从内核的视角观测容器——SysOM 容器监控
作者:龙蜥系统运维SIG
背景
容器化现阶段已经是构建企业 IT 架构的最佳实践。云原生容器化的部署架构,相较于传统 IDC 部署架构的 IT 架构方案,已经成为兼具高效运维及成本控制的业界事实标准。
但容器化带来的都是好处么?容器化屏蔽了 IDC 基础设施和云资源的同时,也带来了容器引擎层的不透明,现有的云原生可观测体系还无法覆盖。据我们统计,大量超过千节点规模的生产级 JAVA on K8s 的用户都遇到过内存“黑洞”导致的 OOM 问题,以及大规模集群使用上的容器引擎层 CGroup 问题也会使得用户对容器化望而却步。
阿里云容器服务 ACK 团队与阿里云操作系统团队进行合作,通过对多个头部行业客户的千万核规模的 Kubernetes 集群沉淀了丰富的容器化迁移专业经验,以及结合 Alinux 对操作系统 kernel 层的专业增强,通过与云原生容器服务结合,使容器引擎层不再“黑盒”,让用户放心容器化。
常见容器化内存“黑洞问题”
容器内存组成剖析
Kubernetes 采用内存工作集(workingset)来监控和管理容器的内存使用,当容器内存使用量超过了设置的内存限制或者节点出现内存压力时,Kubernetes 会根据 workingset 来决定是否驱逐或者杀死容器。
内存工作集计算公式:
Workingset = inactive_anon + active_anon + active_file。其中 inactive_anon 和 active_anon 是程序匿名内存总大小。active_file 是活跃文件缓存大小。
匿名内存
匿名内存是指没有关联到文件的内存,例如进程的堆、栈、数据段等,有以下几种部分组成:
匿名映射: 程序通过 mmap 系统调用创建的没有关联文件的内存映射。
堆: 程序通过 malloc/new 或 brk 系统调用分配的动态内存。
栈: 用于存储函数参数和局部变量的内存。
数据段: 用于存储已初始化和未初始化的全局变量和静态变量的内存。
活跃文件缓存
程序读写文件会产生文件缓存(file cache),其中最近多次使用的缓存称为 active file cache,通常不 容易被系统回收。

(图/Kernel Level Memory Distribution)
下面介绍通过 SysOM 监控来排查 Pod workingset 高的问题。
定位步骤一:定位哪些内存导致 workingSet 高
根据 workingset 计算公式:workingset = inactive_anon + active_anon + active_file 查看 PodMonitor 监控大盘中的 woringkset 监控,找到内存最大的类型,这里发现是 active file cache 占比较大。

(图/SysOM 监控提供 Pod 维度的操作系统内核层内存各组成成分监控)
发现问题步骤中,SysOM 提供通过 Top 分析快速定位集群中 active file cache 内存消耗最大的 Pod。
通过 Pod Cache (缓存内存)、InactiveFile(非活跃文件内存占用)、InactiveAnon(非活跃匿名内存占用)、Dirty Memory(系统脏内存占用)等不同内存成分的问题的监控展示,发现常见的 Pod 内存黑洞问题。

(图/通过 Top 分析找出集群中 active file cache 内存消耗最大的 Pod)
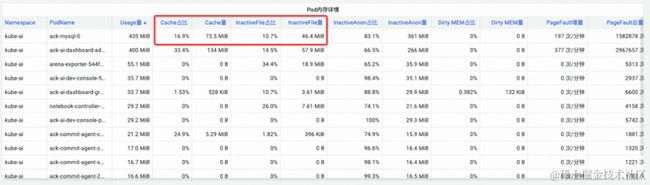
(图/SysOM 提供 Pod 维度的详细内存各组成成分监控统计)
定位步骤二:定位具体哪些文件导致 active file cache 高
查看 PodMonitor 监控大盘中的 file cache 监控,发现主要是 ack-ai-dashboard-admin-ui-77564df84c-z6bs2 容器在对 /workspace/ai-dashboard.jar 文件进行 IO 读写时,产生了较大的内存 Cache 缓存。

