【征服redis14】认真理解一致性Hash与Redis的三种集群
前面我们介绍了主从复制的方式和sentinel方式,这里我们看第三种模式-Cluster方式。
目录
1.前两种集群模式的特征与不足
2.Cluster模式
2.1 Cluster模式原理
2.2 数据分片与槽位
2.3 Cluster模式配置和实现
3.一致性Hash
3.1 哈希后取模
3.2 一致性Hash算法
4 Redis Cluster集群
1.前两种集群模式的特征与不足
主从复制是Redis的一种基本集群模式,它通过将一个Redis节点(主节点)的数据复制到一个或多个其他Redis节点(从节点)来实现数据的冗余和备份。主节点负责处理客户端的写操作,同时从节点会实时同步主节点的数据。客户端可以从从节点读取数据,实现读写分离,提高系统性能。
主从复制模式适用于以下场景:
- 数据备份和容灾恢复:通过从节点备份主节点的数据,实现数据冗余。
- 读写分离:将读操作分发到从节点,减轻主节点压力,提高系统性能。
- 在线升级和扩展:在不影响主节点的情况下,通过增加从节点来扩展系统的读取能力。
由此可见,主从复制模式适合数据备份、读写分离和在线升级等场景,但在主节点故障时需要手动切换,不能自动实现故障转移。如果对高可用性要求较高,可以考虑使用哨兵模式或Cluster模式。
哨兵模式是在主从复制基础上加入了哨兵节点,实现了自动故障转移。哨兵节点是一种特殊的Redis节点,它会监控主节点和从节点的运行状态。当主节点发生故障时,哨兵节点会自动从从节点中选举出一个新的主节点,并通知其他从节点和客户端,实现故障转移。
此时的系统结构如下所示,也就说哨兵模式可以增强主备模式的功能,:
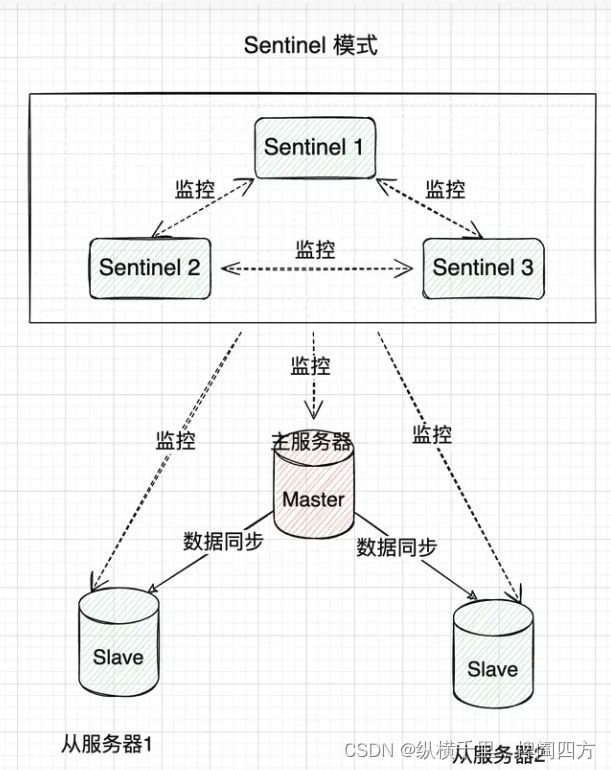
哨兵模式适用于以下场景:
- 高可用性要求较高的场景:通过自动故障转移,确保服务的持续可用。
- 数据备份和容灾恢复:在主从复制的基础上,提供自动故障转移功能。
由此可见,哨兵模式在主从复制模式的基础上实现了自动故障转移,提高了系统的高可用性。然而,它仍然无法实现数据分片。如果需要实现数据分片和负载均衡,可以考虑使用Cluster模式。
2.Cluster模式
2.1 Cluster模式原理
Cluster模式是Redis的一种高级集群模式,它通过数据分片和分布式存储实现了负载均衡和高可用性。在Cluster模式下,Redis将所有的键值对数据分散在多个节点上。每个节点负责一部分数据,称为槽位。通过对数据的分片,Cluster模式可以突破单节点的内存限制,实现更大规模的数据存储。

这里,有个问题,如果我们来了多个请求怎么判断该发送到哪个机器呢?这就是数据分片与槽位的问题。
2.2 数据分片与槽位
这里我们先说结论,后面再解释。
