CVPR 2023 Hybrid Tutorial: All Things ViTs之CLIP注意力机制可视化
1.总述
All Things ViTs系列讲座从ViT视觉模型注意力机制出发,阐述了注意力机制在多模态模型如CLIP,及diffusion模型中的应用.本文给出CLIP注意力机制可视化部分阅读学习体会.
课程视频与课件: https://all-things-vits.github.io/atv/
代码: https://colab.research.google.com/github/all-things-vits/code-samples/blob/main/explainability/CLIP_explainability.ipynb
CLIP模型是一种文本图像对其模型,本文提供的可视化代码是参考论文Generic Attention-model Explainability for Interpreting Bi-Modal and Encoder-Decoder Transformers给出.可视化的结果为输入文本与图像的对应注意力机制热力图(Relevancy):

2.注意力机制热力图(Relevancy)计算关键代码讲解
要获得注意力机制热力图结果,关键代码如下:
def interpret(image, texts, model, device, start_layer=start_layer, start_layer_text=start_layer_text):
batch_size = texts.shape[0]
images = image.repeat(batch_size, 1, 1, 1)
logits_per_image, logits_per_text = model(images, texts) # logits_per_text, no use,calculate the similarity between text and images
probs = logits_per_image.softmax(dim=-1).detach().cpu().numpy()
index = [i for i in range(batch_size)]
one_hot = np.zeros((logits_per_image.shape[0], logits_per_image.shape[1]), dtype=np.float32)
one_hot[torch.arange(logits_per_image.shape[0]), index] = 1
one_hot = torch.from_numpy(one_hot).requires_grad_(True)
one_hot = torch.sum(one_hot.cuda() * logits_per_image)
model.zero_grad()
image_attn_blocks = list(dict(model.visual.transformer.resblocks.named_children()).values())
if start_layer == -1:
# calculate index of last layer
start_layer = len(image_attn_blocks) - 1
num_tokens = image_attn_blocks[0].attn_probs.shape[-1]
R = torch.eye(num_tokens, num_tokens, dtype=image_attn_blocks[0].attn_probs.dtype).to(device)
R = R.unsqueeze(0).expand(batch_size, num_tokens, num_tokens)
for i, blk in enumerate(image_attn_blocks):
if i < start_layer:
continue
grad = torch.autograd.grad(one_hot, [blk.attn_probs], retain_graph=True)[0].detach() #计算one_hot关于注意力概率(blk.attn_probs)的梯度
cam = blk.attn_probs.detach() # [12, 50, 50]
cam = cam.reshape(-1, cam.shape[-1], cam.shape[-1])
grad = grad.reshape(-1, grad.shape[-1], grad.shape[-1])
cam = grad * cam
cam = cam.reshape(batch_size, -1, cam.shape[-1], cam.shape[-1])
cam = cam.clamp(min=0).mean(dim=1)
R = R + torch.bmm(cam, R)
image_relevance = R[:, 0, 1:] #[1, 49],cls token with other patch tokens
text_attn_blocks = list(dict(model.transformer.resblocks.named_children()).values())
if start_layer_text == -1:
# calculate index of last layer
start_layer_text = len(text_attn_blocks) - 1
num_tokens = text_attn_blocks[0].attn_probs.shape[-1]
R_text = torch.eye(num_tokens, num_tokens, dtype=text_attn_blocks[0].attn_probs.dtype).to(device)
R_text = R_text.unsqueeze(0).expand(batch_size, num_tokens, num_tokens)
for i, blk in enumerate(text_attn_blocks):
if i < start_layer_text:
continue
grad = torch.autograd.grad(one_hot, [blk.attn_probs], retain_graph=True)[0].detach()
cam = blk.attn_probs.detach() # [8, 77, 77]
cam = cam.reshape(-1, cam.shape[-1], cam.shape[-1])
grad = grad.reshape(-1, grad.shape[-1], grad.shape[-1])# [8, 77, 77]
cam = grad * cam
cam = cam.reshape(batch_size, -1, cam.shape[-1], cam.shape[-1])# [1, 8, 77, 77]
cam = cam.clamp(min=0).mean(dim=1)
R_text = R_text + torch.bmm(cam, R_text)
text_relevance = R_text # [1, 77, 77], text_relevance[0, 6, :] not zero
return text_relevance, image_relevance
这段代码首先将图像文本对输入CLIP模型后,拿到one-hot输出,分别对CLIP中ViT网络最后一层及文本网络最后一层计算Grad-Cam注意力机制分数.其中:
grad = torch.autograd.grad(one_hot, [blk.attn_probs], retain_graph=True)[0].detach()
cam = blk.attn_probs.detach()
cam = cam.reshape(batch_size, -1, cam.shape[-1], cam.shape[-1])# [1, 8, 77, 77]
cam = cam.clamp(min=0).mean(dim=1)
分别为了求梯度及注意力机制分数,并将二者进行加权去除负影响,并求期望,对应原文中:

