TaskExecutor统一内存配置(FLink FLIP-49翻译)
文章目录
- 目的:
-
- (1)解决流、批配置差异大
- (2)解决Streaming方式RocksDB配置复杂
- (3)去掉复杂、不确定、难以理解的配置
- 公共接口
- 修改建议
-
- 统一流处理和批处理内存管理
- 内存使用场景及特点
- 统一显式和隐式内存申请
- 将托管的堆上内存池和堆外内存池分离
- Memory Pools和配置方式
-
- 框架堆内存(Framework Heap Memory)
- 用户堆内存(Task Heap Memory)
- 用户堆外内存(Task Off-Heap Memory)
- shuffle 内存(shuffle memory)
- 托管内存(Managed Memory)
- JVM元数据(JVM Metaspace)
- JVM的开销(JVM Overhead)
- 总Flink内存(Total Flink Memory)
- 总进程内存(Total Process Memory)
- JVM参数
-
- JVM堆内存
- JVM直接内存
- JVM metaspace
- 内存计算
- 计算逻辑
- 实施步骤
-
- 步骤1、引入一个开关,来启用新的TaskExecutor内存配置
- 步骤2、实现内存计算逻辑
- 步骤3、使用新的内存计算逻辑启动TaskExecutor
- 步骤4、独立堆上和堆外托管内存池
- 第5步、将本机内存用于托管内存
- 步骤6、清理遗留模式
- 测试计划
- 限制
- 后续
-
- 替代方案
目的:
该提案目的是解决Flink 1.9 TaskExecutor内存配置的几个缺点。
(1)解决流、批配置差异大
目前,流和批作业TaskExecutor内存的配置各不相同。
- Streaming(流处理)
- 内存是隐式消耗的,要么在堆上由Memory State Backend后端消耗,要么在堆外由RocksDB消耗。
- 用户必须手动调整堆大小和手动选择后端(state backend)。
- 用户必须手动配置RocksDB,以使用足够的内存来实现良好的性能,但又不能超出预算。
- 内存消耗无法预测,包括on-heap(堆内)的memory后端,以及off-heap(堆外)的RocksDB后端
- Batch(批处理)
- 用户手动配置总内存大小,以及在Operator(算子)中使用堆上内存还是堆外内存。
- Flink将总内存的一部分保留为managed memory托管内存。它自动调整heap大小和“max direct memory”参数,以适应堆内、堆外内存的管理。
- Flink为Operators申请托管的Memory Segments。并保证不会超过剩余的Memory Segments(内存段)。
(2)解决Streaming方式RocksDB配置复杂
- 用户必须手动减少JVM堆大小,或者将Flink设置为使用堆外内存。
- 用户必须手动配置RocksDB内存。
- 用户无法尽可能多地使用可用内存,因为RocksDB内存大小必须配置得足够低,以确保不会超出内存预算。
(3)去掉复杂、不确定、难以理解的配置
- 在配置container、进程的内存大小时,有一些“magic魔法”。其中一些是不容易推理的,例如yarn container“保留的内存”。
- 配置一个像RocksDB这样的堆外状态后端意味着要么将托管内存设置为堆外,要么调整截止比,从而减少为JVM堆提供的内存。
- TaskExecutor依赖于瞬时的JVM内存使用来确定不同内存池的大小,首先触发GC,然后获得JVM空闲内存大小,这给不同内存池的大小带来了不确定性。
公共接口
TaskExecutor内存配置选项。以及向后兼容性
修改建议
统一流处理和批处理内存管理
基本思想是将状态后端使用的内存视为托管内存的一部分,并扩展MemoryManager(内存管理器),以便状态后端可以简单地从MemoryManager那里保留一定量的内存,但并不是必须从MemoryManager那里分配内存。
通过这种方式,用户能够不修改集群配置的情况下,切换流作业和批作业。
内存使用场景及特点
- 使用Memory/FsStateBackend的流作业(特点):
- JVM堆内存
- 由状态后端隐式申请内存
- 对整体的内存消耗没有控制
- 使用RocksDBStateBackend的流作业(特点):
- 堆外内存
- 由状态后端隐式申请内存
- 不能超过初始化期间配置的总内存大小
- 批处理作业(特点):
- 堆内存
- 从内存管理器显式分配
- 不能超过从内存管理器分配的总内存
统一显式和隐式内存申请
- Memory Consumer可以通过两种方式获取内存
- 以MemorySegment的形式,显式地从MemoryManager中获取。
- 从MemoryManager中预先保留,再使用,在这种情况下应该返回“使用最多X个字节”,并由Memory Consumer自己隐式地申请内存。
将托管的堆上内存池和堆外内存池分离
当前(Flink 1.9),所有托管内存都以相同的类型分配,不管是在堆上还是堆外。这对于当前用例来说是很好的,在当前用例中,我们不需要在同一TaskExecutor中同时使用堆上和堆外托管内存。
在这次建议的设计中,state backend(状态后端)使用的内存也被认为是托管内存,这意味着在相同集群中的作业可能需要不同类型的托管内存。例如,一个流作业使用memorystateback和另一个流作业使用rocksdbstateback。
