Linux高性能服务器 笔记
第一章 TCP/IP协议簇
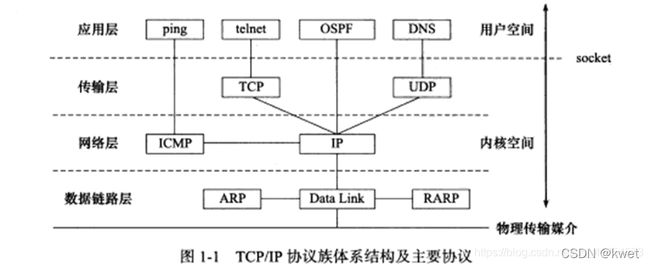
这里每层的协议的功能就不再重复了。主要有个清晰的了解
** 重点**
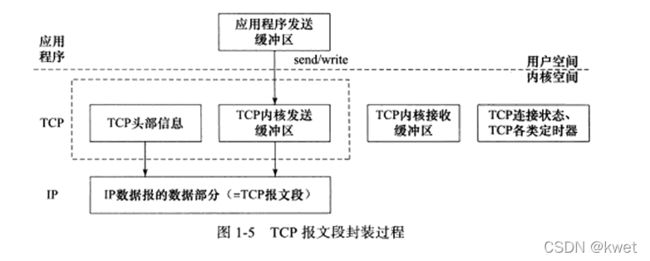 ``
``
应用层的数据放入内核发送缓冲区,然后TCP模块调用IP的服务。这些工作对于用户来说,只用socket中的send()就可以完成
这点可以联系第三章的TCP服务特点
- ARP(通过ip找到MAC地址)
主机向自己所以的网络广播一个ARP请求,请求包含目的机器的网络地址,请求的机器会回应一个ARP应答,包含自己的MAC地址
下面是我自己通过tcpdump抓的
ARP, Request who-has 192.168.129.2 tell 192.168.129.131, length 28
ARP, Reply 192.168.129.2 is-at 00:50:56:fe:26:ee, length 46
- DNS
域名解析,DNA是一套分布式的域名服务系统,存着机器名和IP地址映射,动态更新。
这里可以试一下抓下百度的,然后可以发现,www.a.shifen.com 哈哈哈
tcpdump -i eth33 -nt -s 500 port domain
另一个终端
kwet@kwet-virtual-machine:~$ host -t A www.baidu.com
www.baidu.com is an alias for www.a.shifen.com.
www.a.shifen.com has address 182.61.200.7
www.a.shifen.com has address 182.61.200.6
第二章 ip协议
ip协议的上层TCP协议是可靠连接的,但是ip协议是无状态(数据包之间独立),不可靠(路由丢弃等情况),无连接(不维持双方信息)
IP分片
如果ip数据包超过了MTU(帧的最大数据传输单元)就要切片,切开以后也会添加ip头部信息
sudo tcpdump -ntv -i ens33 icmp
IP (tos 0x0, ttl 64, id 857, offset 0, flags [+], proto ICMP (1), length 1500)
192.168.129.131 > 192.168.129.133: ICMP echo request, id 50989, seq 1, length 1480
IP (tos 0x0, ttl 64, id 857, offset 1480, flags [none], proto ICMP (1), length 21)
192.168.129.131 > 192.168.129.133: ip-proto-1
length 的结果与书上一致
这里应该写ip路由,转发相关。这里就先不写,毕竟先关注的不是这块
第三章TCP协议
必须双方先建立连接才能开始数据的读写,必须是双全工的(双方数据读写可以通过一个连接进行),完成数据交换后,必须断开连接释放资源。
tcp执行写操作将数据放入tcp发送缓冲区中,发送缓冲区数据可能被封装成一个或多个tcp报文段发出。接收端收到tcp报文段后,按照tcp报文段的序号,依次放入tcp接收缓冲区中,然后通知应用程序读取数据,接收端应用程序可以一次性将接收缓冲区的数据读出,也可以分多次读出
没想到读取操作,拷贝了这么多次,在计算机领域肯定有好的解决办法,见第6章
字节流概念:发送写操作和接受读操作没有任何数量关系,数据没有边界
tcp可靠传输,采用应答机制,超时重传(发送端会有一个定时器)。

