字符函数和字符串函数(全面讲解)
字符函数和字符串函数
-
- 1. 字符分类函数
-
- 1.1 islower函数
- 2. 字符转换函数
- 3. strlen的使用和模拟实现
- 4. strcpy 的使用和模拟实现
- 5. strcat 的使用和模拟实现
- 6. strcmp 的使用和模拟实现
- 7. strncpy 函数的使用
- 8. strncat 函数的使用
- 9. strncmp函数的使用
- 10. strstr 的使用和模拟实现
- 11. strtok 函数的使用
- 12. strerror 函数的使用
- 12. perror 函数的使用
在编程的过程中,我们经常要处理字符和字符串,为了⽅便操作字符和字符串,C语⾔标准库中提供了⼀系列库函数,接下来我们就学习⼀下这些函数。
1. 字符分类函数
C语⾔中有⼀系列的函数是专⻔做字符分类的,也就是⼀个字符是属于什么类型的字符的。这些函数的使⽤都需要包含⼀个头⽂件是ctype.h

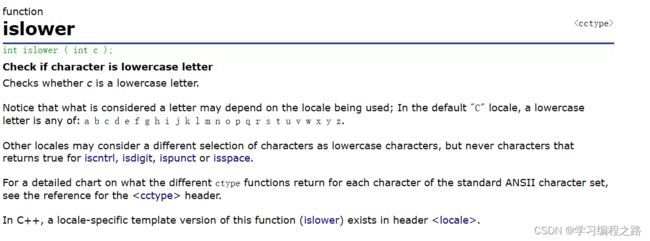
1.1 islower函数
int islower ( int c );
islower 是能够判断参数部分的 c 是否是⼩写字⺟的。
通过返回值来说明是否是⼩写字⺟,如果是⼩写字⺟就返回⾮0的整数,如果不是⼩写字⺟,则返回0。
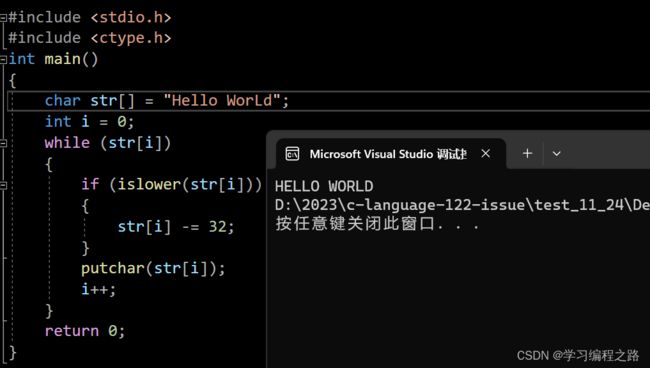
练习:
写⼀个代码,将字符串中的⼩写字⺟转⼤写,其他字符不变。
#include 运行结果如图:
2. 字符转换函数
C语⾔提供了2个字符转换函数:
int tolower ( int c ); //将参数传进去的⼤写字⺟转⼩写
int toupper ( int c ); //将参数传进去的⼩写字⺟转⼤写
上⾯的代码,我们将⼩写转⼤写,是-32完成的效果,有了转换函数,就可以直接使⽤ tolower 函数。
#include 运行结果:

3. strlen的使用和模拟实现

size_t strlen ( const char * str );
- 字符串以 ‘\0’ 作为结束标志,strlen函数返回的是在字符串中 ‘\0’ 前⾯出现的字符个数(不包含 ‘\0’ )。
- 参数指向的字符串必须要以 ‘\0’ 结束。
- 注意函数的返回值为size_t,是⽆符号的( 易错 )
- strlen的使⽤需要包含头⽂件
#include 运行结果如图:

因为,strlen返回值是size_t类型,无符号数相减还是无符号数,所以,结果不可能为负数
strlen的模拟实现
方式1:
//计数器⽅式
int my_strlen(const char* str)
{
int count = 0;
assert(str);
while (*str)
{
count++;
str++;
}
return count;
}
方式2:
mystlen("abcdef")
1 + mystrlen("bcdef")
1 + 1 + mystrlen("cdef")
1 + 1 + 1 + mystrlen("def")
1 + 1 + 1 + 1 + mystrlen("ef")
1 + 1 + 1 + 1 + 1 + mystrlen("f")
1 + 1 + 1 + 1 + 1 + 1 + mystrlen("")
1 + 1 + 1 + 1 + 1 + 1 + 0
#include 运行结果:

方式3:
#include 运行结果如图:

