LLMs之ChatGLM3:ChatGLM3/ChatGLM3-6B的简介—“对话格式”功能介绍(推理系统如何解析参数/采用Python代码形式/编写工具调用的代码/Manual Mode)、推理演示
LLMs之ChatGLM3:ChatGLM3/ChatGLM3-6B的简介—“对话格式”功能介绍(推理系统如何解析参数/采用Python代码形式/编写工具调用的代码/Manual Mode)、推理演示(Chat/Tool/Code Interpreter)、微调(AdvertiseGen/ToolAlpaca)实现之图文教程攻略
目录
相关文章
LLMs之ChatGLM3:ChatGLM3/ChatGLM3-6B的简介(多阶段增强+多模态理解+AgentTuning技术)、安装、使用方法之详细攻略
LLMs之ChatGLM3:ChatGLM3/ChatGLM3-6B的简介—“对话格式”功能介绍(推理系统如何解析参数/采用Python代码形式/编写工具调用的代码/Manual Mode)、推理演示(Chat/Tool/Code Interpreter)、微调(AdvertiseGen/ToolAlpaca)实现之图文教程攻略
ChatGLM3的“对话格式”功能的简介及其使用方法
1、“对话格式”功能的简介:对话能力、工具调用能力、代码解释器能力
(0)、对话格式中tokenization的简介
A1、实现“Tool工具调用”的功能
LLMs之ChatGLM3:分别从ChatGLM3的源代码和训练样本数据中,带你探究大模型是如何实现Tool(工具调用)这一炸天功能的
(1)、工具调用输出格式、反馈原理
(2)、推理系统如何解析参数
(3)、为何采用Python代码形式(而非 JSON )
(4)、如何具体实现—编写工具调用的代码
(5)、Manual Mode(测试模型能否看懂你的话):
A2、实现“Code Interpreter代码解释器”的功能:撰写算法编程功能、绘图功能
ChatGLM3的推理演示
第一步,基于Steamlit部署为网络应用
第二步,功能测试
A1、Chat功能测试
(1)、只用表情的格式回答
A2、Tool调用测试:
T1、单个Tool工具调用
(1)、查天气
(2)、查论文:利用arixiv查询Agent Tuning相关的工作
T2、多个Tool工具调用:arixiv+weather+calculator等
A3、Code Interpreter测试
ChatGLM3的微调
A1、对话微调
1.0、校验loss_mask是否有问题
1.1、基于公开数据集进行微调:AdvertiseGen、ToolAlpaca
T1、AdvertiseGen数据集:输入输出
T2、ToolAlpaca数据集:多轮对话
(1)、多轮对话的微调:比如Tool format格式变化的需求,将Tool 的额帕卡转为Tool的自然语言形式
微调之前
微调之后
1.2、代码实战
代码解读:如何把对话变成一系列的token
代码解读:启动服务
参考资料
相关文章
LLMs之ChatGLM3:ChatGLM3/ChatGLM3-6B的简介(多阶段增强+多模态理解+AgentTuning技术)、安装、使用方法之详细攻略
LLMs之ChatGLM3:ChatGLM3/ChatGLM3-6B的简介(多阶段增强+多模态理解+AgentTuning技术)、安装、使用方法之详细攻略-CSDN博客
LLMs之ChatGLM3:ChatGLM3/ChatGLM3-6B的简介—“对话格式”功能介绍(推理系统如何解析参数/采用Python代码形式/编写工具调用的代码/Manual Mode)、推理演示(Chat/Tool/Code Interpreter)、微调(AdvertiseGen/ToolAlpaca)实现之图文教程攻略
https://yunyaniu.blog.csdn.net/article/details/134342685
ChatGLM3的“对话格式”功能的简介及其使用方法
1、“对话格式”功能的简介:对话能力、工具调用能力、代码解释器能力
| 简介 |
对话格式:方便用于多轮训练,每个token有着非常明确的意思, |
| 模板 |
•角色 special token: –<|system|> #系统提示词,指明模型扮演的角色等信息。当然可以把他放在任何地方,但是期望用户把它放在第一个位置; –<|user|> #用户输入,用户的指令; –<|assistant|> #模型回复,模型要做的事情; –<|observation|> #工具调用、代码执行结果;本质是承接模型的工具调用,并开启模型调用结果进而影响模型下一步动作; |
| 解释 |
