高频面试题-请把Java垃圾回收器说清楚!
深入理解Java虚拟机一书中写到:如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。
不同的时代,出现了不同了垃圾收集器,它们被不断的应用在各个版本的Java虚拟机中。
首先来画一张图,将具体的几个垃圾收集器展示出来。

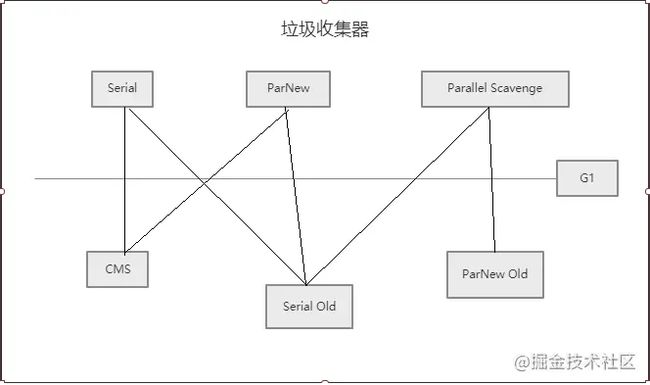
上图就是我们要说的一共七种收集器,图中一共分为两大部分,上半部分(Serial、ParNew、Parallel Scavenge)分属于新生代收集器,下半部分(CMS、Serial Old、ParNew Old)分属于老年代收集器,而G1算是一个特殊的收集器,因为其不分新生代和老年代。
收集器的迭代
JDK1.3.1之前,Serial收集器是唯一的新生代收集器,可以说除此之外,毫无选择。
JDK1.3.1之后,就出现了Parallel、CMS、G1等等的收集器。
从JDK1.7 Update14之后,其虚拟机中的收集器正式更换为G1收集器。
几个非常重要的概念
Stop The World(垃圾收集停顿机制): 当垃圾收集器在进行垃圾收集时,必须要暂停其他的所有线程,这个暂停状态将会持续到本次垃圾收集任务结束;这个过程就是Stop The World,可以说这就是一个垃圾收集停顿机制,也是所有垃圾收集器都会有的机制,毕竟每次收集时就停顿线程,给系统会造成一定程度的延迟。
虽然没办法解决必须停顿所有线程的问题,但是经过多年的努力,多个版本垃圾收集器的更新换代,这个停顿过程也越来越短。
Throughput(吞吐量): 运行用户代码时间 / (运行用户代码时间 + 垃圾收集停顿时间),吞吐量越大,代表着收集器性能越好。
收集器中的并发和并行:
(1)并发,垃圾收集任务与工作线程并发执行,但这并不代表就不会存在停顿时间,只是会大幅度减少停顿时间。
(2)并行,在收集过程中,并行执行多个收集任务,以此来减少Stop The World带来的停顿时间,从而提高垃圾收集的性能。
Minor GC和Full GC:
Minor GC:新生代GC,在新生代内存中的垃圾收集工作,具有执行频繁、回收速度快等特点。
Full GC:老年代GC,在老年代内存中的垃圾收集工作,老年代GC还被称作Major GC,在执行时,可能会执行一次Minor GC,但是这个Minor GC不一定会执行;当然了,Full GC的执行速度要比Minor GC的执行速度要慢数倍之多。
Serial收集器
收集区域:新生代
使用算法:复制算法
是否支持并行:不支持,单线程收集器。
是否支持并发:不支持
号称年龄最大、最基本的收集器,作为单线程收集器,简单高效是它与其他单线程收集器之间的优势;也是因为单线程的缘故,没了线程之间的交互开销,在一定程度上,比如轻量应用级系统,就造就了其简单高效的应用模式。
这里也说一下其进行垃圾收集时的大概过程:
(1)单线程执行GC,并且暂停所有的工作线程。
(2)采用复制算法进行收集。
(3)收集完成后,则将工作线程开启。这里还可能会继续进行Full GC。
ParNew
收集区域:新生代
使用算法:复制算法
是否支持并行:支持,多线程收集器。
是否支持并发:不支持
ParNew收集器可以说成是Serial收集器的多线程版本,除了是并行处理收集工作之外,其余的特征都与Serial收集器相同。
在单CPU的环境中,一定还是Serial收集器是最优选,因为多了线程交互,所以在多CPU的服务器环境下,ParNew收集器的性能还是优于Serial收集器的。
ParNew的工作过程大概是以下这样:
(1)多线程执行GC,并且暂停所有的工作线程。
(2)采用复制算法进行收集。
