;
return isCorrupt;
}
}
}我们一起来看下上面的过程,首先,你的JVM进程会启动,就会先加载你的Kaika类到内存里。然后有一个main线程,开始执行你的Kaika中的main()方法。main线程是关联了一个程序计数器的,那么他执行到哪一行指令,就会记录在这里。其次,就是main线程在执行main()方法的时候,会在main线程关联的Java虚拟机栈里,压入一个main()方法的栈帧。接着会发现需要创建一个ReplicaManager类的实例对象,此时会加载ReplicaManager类到内存里来。然后会创建一个ReplicaManager的对象实例分配在Java堆内存里,并且在main()方法的栈帧里的局部变量表引入一个“replicaManager”变量,让他引用ReplicaManager对象在Java堆内存中的地址。接着,main线程开始执行ReplicaManager对象中的方法,会依次把自己执行到的方法对应的栈顿压入自己的Java虚拟机栈,执行完方法之后再把方法对应的栈顿从Java虚拟机栈里出栈。
其实大家理解了这个过程,那么JVM中的各个核心内存区域的功能和对应的我们的Java代码之间的关系,就彻底理解了。
4. 总结
好了,最后我们做个总结,JVM为我们把各个地方的区域都做好了设计,我们最后来梳理下:(1)方法区:Java类的结构信息,元数据存储区域;
(2)程序计数器:用来记录当前执行的字节码指令的位置的;
(3)Java虚拟机栈:用来保存每个方法内的局部变量等数据的;
(4)Java堆内存:用来存放我们在代码中创建的各种对象的;
(5)其他的内存区域:本地方法栈、堆外内存;
经过内存区域的划分了解,我们知道了JVM是如何对内存进行划分的,了解了Java的类中各个部件在内存中是如何存储的?我们解决了存储的问题。那么,他在运行过程中又是如何进行调用这些数据的,调用过程中又是如何进行回收的呢?会不会出现内存溢出,又是如何处理的呢?我们带着这些疑问,等到下一篇文章在说,JVM的垃圾回收机制来解答。