数据分析案例-图书书籍数据可视化分析(文末送书)

♂️ 个人主页:@艾派森的个人主页
✍作者简介:Python学习者
希望大家多多支持,我们一起进步!
如果文章对你有帮助的话,
欢迎评论 点赞 收藏 加关注+
目录
1.项目背景
2.数据集介绍
3.技术工具
4.导入数据
5.数据可视化
文末推荐与福利
1.项目背景
随着信息技术的迅猛发展和数字化时代的来临,图书出版、销售与阅读方式均发生了翻天覆地的变化。传统的纸质书籍面临着电子书、在线阅读等新型阅读方式的挑战。在这一大背景下,对于图书市场、读者阅读习惯以及书籍流通情况的数据分析变得尤为重要。
图书书籍数据可视化分析实验旨在通过收集、整理和分析大量的图书相关数据,利用数据可视化技术,将复杂的数据转化为直观、易理解的图形和图像。这样可以帮助出版社更好地了解市场趋势,优化图书出版策略;帮助书店和网上书城精确掌握库存和销售情况,调整进货和销售策略;同时,也可以帮助读者更清晰地了解自己的阅读习惯和偏好,以便做出更合适的阅读选择。
此外,对于图书馆和学术研究机构而言,图书书籍数据可视化分析还有助于提高图书管理和利用的效率,促进学术研究和知识传播。例如,通过分析图书馆的借阅数据,可以了解读者的借阅习惯和需求,进而优化图书采购和馆藏结构;通过分析学术著作的引用数据,可以评估研究成果的影响力和学术价值。
综上所述,图书书籍数据可视化分析实验不仅具有重要的商业价值,还有助于推动图书行业的创新发展和学术研究的进步。在这一背景下,开展此类实验显得尤为必要和迫切。
2.数据集介绍
数据集来源于Kaggle,这个数据集包含了从wonderbk.com(一个受欢迎的在线书店)抓取的信息。该数据集包含103,063本书的详细信息,其中包含标题、作者、描述、类别、出版商、起始价格和出版日期等关键属性。
Title:书的标题。
Authors:本书的作者。
Description :对本书的简要描述。
Category:书籍所属的类别或流派。
Publisher:负责本书的出版社。
Price:书籍的初始价格。
Publish Date:出版年份。
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.导入数据
import warnings
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
sns.set(font='SimHei')
warnings.filterwarnings('ignore')
df = pd.read_csv('BooksDataset.csv')
df.head()
查看数据大小