Redis Cluster将数据分为16384个槽位,每个节点负责管理一部分槽位。当客户端向Redis Cluster发送请求时,Cluster会根据键的哈希值将请求路由到相应的节点。具体来说,Redis Cluster使用CRC16算法计算键的哈希值,然后对16384取模,得到槽位编号。
2.3 Cluster模式配置和实现
配置Redis节点:为每个节点创建一个redis.conf配置文件,并添加如下配置:
# cluster节点端口号
port 7001
# 开启集群模式
cluster-enabled yes
# 节点超时时间
cluster-node-timeout 15000像这样的配置,一共需要创建6个,我们做一个三主三从的集群。
启动Redis节点:使用如下命令启动6个节点:
redis-server redis_7001.conf创建Redis Cluster:使用Redis命令行工具执行如下命令创建Cluster:
redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1cluster-replicas 表示从节点的数量,1代表每个主节点都有一个从节点。
验证Cluster模式:向Cluster发送请求,观察请求是否正确路由到相应的节点。
这样我们就搭建了一个基本的Cluster集群了。
通过上面的方式,可以看到,这种方式需要客户端自己来配置所有的机器,有些复杂,一些复杂的操作可能也会受到限制,但是这种方式配置明确,在中等类型的互联网公司这么做都是可以的。
以下内容摘自咕泡青山老师的课堂讲义。
3.一致性Hash
如果客户端去连接redis服务器的时候会有个问题,此时客户端该如何选择呢?也就是该如何进行分库分表的分片策略呢?另外就是这段逻辑该由谁来做呢?
如下图所示:
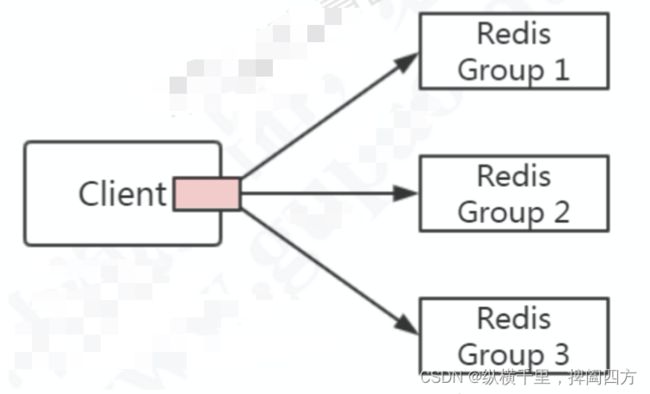
关于分片,我们可以有三种方案:
- 第一种,是在客户端实现相关的逻辑,如用取模或者一致性哈希对key进行分片,查询和修改都先判断key的路由。
- 第二章,是把做分片处理的逻辑抽取出来,运行在一个独立的代理服务器上,客户端连接到这个dialing服务,然后再转发。
- 第三种就是服务端只有一个统一的对外接口,服务器之间自己实现分片策略。
第二种就是花钱消灾的方式,我们重点讨论另外两种。
以下内容摘自青山老师的讲义,内容挺好,怀念一下青山老师。
我们前面介绍的客户端Jedis客户端中,支持分片功能,它是SpringBoot2版本之前默认的Redis客户端,RedisTempate就是对Jedis的封装。
Jedis有多种连接池,其中一种是支持分片的。代码示例如下:
public static void main(String[] args) {
JedisPoolConfig poolConfig = new JedisPoolConfig();