因此,我们将托管内存池分为on-heap-pool和off-heap-pool。我们使用一个off-heap比例来决定管理内存的哪些部分应该进入off-heap-pool,而将其余部分留给on-heap-pool。用户仍然可以通过将堆外比例设置为0 / 1来将集群配置为使用所有的堆上/堆外托管内存。
Memory Pools和配置方式

框架堆内存(Framework Heap Memory)
- Flink TaskManager使用的堆上内存。它不属于slot资源配置文件。
(taskmanager.memory.framework.heap)
(默认128mb)
用户堆内存(Task Heap Memory)
用户代码使用的堆内存。
(taskmanager.memory.task.heap)
用户堆外内存(Task Off-Heap Memory)
用户代码使用的堆外内存。
(taskmanager.memory.task.offheap)
(默认0 b)
shuffle 内存(shuffle memory)
用于shuffle的堆外内存。
(taskmanager.memory.shuffle。[最小/最大/部分)
(默认最小为64mb,最大为1gb,比例为0.1)
托管内存(Managed Memory)
分为On-heap和Off-heap Flink托管内存。
-
配置项:
(taskmanager.memory.managed.[size|fraction])。
(taskmanager.memory.managed.offheap-fraction)
(默认fraction=0.5, offheap-fraction=0.0) -
计算方式:
On-Heap Managed Memory = Managed Memory * (1 - offheap-fraction)
Off-Heap Managed Memory = Managed Memory * offheap-fraction
JVM元数据(JVM Metaspace)
堆外内存,归JVM元数据使用。
(taskmanager.memory.jvm-metaspace)
(默认192 mb)
JVM的开销(JVM Overhead)
堆外内存,用于线程堆栈空间、I/O直接内存、编译缓存等。
(taskmanager.memory.jvm-overhead.[min/max/fraction])
(默认最小为128mb,最大为1gb,比例为0.1)
总Flink内存(Total Flink Memory)
-
总Flink Memory配置项,属于粗粒度,使用户更容易配置。
它包括上述Framework Heap Memory, Task Heap Memory, Task Off-Heap Memory, Shuffle Memory, and Managed Memory。
但不包括JVM Metaspace和JVM Overhead。 -
配置项:(taskmanager.memory.total-flink.size)
总进程内存(Total Process Memory)
-
总Process Memory配置项,属于粗粒度,使用户更容易配置。
它包括上述Total Flink Memory, and JVM Metaspace and JVM Overhead。 -
配置项:(taskmanager.memory.total-process.size)
JVM参数
JVM堆内存
包括 Framework Heap Memory, Task Heap Memory, and On-Heap Managed Memory
显式地将-Xmx和-Xms设置为这个值
JVM直接内存
包括任务堆外内存和随机内存(Task Off-heap Memory和Shuffle Memory)
显式地将-XX:MaxDirectMemorySize设置为这个值
对于非堆托管内存,我们总是使用Unsafe.allocateMemory()来申请内存,这个动作不受此参数的限制。
JVM metaspace
将-XX:MaxMetaspaceSize设置为已配置的JVM元数据空间
内存计算
-
所有内存/池大小的计算都在TaskExecutor JVM启动之前。一旦启动了JVM,就不需要在Flink TaskExecutor中进一步的计算和派生。
-
计算应该只在两个地方执行。
- standalone模式:在启动shell脚本时。
- yarn/mesos/k8s:在ResourceMananger端(资源管理器端)。
-
启动脚本时,实际上可以调用Flink runtime java代码来执行计算逻辑。通过这种方式,我们可以确保standalone集群和其他模式集群具有一致的内存计算逻辑。
-
计算出的内存/池大小,作为动态配置(通过’-D’)传递给TaskExecutor。
计算逻辑
我们需要配置这三个选项中的一个:
- 任务堆内存和托管内存(Task Heap Memory and Managed Memory)
- 总Flink内存(Total Flink Memory)
- 总进程内存(Total Process Memory)
下面逻辑描述了如何从一个值计算出其余值:
-
如果同时配置了Task Heap Memory(任务堆内存)和Managed Memory(托管内存),则使用它们派生总Flink内存
- 如果shuffle内存是显式配置的,我们使用该值
- 否则,我们计算它,使它构成最终总Flink内存的配置分数(见getAbsoluteOrInverseFraction())
-