•<|assistant|> {metadata} : #每一行 –工具调用:{metadata}为调用的工具名。例如<|assistant|> test_tool 表示模型希望调用test_tool 工具; –Code Interpreter: 固定为<|assistant|>interpreter •分隔符:角色标签(包括 metadata) 后跟换行符,但标签前不跟; |
| 案例 |
•示例:比如system告诉它,模型的角色是ChatGLM3,用户说hi,模型说hello。 –<|system|> –You are ChatGLM3. <|user|> –Hi <|assistant|> –Hello, how can I help you? |
(0)、对话格式中tokenization的简介
| tokenization |
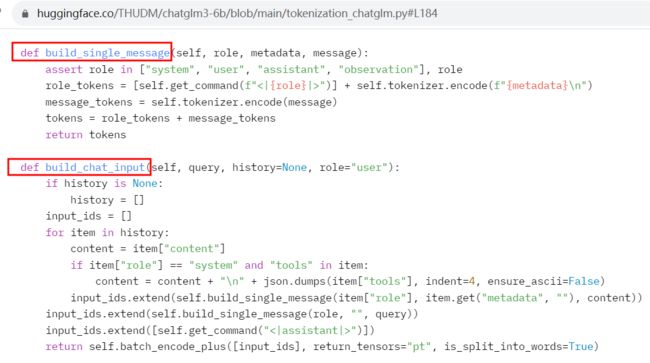
对话格式:tokenization ChatGLM3 的 special token 是防注入的,因此,不能直接通过拼接字符串得到正确的模型输入; >> T1、采用模型的chat(), stream_chat () 函数并传入历史、工具、角色等信息进行交互; >> T2、采用tokenizer 的 build_chat_input () 函数手动构建模型输入; •注意get_command函数函数的使用,直接找到角色对应的 special token •用户即使输入了形如 <|user|> 的内容也不会被编码为special token 地址:https://huggingface.co/THUDM/chatglm3-6b/blob/main/tokenization_chatglm.py#L184
|
A1、实现“Tool工具调用”的功能
| 简介 |
模型大多数情况下是正常对话,那么模型什么时候要去调用API呢?推理系统除了通过观察metadata来判断以外,它还可以通过观察模型中的最后一个token来判断模型是去要做什么 >> 如果生成的是EOS或User,模型要表达的意思是让输入的话语权交给用户去完成; >> 如果模型生成的是observation,我需要推理系统的帮助去执行工具,把执行工具后的结果插进来; |
| 功能 |
工具调用:利用json的格式告诉模型你需要调用哪些工具 • 如果要利用一些工具,就把system固定为一句话,固定system prompt 以发挥最好效果。 • 工具定义:JSON 对象列表包含三个字段,即name(工具名), description(描述),parameters(参数定义); • 参数定义可选择如下所示的JSON Schema 格式(OpenAI的格式); Answer the following questions as best as you can. You have access to the following tools: [ { "name" : "track", "description": "追踪指定股票的实时价格", "parameters" : { "type" : "object", "properties": { "symbol": { "description" : "需要追踪的股票代码" } }, "required" : [ 'symbol' ] } } ] |
LLMs之ChatGLM3:分别从ChatGLM3的源代码和训练样本数据中,带你探究大模型是如何实现Tool(工具调用)这一炸天功能的
https://yunyaniu.blog.csdn.net/article/details/134844140
(1)、工具调用输出格式、反馈原理
| 工具调用输出格式 |
工具调用输出格式:写一个python代码块(本质是函数调用) • 除了正常使用 <|assistant|> 进行对话外,模型在感到需要调用工具时会生成 <|assistant|>{metadata} ,其中 metadata 为调用的工具名 • 对话内容为Python 代码块,最终调用tool_call 函数传参数 • 例如:(增加了额外换行以提升可读性) <|user|> Can you tell me how the weather is in Beijing now? <|assistant|> Sure! I can help with that by querying a weather API. <|assistant|> get_weather ```python tool_call(location='Beijing') ``` |
| 工具调用结果反馈 |