查看数据基本信息
查看描述性统计

查看缺失值情况

删除缺失值

检测是否存在重复值

删除重复值

处理变量
# 处理作者这一列数据,提取出作者名
df['Authors'] = df['Authors'].str.replace(r'^By\s+', '', regex=True)
# 处理价格
df['Price'] = df['Price'].apply(lambda x:float(x.split('$')[1].replace(',','')))
# 发布年份
df['Publish Date'] = df['Publish Date'].apply(lambda x:int(x.split(', ')[-1].split(' ')[-1]))5.数据可视化
df['Authors'] = df['Authors'].str.split(',').apply(lambda x: ' '.join(reversed(x)) if len(x) > 1 else x[0])
# 显示清洗后的前10位作者
top_10_authors = df['Authors'].value_counts().head(10)
# 十大高产作家(条形图)
plt.figure(figsize=(10, 6))
top_10_authors.plot(kind='bar', color='orange')
plt.title('Top 10 Prolific Authors')
plt.xlabel('Authors')
plt.ylabel('Number of Books')
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()
# 不同作者的平均价格(条形图)
average_prices_by_author = df.groupby('Authors')['Price'].mean().sort_values(ascending=False).head(10)
plt.figure(figsize=(10, 6))
average_prices_by_author.plot(kind='bar', color='green')
plt.title('Average Prices by Top 10 Authors')
plt.xlabel('Authors')
plt.ylabel('Average Price ($)')
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()
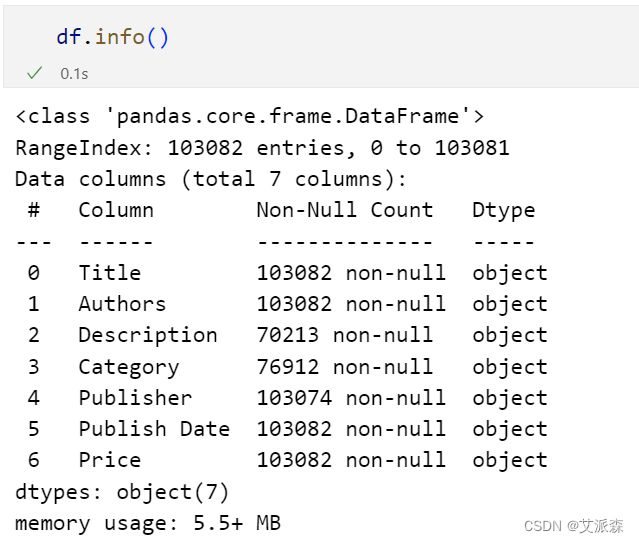
top_prolific_authors = df['Authors'].value_counts().head(10)
plt.figure(figsize=(10, 6))
sns.barplot(x=top_prolific_authors.values, y=top_prolific_authors.index, palette='coolwarm')
plt.title('Top 10 Prolific Authors')
plt.xlabel('Number of Books')
plt.ylabel('Authors')
plt.tight_layout()
plt.show()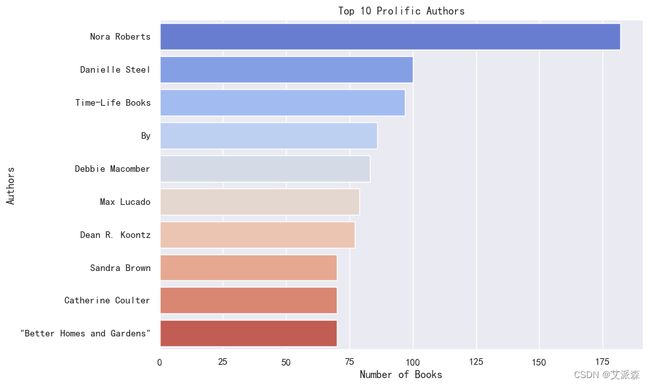
average_prices_by_category = df.groupby('Category')['Price'].mean().sort_values(ascending=False)
top_10_categories_by_price = average_prices_by_category.head(10)
# 按平均价格可视化前10个类别(条形图)
plt.figure(figsize=(10, 6))
sns.barplot(x=top_10_categories_by_price.values, y=top_10_categories_by_price.index, palette='viridis')
plt.title('Top 10 Categories by Average Price')
plt.xlabel('Average Price ($)')
plt.ylabel('Category')
plt.tight_layout()
plt.show()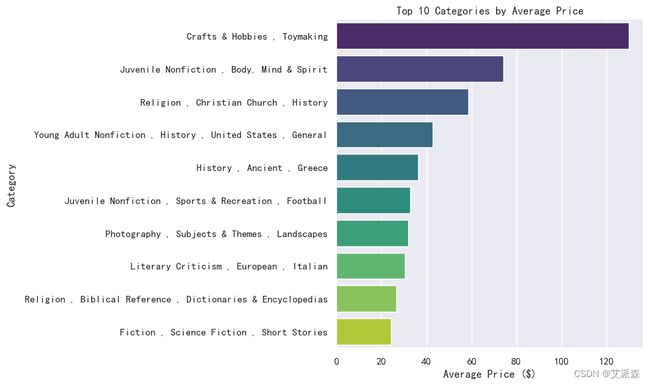
top_publishers = df['Publisher'].value_counts().head(10)
plt.figure(figsize=(8, 8))
plt.pie(top_publishers, labels=top_publishers.index, autopct='%1.1f%%', startangle=140)
plt.title('Top 5 Publishers Distribution')
plt.tight_layout()
plt.show()
from wordcloud import WordCloud
cleaned_descriptions = df['Description'].dropna().tolist()
text = ' '.join(cleaned_descriptions)
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(text)
plt.figure(figsize=(12, 8))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('Word Cloud of Book Descriptions')
plt.tight_layout()
plt.show()
filtered_years = df[(df['Publish Date'] > 1950)&(df['Publish Date'] < 2024)]
yearly_counts_after_1950 = filtered_years['Publish Date'].dropna().value_counts().sort_index()
# 由于没有足够的1950年以前的数据,所以绘制1950年以后的趋势图
plt.figure(figsize=(10, 6))
yearly_counts_after_1950.plot(kind='line', marker='o', color='blue')
plt.title('Book Releases Over the Years (After 1950)')
plt.xlabel('Year')
plt.ylabel('Number of Books Released')
plt.grid(True)
plt.tight_layout()
plt.show()
文末推荐与福利
《Excel高效办公:文秘与行政办公(AI版)》免费包邮送出3本!

内容简介:
随着信息技术的快速发展,Excel作为一款功能强大的电子表格软件,已经被广泛应用于文秘与行政办公领域。Excel不仅可以帮助文秘人员和行政助理高效地处理数据、制作报表和统计图表,而且还可以自动化处理各种日常工作,从而节省时间和精力,提高工作效率。
本书还创新地将ChatGPT引入到学习Excel行政与文秘技能教学中,其提问与使用方式同样适用于国内常用AI语言大模型,如百度的“文心一言”、科大讯飞的“星火”大模型。本书先通过 ChatGPT认识和了解文秘与行政工作中的基础知识,再根据实际的工作案例,讲述了在文秘与行政工作中使用Excel制作各种办公表格文档的方法与工作技能。
本书既适合在公司中从事文秘与行政工作的人员学习,也适合作为广大职业院校文秘与行政相关专业的学习用书,同时还可以作为文秘与行政技能培训教材。
编辑推荐:
★超实用:通过30多个实战案例和操作技巧,使读者能够快速上手并灵活运用AI工具提高办公效率。
★巨全面:内容设计从文秘与行政管理工作实际出发,涵盖工作中各项事务的数据统计、分析与处理等要求的全方面内容。
★真好懂:一步一图的操作讲解,一看就懂,思路清晰,老板要的数据统计、分析、结论全都有。
★高回报:看完本书,菜鸟变高手,成为制作各种文档的多面手,零门槛提高文秘与行政办公硬核能力。
- 抽奖方式:评论区随机抽取3位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2024-1-22 20:00:00
当当购买链接:http://product.dangdang.com/29658186.html
京东购买链接:https://item.jd.com/13953793.html
名单公布时间:2024-1-22 21:00:00
资料获取,更多粉丝福利,关注下方公众号获取