(3)收集完成后,则将工作线程开启。这里还可能会继续进行Full GC。
Parallel Scavenge
收集区域:新生代
使用算法:复制算法
是否支持并行:支持,多线程收集器。
是否支持并发:不支持
Parallel Scavenge收集器这个收集器与其他收集器不同的地方,就在于其目的是为了控制吞吐量,其他收集器则是为了尽可能的提高吞吐量,也就是降低、缩短收集工作进行时的停顿时间。
Parallel Scavenge收集器为了控制吞吐量,特定的提供了两个参数来实现吞吐量。
-XX:MaxGCPauseMillis(最大垃圾收集停顿时间):设置一个毫秒值,收集器会尽可能的保证内存的回收时间不超过这个值,并不会使收集速度变快。
-XX:GCTimeRatio(吞吐量大小):0-100的整数,这个值就代表着垃圾收集时间在整个收集过程时间的比例。
Parallel Scavenge收集器也被称为吞吐量收集器,还可以通过-XX:SurvivorRatio参数设置Eden区和Survivor区的比例。
Serial Old
收集区域:老年代
使用算法:标记-整理算法
是否支持并行:不支持,单线程收集器。
是否支持并发:不支持
与Serial收集器略有不同,但是两者的收集工作过程没什么差异。
Parallel Old
收集区域:老年代
使用算法:标记-整理算法
是否支持并行:支持,多线程收集器。
是否支持并发:不支持
Parallel Old从JDK1.6中开始提供使用,在对吞吐量要求高的情况,或者是CPU资源敏感的情况下,还是比较推荐考虑此收集器的。
CMS
收集区域:老年代
使用算法:标记清楚算法
是否支持并行:支持,多线程收集器。
是否支持并发:支持
CMS,全称Concurrent Mark Sweep,旨在获取最短回收停顿时间为目标的收集器,CMS相对比较经典,为了实现它的目标,它使用了四步来实现收集过程。
(1)初始标记(2)并发标记(3)重新标记(4)并发清除
这样就能消除Stop The World了吗?那是不可能的,在初始标记、并发标记时依然会出现Stop The World。
具体的这四步主要去干了点什么,咱们回头在另一篇文章里再说。
这里还需要注意一点,那就是CMS是使用的标记-清楚算法,那就注定会产生大量的内存碎片,这个在面试官嘴里会常问哦。
G1
收集区域:全部
使用算法:复制算法
是否支持并行:支持,多线程收集器。
是否支持并发:支持
G1其实是可以单独拿出一篇文章来写一下的,之后会做个详细解释,今天我们就只来看一下G1的几个特点。
1.并行、并发共存,在多CPU多核的资源下,能更有效的缩短Stop The World停顿的时间。
2.虽然是只用一个收集器就将所有的内存进行清理,但是依然会进行分代收集,只不过是采用了不同的方式去处理。
3.因为是管理着全部内存,所以,在空间维度上,G1将内存分为多个Region空间,以此来解决用复制算法来收集的情况。
4.G1还有一个优势就是,能可预测停顿时间。
组合使用策略
七种垃圾收集器,除了G1将新生代和老年代全部负责之外,其余的六种如何来搭配组合呢?
从名称上来,Serial和Serial Old是可以组合的,Parallel Scavenge和Parallel Old是可以组合的。
那么从现实的角度出发,Serial可以与Serial Old、CMS进行组合,因为ParNew等同于Serial的多线程版本,所以ParNew和Serial一样,都可以与Serial Old、CMS进行组合。
Parallel Scavenge收集器除了能和Parallel Old收集器配合使用,还能和Serial Old收集器进行组合。
来,上图,更清楚一些,
到这里,七种收集器就全部说完了,只有了解了本质后,我们也就可以逐渐进行调优的知识储备了,基础最重要,大家珍重。