4. strcpy 的使用和模拟实现

char* strcpy(char * destination, const char * source );
- 源字符串必须以 ‘\0’ 结束。
- 会将源字符串中的 ‘\0’ 拷⻉到⽬标空间。
- ⽬标空间必须⾜够⼤,以确保能存放源字符串。
- ⽬标空间必须可修改。
strcpy的模拟实现::
#include 运行结果:
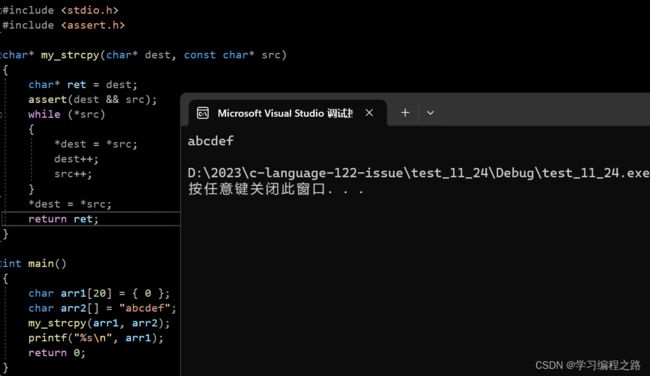
这个代码还可以简化为这样
char* my_strcpy(char* dest, const char* src)
{
char* ret = dest;
assert(dest && src);
while (*dest++ = *src++)
{
;
}
return ret;
}
int main()
{
char arr1[20] = { 0 };
char arr2[] = "abcdef";
my_strcpy(arr1, arr2);
printf("%s\n", arr1);
return 0;
}
运行结果如图:

5. strcat 的使用和模拟实现

char * strcat ( char * destination, const char * source );
- 源字符串必须以 ‘\0’ 结束。
- ⽬标字符串中也得有 \0 ,否则没办法知道追加从哪⾥开始。
- ⽬标空间必须有⾜够的⼤,能容纳下源字符串的内容。
- ⽬标空间必须可修改。
模拟实现strcat函数:
#include 运行结果如图:

6. strcmp 的使用和模拟实现

int strcmp ( const char * str1, const char * str2 );
- 标准规定:
- 第⼀个字符串⼤于第⼆个字符串,则返回⼤于0的数字
- 第⼀个字符串等于第⼆个字符串,则返回0
- 第⼀个字符串⼩于第⼆个字符串,则返回⼩于0的数字
- 那么如何判断两个字符串? ⽐较两个字符串中对应位置上字符ASCII码值的⼤⼩。
strcmp函数的模拟实现:
#include 方法二
#include 7. strncpy 函数的使用
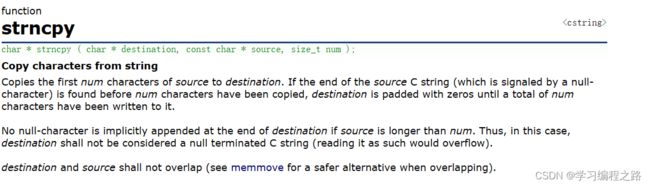
char * strncpy ( char * destination, const char * source, size_t num );
- 拷⻉num个字符从源字符串到⽬标空间。
- 如果源字符串的⻓度⼩于num,则拷⻉完源字符串之后,在⽬标的后边追加0,直到num个。
#include 通过监视可以观察到:
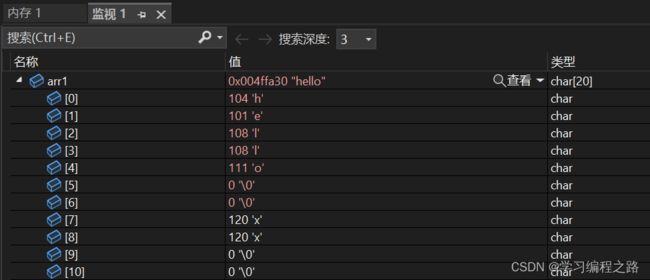
如果源字符串的⻓度⼩于num,则拷⻉完源字符串之后,在⽬标的后边追加0,直到num个。
8. strncat 函数的使用
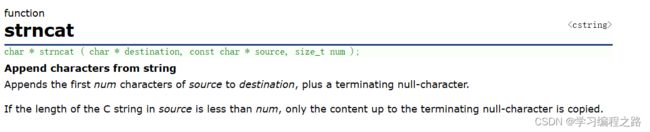
char * strncat ( char * destination, const char * source, size_t num );
- 将source指向字符串的前num个字符追加到destination指向的字符串末尾,再追加⼀个 \0 字符。
- 如果source 指向的字符串的⻓度⼩于num的时候,只会将字符串中到\0 的内容追加到destination指向的字符串末尾。
#include 通过监视可以观察到:
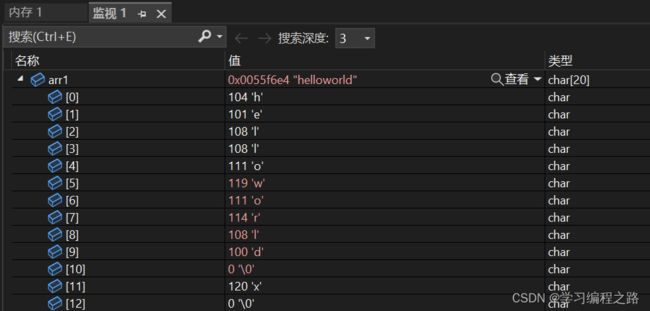
如果source 指向的字符串的⻓度⼩于num的时候,只会将字符串中到\0 的内容追加到destination指向的字符串末尾。
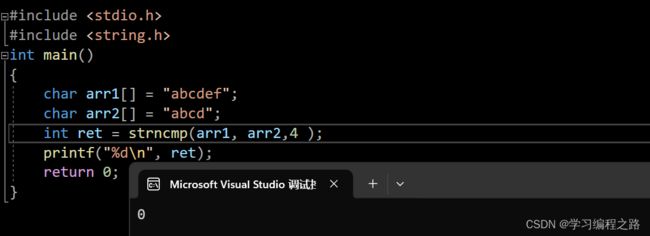
9. strncmp函数的使用

