sklearn.svm.SVC 参数说明
sklearn中的SVC函数
本身这个函数也是基于libsvm实现的,所以在参数设置上有很多相似的地方。(PS: libsvm中的二次规划问题的解决算法是SMO)。
sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3, gamma='auto', coef0=0.0, shrinking=True, probability=False,tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=None,random_state=None)
主要调节的参数有:C、kernel、degree、gamma、coef0。
软间隔:优化的目标函数:
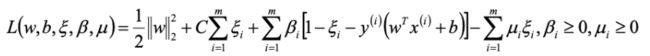
核函数:

非线性可分svm:是利用核函数降低计算量,实现高维空间的线性可分,在高维空间中是利用软间隔的方法实现线性可分。
参数:
l C:C-SVC的惩罚参数C?默认值是1.0
C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但泛化能力弱。C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。
l kernel :核函数,默认是rbf,可以是‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’
0 – 线性:u'v
1 – 多项式:(gamma*u'*v + coef0)^degree
2 – RBF函数:exp(-gamma|u-v|^2)
3 –sigmoid:tanh(gamma*u'*v + coef0)
l degree :多项式poly函数的维度,默认是3,选择其他核函数时会被忽略。
l gamma : ‘rbf’,‘poly’ 和‘sigmoid’的核函数参数。默认是’auto’,则会选择1/n_features
l coef0 :核函数的常数项。对于‘poly’和 ‘sigmoid’有用。
l probability :是否采用概率估计?.默认为False
l shrinking :是否采用shrinking heuristic方法,默认为true
l tol :停止训练的误差值大小,默认为1e-3
l cache_size :核函数cache缓存大小,默认为200
l class_weight :类别的权重,字典形式传递。设置第几类的参数C为weight*C(C-SVC中的C)
l verbose :允许冗余输出?
l max_iter :最大迭代次数。-1为无限制。
l decision_function_shape :‘ovo’, ‘ovr’ or None, default=None3
l random_state :数据洗牌时的种子值,int值
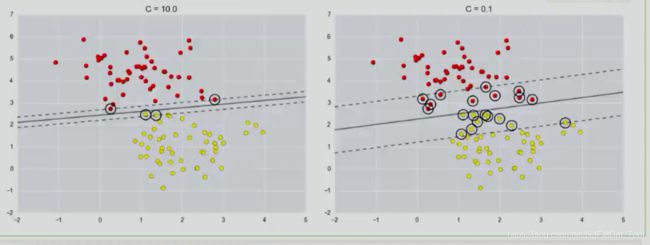
惩罚项系数C:
即对误差的宽容度。c越高,说明越不能容忍出现误差,容易过拟合。C越小,容易欠拟合。C过大或过小,泛化能力变差,具体效果为:
c越大,分类越严格,不能有错误
c越小,意味着有更大的错误容忍度
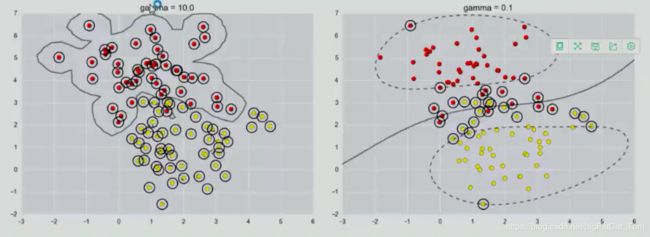
参数gamma:
一种解释:
参数gamma主要是对低维的样本进行高度度映射,gamma值越大映射的维度越高(怎么看出来维度越高???),训练的结果越好,但是越容易引起过拟合,即泛化能力低。具体效果如下图所示,当gamma较大时,决策平面如一个梅花,分类的效果好,但是模型的鲁棒性不一定高。
另一种解释:
gamma是选择RBF函数作为kernel后,该函数自带的一个参数。隐含地决定了数据映射到新的特征空间后的分布,gamma越大,支持向量越少,gamma值越小,支持向量越多。支持向量的个数影响训练与预测的速度。RBF公式里面的sigma和gamma的关系如下:
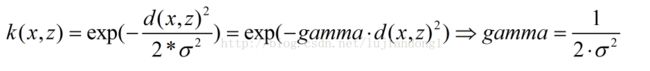
这里面大家需要注意的就是gamma的物理意义,大家提到很多的RBF的幅宽,它会影响每个支持向量对应的高斯的作用范围,从而影响泛化性能。我的理解:如果gamma设的太大, 会很小,很小的高斯分布长得又高又瘦, 会造成只会作用于支持向量样本附近,对于未知样本分类效果很差,存在训练准确率可以很高,(如果让无穷小,则理论上,高斯核的SVM可以拟合任何非线性数据,但容易过拟合)而测试准确率不高的可能,就是通常说的过训练;而如果设的过小,则会造成平滑效应太大,无法在训练集上得到特别高的准确率,也会影响测试集的准确率。
会很小,很小的高斯分布长得又高又瘦, 会造成只会作用于支持向量样本附近,对于未知样本分类效果很差,存在训练准确率可以很高,(如果让无穷小,则理论上,高斯核的SVM可以拟合任何非线性数据,但容易过拟合)而测试准确率不高的可能,就是通常说的过训练;而如果设的过小,则会造成平滑效应太大,无法在训练集上得到特别高的准确率,也会影响测试集的准确率。
参考:
https://blog.csdn.net/weixin_41712499/article/details/82899971
https://blog.csdn.net/bigFatCat_Tom/article/details/93790753