三次握手,四次挥手
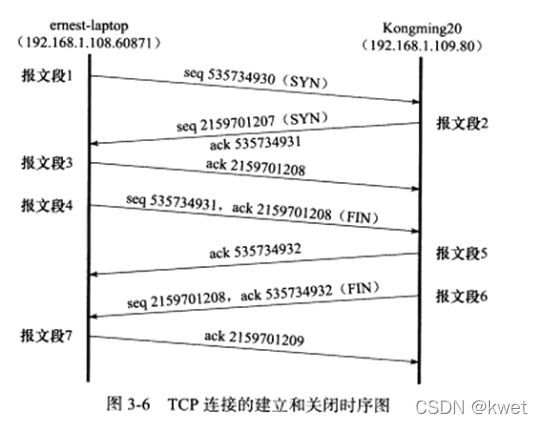
tcpdump观察tcp连接建立关闭
建立
IP 192.168.129.133.54148 > 192.168.129.131.23: Flags [S], seq 4177390328, win 64240, options [mss 1460,sackOK,TS val 3553051023 ecr 0,nop,wscale 7], length 0
IP 192.168.129.131.23 > 192.168.129.133.54148: Flags [S.], seq 3190426506, ack 4177390329, win 65160, options [mss 1460,sackOK,TS val 49740699 ecr 3553051023,nop,wscale 7], length 0
IP 192.168.129.133.54148 > 192.168.129.131.23: Flags [.], ack 1, win 502, options [nop,nop,TS val 3553051024 ecr 49740699], length 0
关闭
192.168.129.133是客户端
我这里显示把报文5和报文6一起发送了,没有书上报文5的内容。报文5的内容就是一个简单的对报文4的ack
IP 192.168.129.133.54148 > 192.168.129.131.23: Flags [F.], seq 147, ack 106, win 502, options [nop,nop,TS val 3553060918 ecr 49740708], length 0
IP 192.168.129.131.23 > 192.168.129.133.54148: Flags [F.], seq 106, ack 148, win 509, options [nop,nop,TS val 49750594 ecr 3553060918], length 0
IP 192.168.129.133.54148 > 192.168.129.131.23: Flags [.], ack 107, win 502, options [nop,nop,TS val 3553060918 ecr 49750594], length 0
半关闭
本端结束了发送,但是可以接收数据。如果本端关闭,对方再去read就会返回0,这样应用程序就知道对方关闭连接
半打开
一端挂了,一端还在保持连接,即使挂了的那端重启,重新连接, 重启的那端会回复 复位报文段,告诉对方关闭连接或者重新连接。
Time_wait状态
这个状态要保持2MSL时间。建议是2min,这个状态处于报文7。
目的:
- 如果报文6丢失,就要让客户端再某个时刻等着,服务器就可以重传报文6,客户端回复报文7 。这样,服务器才可以完全关闭
- 让迟到tcp报文有时间丢弃。如果timewait状态不存在,那么新的连接会使用这个端口,那么有可能接收到旧的tcp报文段(迟到的报文段),这是不行的。因为tcp报文最大生存时间是msl,所以2msl的timewait时间可以让迟到的数据段全部都被路由丢弃
拥塞控制
这里理解一张图,图片来自网络