最终的注意力热图需要将每一层的注意力热图累加,因此上述代码中会循环累加:
R = R + torch.bmm(cam, R)
对应论文中:

上述公式中,阐述了但一模态与多模态的注意力机制的累加方式.但讲座给出的代码看起来没有给出多模态注意力机制累加.
对于ViT网络,最后抽取CLS token与其他token的联系进行可视化:
image_relevance = R[:, 0, 1:]
文本模块的注意力机制计算累加与ViT模块类似,但没有抽取CLS token,而是在可视化代码中做进一步处理.
3.可视化模块代码讲解
可视化模块包括图像可视化与文本可视化,图像可视化代码如下:
def show_image_relevance(image_relevance, image, orig_image):
# create heatmap from mask on image
def show_cam_on_image(img, mask):
heatmap = cv2.applyColorMap(np.uint8(255 * mask), cv2.COLORMAP_JET)
heatmap = np.float32(heatmap) / 255
cam = heatmap + np.float32(img)
cam = cam / np.max(cam)
return cam
fig, axs = plt.subplots(1, 2)
axs[0].imshow(orig_image);
axs[0].axis('off');
dim = int(image_relevance.numel() ** 0.5) # 7
image_relevance = image_relevance.reshape(1, 1, dim, dim) # [1, 1, 7, 7]
image_relevance = torch.nn.functional.interpolate(image_relevance, size=224, mode='bilinear') # [1, 1, 224, 224]
image_relevance = image_relevance.reshape(224, 224).cuda().data.cpu().numpy()
image_relevance = (image_relevance - image_relevance.min()) / (image_relevance.max() - image_relevance.min())
image = image[0].permute(1, 2, 0).data.cpu().numpy()
image = (image - image.min()) / (image.max() - image.min())
vis = show_cam_on_image(image, image_relevance)
vis = np.uint8(255 * vis)
vis = cv2.cvtColor(np.array(vis), cv2.COLOR_RGB2BGR)
axs[1].imshow(vis);
axs[1].axis('off');
上述代码做了一些维度与插值变换,最后与原始图像进行叠加.文本可视化代码如下:
def show_heatmap_on_text(text, text_encoding, R_text):
CLS_idx = text_encoding.argmax(dim=-1) # 6,
R_text = R_text[CLS_idx, 1:CLS_idx] # [5,], cls token with sentence tokens attention
text_scores = R_text / R_text.sum()
text_scores = text_scores.flatten()
print(text_scores)
text_tokens=_tokenizer.encode(text)
text_tokens_decoded=[_tokenizer.decode([a]) for a in text_tokens]
vis_data_records = [visualization.VisualizationDataRecord(text_scores,0,0,0,0,0,text_tokens_decoded,1)]
visualization.visualize_text(vis_data_records)
由于对NLP不是很熟悉,这段代码理解还不够充分.经过查阅,text_encoding.argmax(dim=-1)应该是获取能够代表文本特征的向量,有些类似于ViT中的CLS token.展开R_text可以发现,除了抽取出来的R_text,其他元素都为0.对这一部分了解的朋友可以给出更详细阐述.
4.总结
该部分展示了如何可视化多模态模型如CLIP的注意力机制热图,实际在论文中还探讨了如下三种多模态模型的可视化方式:
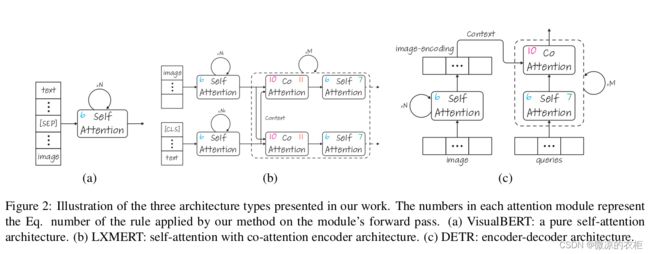
有兴趣的朋友可以进一步探究原文的代码.