JedisShardInfo shardInfo1 = new JedisShardInfo("127.0.0.1", 6379);
JedisShardInfo shardInfo2 = new JedisShardInfo("127.0.0.1", 6389);
List infoList = Arrays.asList(shardInfo1, shardInfo2);
ShardedJedisPool shardedJedisPool = new ShardedJedisPool(poolConfig, infoList);
ShardedJedis jedis = null;
try {
jedis = shardedJedisPool.getResource();
for (int i = 0; i < 100; i++) {
jedis.set("shard" + i, i + "");
}
for (int i = 0; i < 100; i++) {
System.out.println(jedis.get("shard" + i));
}
} catch (Exception exception) {
System.out.println(exception);
if (jedis != null) {
jedis.close();
}
}
} 通过dbsize命令发自按,一个机器有44个key,一台机器有56个,大致是一半一半。
3.1 哈希后取模
ShardJedis是怎么做到的呢?如果是希望数据分布相对均匀的话,我们首先可以考虑哈希后取模。之所以先Hash,是因为key不一定是整数,可能是字符串或者其他信息,同时为了使数据分布更均匀,所以先计算哈希比较好。
例如,hash(key)%N,根据余数,决定映射到哪个结点。这种方式比较简单,属于静态分片的方式,缺点也很明显,一旦节点发生数量变化,或者某个hash被换了,此时取模N就会发生变化,数据就要重新分布。为了解决这个问题,我们又有了一致性Hash算法。ShardedJedis实际上使用的就是一致性哈希算法。
3.2 一致性Hash算法
一致性哈希的基本原理是:把所有的哈希值空间组织成一个虚拟的圆环(哈希环),整个空间按照顺时针方向组织,其中0和最高位2^32-1是重叠的。
假设我们有四台机器要哈希环来实现映射(分布数据),我们先根据机器的名称或者ip计算哈希值,然后分布到环中,也就是图中红色标记。
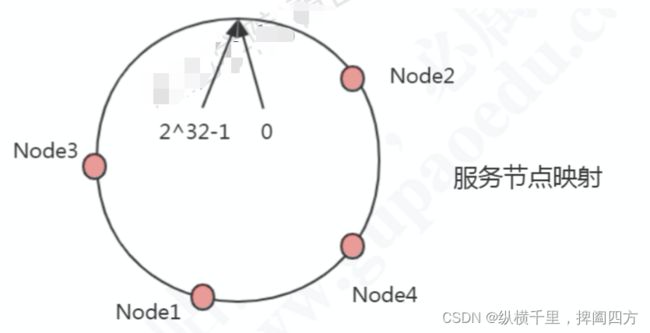
现在有4条数据或者4个访问请求,对key计算后,得到哈希环中的位置(绿色位置)。沿哈希环顺时针找到的一个Node,就是数据存储的结点。
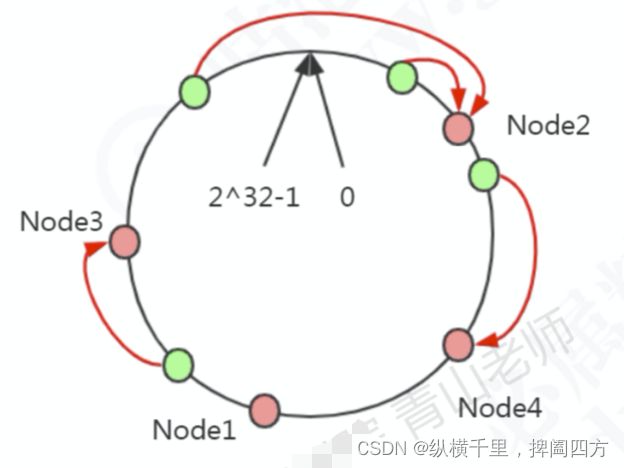
在这种情况下,新增一个Node5结点 ,只影响一部分数据的分布,如下:

如果我们删除一个结点Node4,只影响相邻的一个结点。
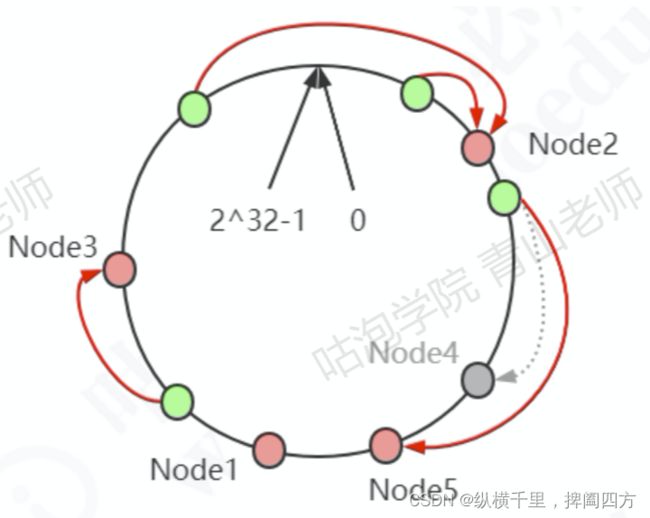
一致性哈希解决了动态增减结点时,所有数据都需要重新分布的问题,它只会影响到下一个相邻的结点,对其他结点没有影响。
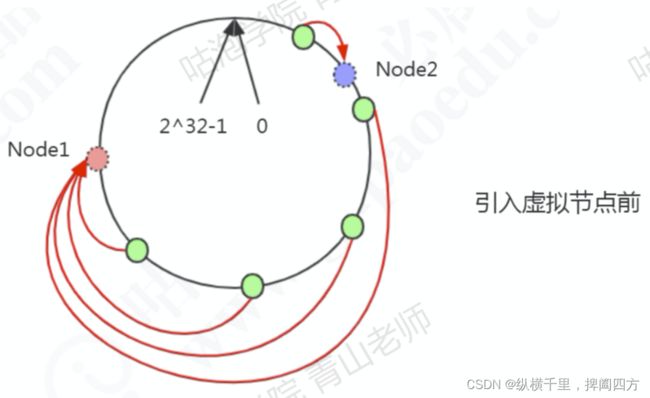
但是这样的一致性哈希有一个缺点,因为结点不一定是均匀分布的,特别是在节点数比较少的情况下,所以数据不能得到均匀分布。解决这个问题的办法是引入虚拟结点
比如,2个节点,5条数据 ,只有1条分布到Node2,4条分布到Node1,不均匀。
Node1设置了两个虚拟结点,Node2也设置了两个两个虚拟结点(虚线圆圈),这时候有3条数据分不到Node1,1条分布到Node2.
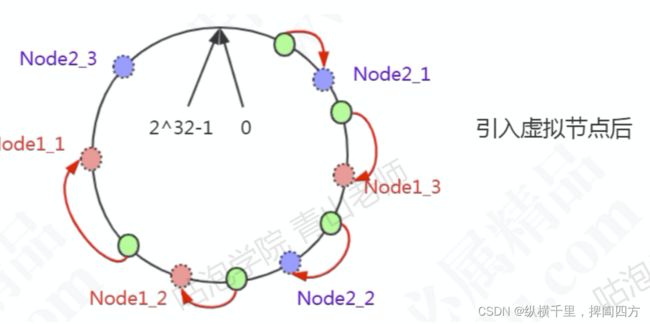
一致性Hash在分布式系统中很多场景都有应用,例如负载均衡、分库分表等等,是一个非常重要的基础算法。
4 Redis Cluster集群
Redis Cluster也是用来解决分布式的需求,同时也可以实现高可用。在CLuster中,各个结点是去中心化的,客户端可以连接到任一个节点上。
对于这种方式 ,我们有几个问题需要思考,例如:
- 数据怎么相对均匀的分布地分片
- 客户端怎么访问到相应的结点和数据
- 重新分片的过程,怎么保证正常服务。
我们来讨论一下。对于一个Redis Cluster 集群,例如一个三主三从的结构,节点之间两两交互,共享数据分片、节点状态等信息。此时的结构是这样的:

Redis没有使用哈希取模,也没有用一致性哈希,而是用虚拟槽来实现的。Redis创建了16384个槽,每个节点负责一定区间的slot,比如Node1负责0~5460,Node1负责5461~10922,Node3负责10923~~16383。

对象分不到Redis节点上时,对key采用crc16算法计算再与16384取模,得到一个slot的值,数据落到负责这个slot的redis节点上。
Redis的每个master节点都会维护自己负责的slot。用一个bit序列实现,例如,序列的第0位是1,就代表第一个slot是它负责,序列的第1位是0,代表第二个slot不归它负责。
在这里key与slot的关系是永远不会变的,变的只有slot和redis节点的关系。
问题:客户端该连接到某一台服务器,但是访问的数据不在该节点上怎么办?
这时候redis采取了一个非常简单,但是比较笨的方式:根据新的规则算出数据迁移到里了,然后将地址返回给客户端,让客户端重新去对应的机器上连。
也就是这种情况下,客户端需要连接两次。不过Jedis等客户端一般会在本地维护一份slot-node的关系,一般是不需要重定向的。
以上内容大部分参考自青山老师的讲义,在此表示感谢。