第四章 TCP/IP通信案例
HTTP请求

这里的回车符换行符表示 \r\n
HTTP应答

简单说一下cookie
cookie是服务器发送给客户端的特殊信息,(响应头部set-cookie),客户端每次向服务器发送请求的时候都要带上这些信息,通过(请求头部cookie)这样服务器就可以区分不同客户
第五章 Linux网络编程API介绍
socket 相关api
//网络通信时,需要将主机字节序转换成网络字节序(大端),
//另外一段获取到数据以后根据情况将网络字节序转换成主机字节序。
// 转换端口
uint16_t htons(uint16_t hostshort); // 主机字节序 -》 网络字节序
uint16_t ntohs(uint16_t netshort); // 主机字节序 《- 网络字节序
// 转IP,一般不用!!
uint32_t htonl(uint32_t hostlong); // 主机字节序 -》 网络字节序
uint32_t ntohl(uint32_t netlong); // 主机字节序 《- 网络字节序
// 一般我们传入的参数ip地址和端口都是字符串形式
atoi(const char *s)//把字符串转成整型,用于端口,ip地址不会使用
//ip地址转成网络字节序
#include 使用socket
#include 读写函数
//普通文件读写
ssize_t write(int fd, const void *buf, size_t count); // 写数据
ssize_t read(int fd, void *buf, size_t count); // 读数据
//socket读写
ssize_t send(int sockfd, const void *buff, size_t nbytes, int flags);
ssize_t recv(int sockfd, void *buff, size_t nbytes, int flags);
//分散读,写
#include 其他
//端口复用
setsockopt()//传入SO_REUSEADDR
//优雅关闭
setsockopt()//传入SO_LINGER
第六章 高级IO函数
文件描述符函数
#include零拷贝
传统的数据读写

读数据过程:
- 应用程序要读取磁盘数据,调用read()函数从而实现用户态切换内核态,这是第1次状态切换;
- DMA控制器将数据从磁盘拷贝到内核缓冲区,这是第1次DMA拷贝;
- CPU将数据从内核缓冲区复制到用户缓冲区,这是第1次CPU拷贝;
- CPU完成拷贝之后,read()函数返回实现内核切换用户态,这是第2次状态切换;
写数据过程:
- 应用程序要向网卡写数据,调用write()函数实现用户态切换内核态,这是第1次切换;
- CPU将用户缓冲区数据拷贝到内核缓冲区,这是第1次CPU拷贝;
- DMA控制器将数据从内核缓冲区复制到socket缓冲区,这是第1次DMA拷贝;
- 完成拷贝之后,write()函数返回实现内核态切换用户态,这是第2次切换
#include 
图片来自小林图解
两个文件描述符之间移动数据
#include 两个管道之间复制数据!这是复制
#include 第七章 服务器程序规范
守护进程

#include 第八章 服务器框架

- I/O处理单元,处理客户端连接,读写网络数据
- 逻辑单元,业务进程或线程
- 网络存储单元,本地数据库,文件或缓冲
- 请求队列,各单元之间的通信方式
I/O处理单元是服务器管理客户端连接的模块,通常的工作:等待并接受新的客户连接,接受客户数据,将服务器响应数据返回给客户端。数据的收发有可能是在逻辑单元中执行。
一个逻辑单元通常是一个进程或线程,分析并处理客户数据,然后将结果传递给I/O处理单元或者直接发送给客户端。一般都是解析客户端发来的请求,并且把资源响应给客户端
网络存储单元可以是数据库、缓冲和文件,甚至是一台独立的服务器,但不是必须的,比如ssh、telnet等登陆服务就不需要这个单元
请求队列是个单元之间的通信方式的抽象,I/O处理单元接收到客户请求时,需要以某种方式通知一个逻辑单元处理该请求。同样,多个逻辑单元同时访问一个存储单元时,也需要采用某种机制来协调处理竞争条件。
I/O模型
-
记住服务器基本都是非阻塞I/O,阻塞的话就白白浪费cpu资源了
非阻塞I/O执行系统调用立即返回,不管时间是否已经发生。如果事件没有立即发生,这些系统调用返回-1,和不错的情况一样,必须根据errno来区分两种情况,对accept、send、recv而言,事件未发生errno通常被设置为EAGAIN(意为“再来一次”)或者EWOULDBLOCK(意为“期望阻塞”);对connect而言,errno被设置成EINPROGRESS(意为“在处理中”)
说人话,就是我们一般要忽略errno为EAGAIN或者EWOULDBLOCK的情况,所以要对read()的返回结果进行判断 -
I/O复用是常用的I/O通知机制,应用程序通过I/O复用函数向内核注册一组事件,内核通过I/O复用函数把其中就绪的事件通知给应用程序。I/O复用函数本身是阻塞的,它具有同时监听多个I/O事件的能力来提高效率。
-
异步IO不讨论
事件处理模式
Reactor
Reactor 模式要求 主线程(I/O 处理单元) 只负责监听文件描述符上是否有事件发生,有的话就立即将该事件通知工作线程(逻辑单元)。除此之外,主线程不做任何其他实质性的工作。 读写数据,接受新的连接,以及处理客户请求均在工作线程中完成。
使用同步 I/O 模型(以 epoll_wait 为例)实现的 Reactor 模式的工作流程是:

主线程往 epoll 内核事件表中注册 socket 上的读就绪事件。
主线程调用 epoll_wait 等待 socket 上有数据可读。
当 socket 上有数据可读时, epoll_wait 通知主线程。主线程则将 socket 可读事件放入请求队列。
睡眠在请求队列上的某个工作线程被唤醒,它从 socket 读取数据,并处理客户请求,然后往 epoll 内核事件表中注册该 socket 上的写就绪事件。
主线程调用 epoll_wait 等待 socket 可写。
当 socket 可写时,epoll_wait 通知主线程。主线程将 socket 可写事件放入请求队列。
睡眠在请求队列上的某个工作进程被唤醒,它往 socket 上写入服务器处理客户请求的结果。
工作线程从请求队列中取出事件后,将根据事件类型来决定如何处理它:对于可读事件,执行读数据和处理请求的操作;对于可写事件,执行写数据的操作。因此,Reactor 模式中没必要区分所谓的 “读工作线程” 和 “写工作线程”。
工作线程去读取和写入socket数据
Procactor
与 Reactor 模式不同,Proactor 模式 将所有 I/O 操作都交给主线程和内核来处理, 工作线程仅仅负责业务逻辑。
使用异步 I/O 模型(以 aio_read 和 aio_write为例)实现的 Proactor 模式的工作流程是:

主线程调用 aio_read 函数向内核注册 socket 上的读完成事件,并告诉内核用户读缓冲区的位置,以及读操作完成时如何通知应用程序(这里以信号为例)
主线程继续处理其他逻辑。
当 socket 上的数据被读入用户缓冲区后,内核将向应用程序发送一个信号,以 通知应用程序数据已经可用。
应用程序预先定义好的信号处理函数选择一个工作线程来处理客户请求。工作线程处理完客户请求之后,调用 aio_write 函数向内核注册 socket 上的写完成事件,并告诉内核用户写缓冲区的位置,以及写
操作完成时如何通知应用程序(仍然以信号为例)
主线程继续处理其他逻辑
当用户缓冲区的数据被写入 socket 之后,内核将向应用程序发送一个信号,以通知应用程序数据已经发送完毕。
应用程序预先定义好的信号处理函数选择一个工作线程来做善后处理,比如决定是否关闭 socket。
连接 socket 上的读写事件是通过 aio_read/aio_write 向内核注册的,因此内核将通过信号来向应用程序报告连接 socket 上的读写事件。所以,主线程中的 epoll_wait 调用仅能用来检测监听 socket 上的连接请求事件,而不能用来检测 socket 上的读写事件。
sokcet的数据读写是由内核去完成
模拟Procactor
使用同步I/O方式模拟出Proactor模式的原理是:主线程执行数据读写操作,读写完成之后,主线程向工作线程通知这一“完成事件”。那么从工作线程的角度来看,它们就直接获得了数据读写的结果,接下来要做的只是对读写的结果进行逻辑处理。
使用同步I/O模型(仍以epoll_wait为例)模拟出Proactor模式的工作流程如下:
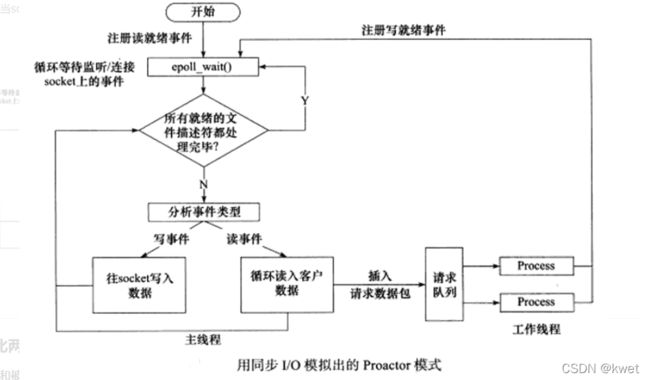
主线程往epoll内核事件表中注册socket上的读就绪事件。
主线程调用epoll_wait等待socket上有数据可读。
当socket上有数据可读时,epoll_wait 通知主线程。主线程从socket循环读取数据,直到没有更多数据可读,然后将读取到的数据封装成一个请求对象并插入请求队列。
睡眠在请求队列上的某个工作线程被唤醒,它获得请求对象并处理客户请求,然后往epoll内核事件表中注册socket上的写就绪事件。
当socket可写时,epoll_wait通知主线程。主线程往socket上写入服务器处理客户请求的结果。
简单来说,就是主线程来对socket读写,工作线程只负责业务处理
一般都是Reactor模式和模拟Procactor模式
两种并发模式
1.半同步半异步模式
半同步半异步模式的变体——半同步半反应堆模式采用的事件处理模式是Reactor
2.领导者/追随者模式
多个线程轮流获得事件资源集合,轮流监听IO事件,分发并处理事件
有限状态机
应用在解析http请求
while(case!=c)
{
case a:
fun();
case=b;//转化状态
break;
case b:
fun();
case=c;//转换状态
break;
}
第九章 IO复用
IO复用作用是监听多个文件描述符
select
只能LT,O(n)复杂度
poll
只能LT,O(n)复杂度
epoll
LT和ET都可以,O(1)复杂度
- LT水平触发
socket里有数据的话,epoll_wait会触发多次 - ET边沿触发
只会触发一次,所以每次read的时候要利用while去完
while(1){
int ret=read();
if(ret<0)
{
if(errno==EAGAIN)
{
printf("读完了/n");
break;
}
close();
break;
}else if(ret==0){
clsoe();
}else{
printf("读到了");
}
}
EPOLLONESHOT事件
epoll模式中事件可能被触发多次,比如socket接收到数据交给一个线程处理数据,在数据没有处理完之前又有新数据达到触发了事件,另一个线程被激活获得该socket,从而产生多个线程操作同一socket,即使在ET模式下也有可能出现这种情况。采用EPOLLONETSHOT事件的文件描述符上的注册事件只触发一次,要想重新注册事件则需要调用epoll_ctl重置文件描述符上的事件,这样前面的socket就不会出现竞态。
只能对连接文件描述符注册EPOLLONESHOT,如果对监听文件描述符设置EPOLLONESHOT事件,那么应用程序只能处理一个客户端连接,因为后续的连接请求不会触发EPOLLIN事件
第十章 信号
SIGPIPE
当一个管道读的一段关闭了或者socke连接一端已经关闭,再写数据,就会触发SIGPIPE信号。
该信号的缺省学位是终止进程,因此进程必须忽略或者捕获它,以免被终止。并且可以通过erro等于epipe的返回知道连接关闭