如果配置的是总Flink内存(Process Memory),而不是任务堆内存(Task Heap Memory)和托管内存(Managed Memory),那么我们将派生出shuffle内存和托管内存(Managed Memory),并将其余内存(不包括框架堆内存Framework Heap Memory和任务堆外内存Task Off-Heap Memory)作为任务堆内存(Task Off-Heap Memory)。
- 如果shuffle内存是显式配置的,我们使用该值
- 否则,我们计算它,通过Total Flink Momory乘以比例(见getAbsoluteOrFraction())
- 如果托管内存(Managed Memory )是显式配置的,则使用该值
- 否则,我们计算它,通过Total Flink Momory乘以比例(见getAbsoluteOrFraction())
-
如果只配置了总进程内存(Total Process Memory),那么我们将通过以下方式获得总Flink Memory
- 我们得到(或计算相对)并从整个进程内存中减去JVM开销(参见getAbsoluteOrFraction())
- 剩下的部分减去JVM Metaspace
- 我们将其余部分作为总Flink Momory
接口代码定义:
def getAbsoluteOrFraction(key: ConfigOption, base: Long): Long = {
conf.getOrElse(key) {
val (min, max, fraction) = getRange(conf, key)
val relative = fraction * base
Math.max(min, Math.min(relative, max))
}
}
def getAbsoluteOrInverseFraction(key: ConfigOption, base: Long): Long = {
conf.getOrElse(key) {
val (min, max, fraction) = getRange(conf, key)
val relative = fraction / (1 - fraction) * base
Math.max(min, Math.min(relative, max))
}
}
实施步骤
步骤1、引入一个开关,来启用新的TaskExecutor内存配置
引入临时配置选项,作为当前/新TaskExecutor内存配置切换(代码中)。这允许我们在不影响现有代码行为的情况下,实现和测试新的代码路径。
步骤2、实现内存计算逻辑
- 引入新的配置选项
- 引入新的数据结构和逻辑:
- 用于存储TaskExecutor的内存/池大小的数据结构
- 用于从配置中,计算内存/池大小的逻辑
- 用于生成动态配置的逻辑
- 用于生成JVM参数的逻辑
此步骤不应引入任何行为更改。
步骤3、使用新的内存计算逻辑启动TaskExecutor
- 调用第2步中引入的数据结构和实用程序,生成用于启动新任务执行器的JVM参数和动态配置。
- 在启动脚本(standalone模式)
- 在资源管理器(yarn、mesos、k8s)
- Task executor使用第2步中引入的数据结构和实用程序来设置内存池大小和槽资源配置文件。
- MemoryManager
- ShuffleEnvironment
- TaskSlotTable
使用独立的代码路径,实现上述步骤(仅用于新Mode)
步骤4、独立堆上和堆外托管内存池
- 更新MemoryManager,使其拥有两个独立的池。
- 扩展MemoryManager接口,以指定从哪个池分配内存。
在遗留/新模式的公共代码路径中实现此步骤。
- 对于遗留模式,根据配置的内存类型,我们可以将两个池中的一个,设置为托管内存总大小,并始终从这个池进行分配,让另一个池为空
第5步、将本机内存用于托管内存
- 使用Unsafe.allocateMemory来申请内存
- MemoryManager
在遗留/新模式的公共代码路径中实现这个issue。这只会影响GC行为。
- MemoryManager
步骤6、清理遗留模式
- 修复/更新/删除遗留模式的测试用例
- 弃用/删除遗留的配置选项
- 删除遗留代码路径
- 移除旧模式/新模式的开关
兼容性、弃用和迁移计划
本FLIP改变了用户配置集群资源的方式,在某些情况下,如果从以前的版本迁移过来,可能需要重新配置集群。
不推荐(Deprecated )的配置键如下:
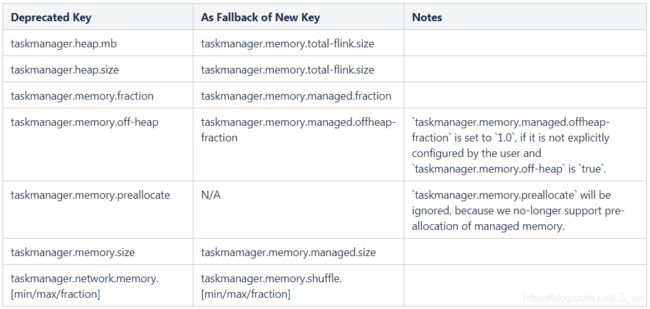
测试计划
- 我们需要更新现有的集成测试,并添加新的集成测试,以验证新的内存配置,行为是否正确。
- 如果当前集成测试失败了,其他常规集成和端到端测试也会失败。
限制
- 建议的设计使用Unsafe.allocateMemory()来分配托管内存,这不再支持Java 12。我们需要在未来寻找替代的解决方案。
后续
- 当前FLIP需要非常详细的文档,来帮助用户理解如何正确配置Flink进程,以及在何种情况下应该使用哪些Key。
- 最好在web UI中,显示配置的内存池大小,这样用户就可以立即看到TMs使用了多少内存。
替代方案
关于JVM直接内存,我们有以下替代方案:
1、让GC释放MemorySegments,并通过设置适当的JVM最大直接内存大小参数来触发GC。
2、让GC释放MemorySegments,通过记录JVM最大直接内存的使用量,触发GC。
3、手动分配和释放MemorySegments。
我们决定使用3,但取决于Segment故障的安全程度,我们可以很容易地在实现后切换到其他替代方案。