工具调用结果通过<|observation|> 返回给模型,observation是环境带来的插入的东西,推理系统再次给一个system token,而它看到system token后,就是知道环境的事情已经结束,直接该总结输出了; 例如: <|user|> Can you tell me how the weather is in Beijing now? <|assistant|> Sure! I can help with that by querying a weather API.<|assistant|>get_weather ```python tool_call (location='Beijing') ``` <|observation|> {"weather": "cloudy", temperature": 15.6}<|assistant|> It's cloudy now in Beijing and the temperature is 15.6 ºC. |
| 模型调用工具时给出<|observation|> 作为结束 token 例如: <|user|> Can you tell me how the weather is in Beijing now?<|assistant|> Sure! I can help with that by querying a weather API.<|assistant|>get_weather get_weather get_weather get_weatherget_weather get_weather ```python tool_call (location='Beijing') ``` <|observation|> 因此,需要检查 <|user|> 与 <|observation|> 两种终止 token 并作不同处理 |
(2)、推理系统如何解析参数
| 解析参数 |
推理系统如何解析参数呢? <|user|> Can you tell me how the weather is in Beijing now?<|assistant|> Sure! I can help with that by querying a weather API.<|assistant|> ```python tool_call (location='Beijing') ```<|observation|> |
| 1、如何提取参数: T1、采用python内置的eval()函数可以简单了解但不适合实际部署:因为eval()函数虽然方便,但需要注意安全性问题,最好在隔离环境中运行。因为如果是危险的语句就不饿可以,比如eval('exec("import os ; os.system(\'sudosudo sudorm –rf / rf /\')")') T2、手动解析AST:如果调用eval,它是符合python语法,所以可以采用python的库AST直接解析出来即可。抽象语法树中抽取出调用工具的参数即可; T3、采用Transformers Agents:限制能够执行的代码: 限制执行的代码只能调用工具和 print 函数,故它不会执行OS这种危险的行为 ,https://huggingface.co/docs/transformers/transformers_agents#code -execution |
(3)、为何采用Python代码形式(而非 JSON )
| 采用Python代码形式 |
为何使用Python 代码形式(而非 JSON )? 众说周知的是,LangChain框架中希望模型给出的是json格式,但是本项目中采用的是python形式。原因有以下几点 >> 模型训练数据中的 Python远远强于JSON ,模型书写正确率高,而 Python 的表达能力(比如字符串、数字等)是 JSON 的真超集; >> Python更为灵活(比Json形式调用的自由度更大,拓展性更强),可以接入更多调用形式(目前尚未实现)。考虑模型在调用工具前可进行简单 Python 处理,考虑支持多工具连续调用等功能。 |
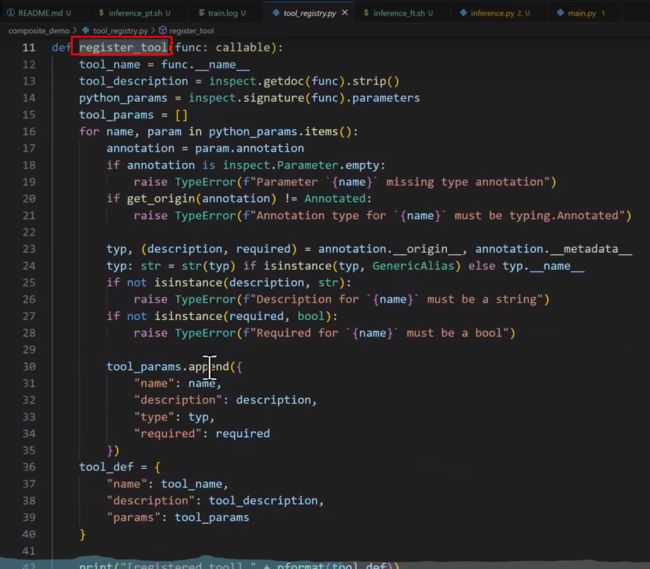
(4)、如何具体实现—编写工具调用的代码
| 通过YAML定义工具 |
# demo中的手动模式通过YAML定义工具 # tool_registry模式在tool_registry.py中定义工具: @register_tool def get_weather( city_name: Annotated[str,'The name of the city to be queried',True],) -> str : """ get the weather for `city_name ` in the following week """ pass ''' Annotated的三个部,分分别为参数类型、描述与是否必需 docstring会被作为工具的描述 ''' |