int strncmp ( const char * str1, const char * str2, size_t num );
⽐较str1和str2的前num个字符,如果相等就继续往后⽐较,最多⽐较num个字⺟,如果提前发现不⼀样,就提前结束,⼤的字符所在的字符串⼤于另外⼀个。如果num个字符都相等,就是相等返回0.

#include 运行结果如图:
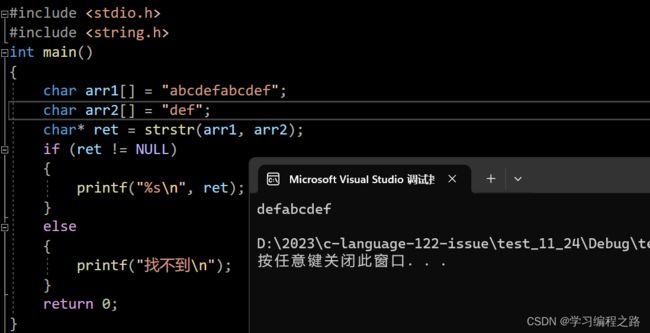
10. strstr 的使用和模拟实现

char * strstr ( const char * str1, const char * str2);
- 函数返回字符串str2在字符串str1中第⼀次出现的位置。
- 字符串的⽐较匹配不包含 \0 字符,以 \0 作为结束标志。
#include 运行结果如图:
返回字符串str2在字符串str1中第⼀次出现的位置
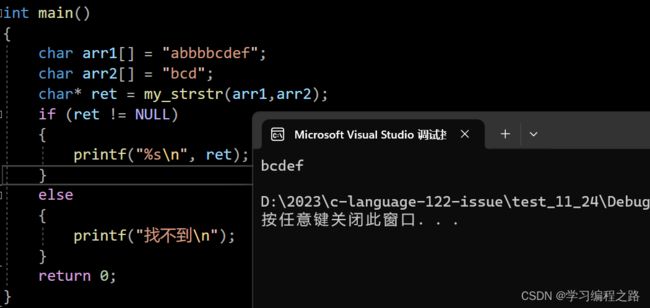
strstr的模拟实现:
#include 运行结果如图:
11. strtok 函数的使用