若 Pod 内存缓存较大,严重会导致 Pod 工作内存占用升高,这部分 Cache 内存会成为 Pod 工作内存的“黑洞”部分难以定为,产生线上常见的 Pod 内存黑洞导致的 OOM 驱逐问题,最终影响 Pod 所在的业务体验。
ACK 提供容器化内核层问题的完整解决方案
发现问题 - SysOM 系统容器监控
基于阿里云 SysOM,阿里云容器服务 ACK 拥有独有的操作系统 kernel 层的容器监控可观测能力。在客户容器化迁移中,社区、其他云厂商的容器服务没有很好地解决的内存黑洞、存储黑洞等问题,基于阿里云 SysOM 可以很好的观测、预警、诊断出问题。
SysOM 提供操作系统内核层 Pod、Node 维度监控大盘,实时监控内存、网络、存储的系统层指标。

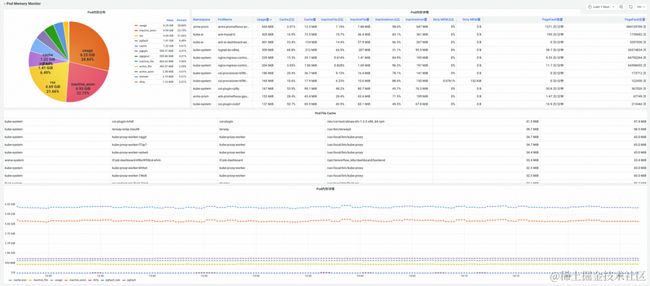
(图/SysOM Pod 维度监控大盘)

(图/SysOM Node 维度监控大盘)
SysOM 功能、指标详细请参考文档:https://help.aliyun.com/document_detail/2560259.html
解决问题 - Koordinator QoS精细化调度功能
内存黑洞问题如何修复,阿里云容器服务通过精细化调度功能,依托 Koordinator 阿里云开源项目,ack-koordinator 为容器提供内存服务质量 QoS(Quality of Service)保障能力,在确保内存资源公平性的前提下,改善应用在运行时的内存性能。本文简介容器内存 QoS 功能,具体说明请参见容器内存 QoS [ 1] 。
容器在使用内存时主要有以下两个方面的约束:
- 自身内存限制:当容器自身的内存(含Page Cache)接近容器上限时,会触发容器维度的内存回收,这个过程会影响容器内应用的内存申请和释放的性能。若内存申请得不到满足则会触发容器 OOM。
- 节点内存限制:当容器内存超卖(Memory Limit>Request)导致整机内存不足,会触发节点维度的全局内存回收,这个过程对性能影响较大,极端情况甚至导致整机异常。若回收不足则会挑选容器 OOM Kill。
针对上述典型的容器内存问题,ack-koordinator 提供了以下增强特性:
- 容器内存后台回收水位:当 Pod 内存使用接近 Limit 限制时,优先在后台异步回收一部分内存,缓解直接内存回收带来的性能影响。
- 容器内存锁定回收/限流水位:Pod 之间实施更公平的内存回收,整机内存资源不足时,优先从内存超用(Memory Usage>Request)的 Pod 中回收内存,避免个别Pod造成整机内存资源质量下降。
- 整体内存回收的差异化保障:在 BestEffort 内存超卖场景下,优先保障 Guaranteed/Burstable Pod 的内存运行质量。
关于 ACK 容器内存 QoS 启用的内核能力,详见 Alibaba Cloud Linux 的内核功能与接口概述 [ 2] 。

(图/ack-koordinator 为容器提供内存服务质量 QoS(Quality of Service)保障能力)
在通过第一步观测发现容器内存黑洞问题之后,可以结合通过 ACK 精细化调度功能针对性挑选内存敏感的 Pod 启用容器内存 QoS 功能,完成闭环修复。
相关链接:
[1] 容器内存链接
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/memory-qos-for-containers
[2] Alibaba Cloud Linux的内核功能与接口概述
https://help.aliyun.com/zh/ecs/user-guide/overview-23