(5)、Manual Mode(测试模型能否看懂你的话):

| 背景 |
|
| 简介 |
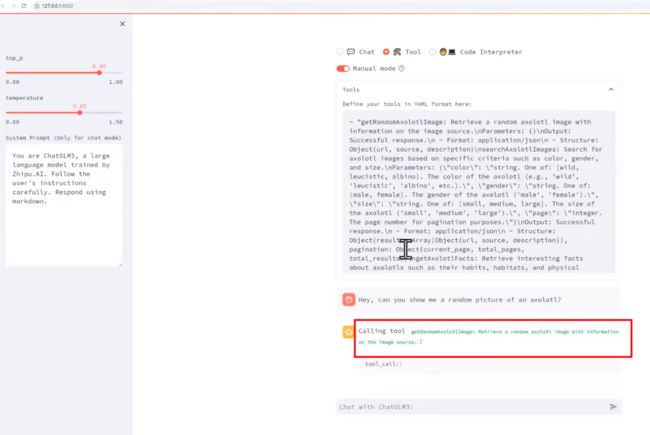
Manual Mode可以测试模型能否看懂你的话。 不需要每次都要直接写python代码来完整的定义各个工具,把工具的描述直接写为一个Yaml的形式,然后会自动转为json的形式 |
A2、实现“Code Interpreter代码解释器”的功能:撰写算法编程功能、绘图功能
| 对话格式 |
同工具调用类似,需要固定system prompt 以发挥最好效果: <|system|> 你是一位智能 AI 助手,你叫 ChatGLM ,你连接着一台电脑,但请注意不能联网。在使用 Python 解决任务时,你可以运行代码并得到结果,如果运行结果有错误,你需要尽可能对代码进行改进。你可以处理用户上传到电脑的文件,默认存储路径是 /mnt/data/。 |
| 撰写算法编程功能 |
除正常对话外,<|assistant|>interpreter 执行代码: <|user|> Calculate the 10th Fibonacci number<|assistant|> The Fibonacci sequence is defined as each number equaling the sum of previous two numbers. Therefore, we can write a recursive function to calculate it. <|assistant|>interpreter ```python def fibonacci (n): if n == 0: return 0 elif n == 1: return 1 else: return fibonacci (n -1)+ fibonacci (n-2) fibonacci_10 = fibonacci_10 = fibonacci (9)+fibonacci (8) fibonacci_10 ``` <|observation|> 55 <|assistant|> The 10th Fibonacci number is 55. 注意,可以实现多个用户并发执行,但是不同用户调用的编译器是同一个kernel(同时保存连续的变量),所以,一个demo起了多个用户,那么不同用户可以看到彼此的局部变量。 |
| 绘图功能 |
对于图片,直接返回[Image] 占位符即可 •与工具调用类似,执行代码时模型给出 <|observation|> 作为终止 token; •模型可能会在看到 <|observation|> 后继续对话和执行代码;
|