char * strtok ( char * str, const char * sep);
- sep参数指向⼀个字符串,定义了⽤作分隔符的字符集合
- 第⼀个参数指定⼀个字符串,它包含了0个或者多个由sep字符串中⼀个或者多个分隔符分割的标记。
- strtok函数找到str中的下⼀个标记,并将其⽤ \0 结尾,返回⼀个指向这个标记的指针。(注:strtok函数会改变被操作的字符串,所以在使⽤strtok函数切分的字符串⼀般都是临时拷⻉的内容并且可修改。)
- strtok函数的第⼀个参数不为NULL ,函数将找到str中第⼀个标记,strtok函数将保存它在字符串中的位置。
- strtok函数的第⼀个参数为 NULL ,函数将在同⼀个字符串中被保存的位置开始,查找下⼀个标记。
- 如果字符串中不存在更多的标记,则返回 NULL 指针。
#include 运行结果如图:
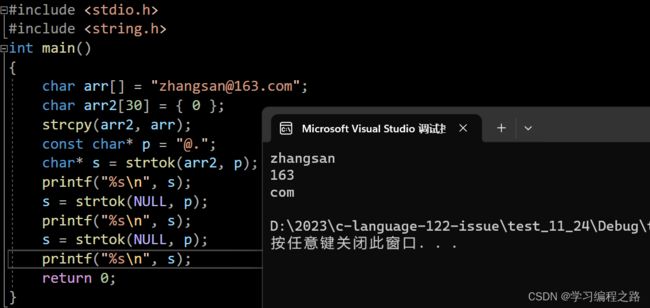
for循环打印分隔字符串的内容
#include 运行结果如图:
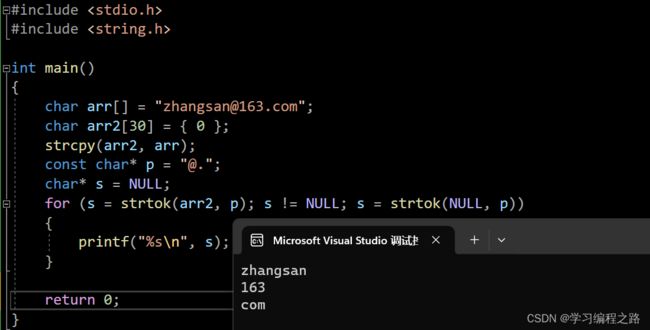
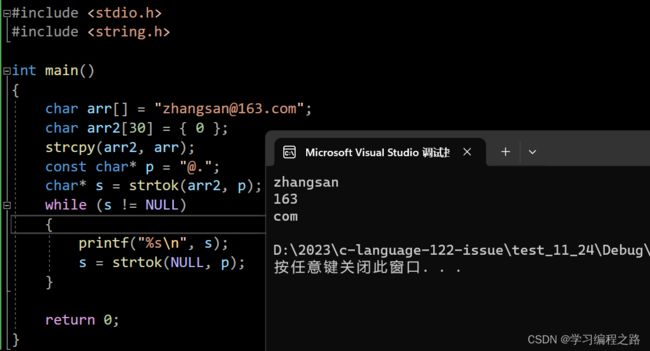
while循环打印分隔字符串的内容
#include 运行结果如图:
12. strerror 函数的使用

char * strerror ( int errnum );
strerror函数可以把参数部分错误码对应的错误信息的字符串地址返回来。
在不同的系统和C语⾔标准库的实现中都规定了⼀些错误码,⼀般是放在 errno.h 这个头⽂件中说明的,C语⾔程序启动的时候就会使⽤⼀个全⾯的变量 errno来记录程序的当前错误码,只不过程序启动的时候 errno是0,表⽰没有错误,当我们在使⽤标准库中的函数的时候发⽣了某种错误,就会将对应的错误码,存放在 errno中,⽽⼀个错误码的数字是整数很难理解是什么意思,所以每⼀个错误码都是有对应的错误信息的。 strerror函数就可以将错误对应的错误信息字符串的地址返回。
#include 在Windows11+VS2022环境下输出的结果如下:
0: No error
1: Operation not permitted
2: No such file or directory
3: No such process
4: Interrupted function call
5: Input/output error
6: No such device or address
7: Arg list too long
8: Exec format error
9: Bad file descriptor
10: No child processes
举例:
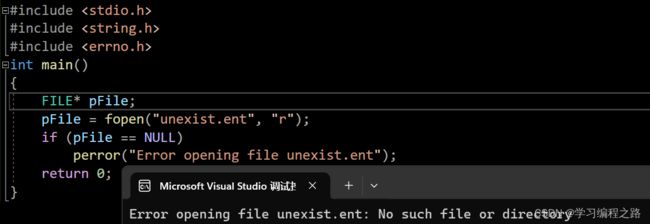
#include 运行结果如图:
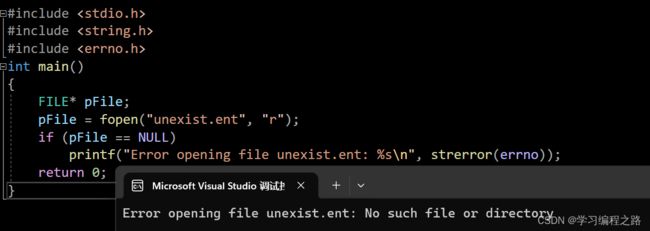
12. perror 函数的使用

void perror ( const char * str );
perror直接将错误信息打印出来。perror函数打印完参数部分的字符串后,再打印⼀个冒号和⼀个空格,再打印错误信息。
#include