ChatGLM3的推理演示
第一步,基于Steamlit部署为网络应用
| 执行脚本 |
streamlit run web_demo2.py streamlit run main.py --server.address=127.0.0.1 |
第二步,功能测试
A1、Chat功能测试
(1)、只用表情的格式回答

A2、Tool调用测试:
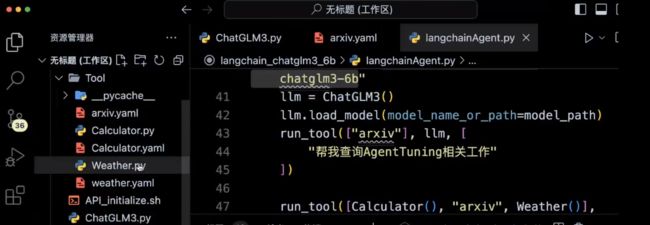
利用LangChain工具调用ChatGLM3:搜索工具

T1、单个Tool工具调用
(1)、查天气

(2)、查论文:利用arixiv查询Agent Tuning相关的工作

T2、多个Tool工具调用:arixiv+weather+calculator等


A3、Code Interpreter测试
ChatGLM3的微调
A1、对话微调
| 简介 |
(1)、与此前的做法不同,chatglm3-6b 推荐使用多轮对话格式进行微调 >> 即将多个不同角色的对话内容直接拼接进行 teacher -forcing >> Special token 的加入使得多轮训练变得容易 >> 不再特殊区别 prompt 和 response (2)、需正确配置 loss_mask ,即哪些 token的预测需要模型去学习的,哪些token不用模型去学习。判断原则,loss_mask 的配置依据是推理时的行为: >> 如果推理的时候,模型自己生成的 token,就需要计算 loss(即需要学习); >> 如果token是推理系统插入的,则无需计算 loss; |
| loss_mask的假设 |
1、在对话微调时,对 loss_mask 做如下假设 (1)、 <|system|> <|user|> 和 <|observation|>,这三类角色(此三类token后续跟着的对话)所预测的 token不需要去学习,但这并不意味着这些 token 不需学习。 (2)、<|assistant|>,所预测的 token都是要学习的,但也不总是需要学习;如 few -shot prompt 中的 <|assistant|> 角色通常无需学习。 2、原因:<|system|> user|> 和 <|observation|> 总是由推理系统插入;<|assistant|> 所预测的内容总是由模型产生; |
| 案例理解 |
第一行是推荐使用的system prompt,下述内容中浅绿色是由模型产生的,
|

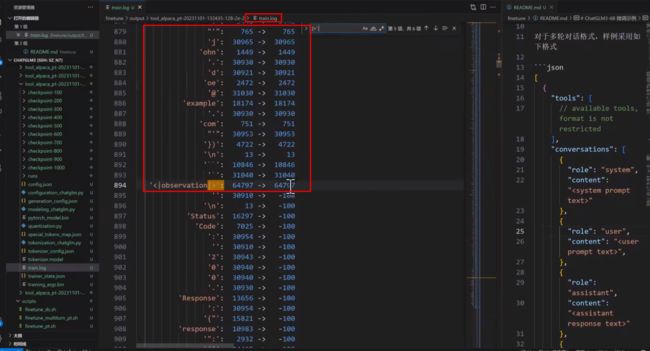
1.0、校验loss_mask是否有问题

1.1、基于公开数据集进行微调:AdvertiseGen、ToolAlpaca
| 选择数据集 |
•示例数据 -AdvertiseGen & ToolAlpaca |
| 经验总结 |
•提示 –微调后模型的分布发生变化,通用能力和泛化性可能会减弱,比如输入“你好”,模型就不会回答了; –加入通用数据(如 ShareGPT )进行混合训练可能缓解通用能力的衰减; –若对 Base模型进行微调,可自行设计生成格式,无需遵循前述格式; |
T1、AdvertiseGen数据集:输入输出

T2、ToolAlpaca数据集:多轮对话
(1)、多轮对话的微调:比如Tool format格式变化的需求,将Tool 的额帕卡转为Tool的自然语言形式
当前的base模型的回复不是很适应。可以采用P-Tuning的方式用400steps微调,就可以达到很好的效果。
微调之前
微调之后


1.2、代码实战
代码解读:如何把对话变成一系列的token
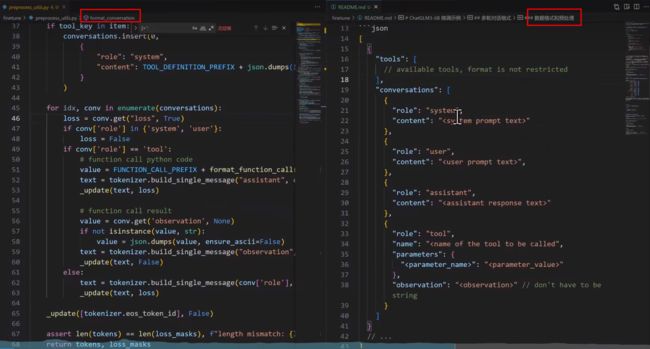
代码解读:启动服务

参考资料
PPT文件下载:百度网盘 请输入提取码
提取码: na5c