大数据学习之 Flink
目录
一:简介
二:为什么选择Flink
三:哪些行业需要
四:Flink的特点
五:与sparkStreaming的区别
六:初步开发
七:Flink配置说明
八:环境
九:运行组件
一:简介
Flink 是一个框架和分布式得计算引擎,对于无界和有界数据流进行状态计算
二:为什么选择Flink
流数据更真实地反应了我们得生活方式
传统得数据架构是基于有限数据集的
低延迟,高吞吐,结果的准确性和良好的容错性
三:哪些行业需要
电商和市场营销:数据报表,广告投放,业务流程需要
物联网:传感器实时数据采集和显示,实时报警,交通运输业
电信业:基站流量调配
银行和金融业:实时结算和通知推送,实时监测异常行为
四:Flink的特点
事件驱动
基于流的世界观(一批数据被认为是有界流)
提供了分层的API
支持事件事件和处理事件
精确一次(exactly-once)的状态一致性的保证
低延迟
可以与众多常用的储存系统连接
高可用,动态扩展
五:与sparkStreaming的区别
1. Flink 是真正的流计算,而SparkStreaming 把数据分成一批一批的数据,所以Flink要快,延迟低
2. 数据模型不一样,spark采用的RDD模型,sparkStreaming的DStream 实际上也就是一组组小批数据RDD的集合,Flink 基于数据模型是流数据,以及事件序列
3. 运行时的架构不一样,spark是批计算,将DAG划分不同的stage一个完成后才可以计算下一个Flink是标准的流执行模式,一个事件在一个节点处理完成后可以直接发往下一个节点进行处理
六:初步开发
添加依赖:
org.apache.flink
flink-scala_2.11
1.7.2
org.apache.flink
flink-streaming-scala_2.11
1.7.2
使用Flink做批处理代码如下:
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
val inputPath = "C:\\hnn\\Project\\Self\\spark\\in\\hello.txt"
//读取文件内容
val inputDateSet: DataSet[String] = env.readTextFile(inputPath)
val words = inputDateSet.flatMap(_.split(" "))
.map((_, 1))
.groupBy(0)
.sum(1)
words.print()使用Flink做流处理代码如下:(本地需要启动nc(netCat)服务来模拟 数据流的产生)
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//接收一个sock文本流
val dataStream: DataStream[String] = env.socketTextStream("localhost", 44444)
val result: DataStream[(String, Int)] = dataStream.flatMap(_.split(" "))
.filter(_.contains("a")) //过滤所以带a的单词
.map((_, 1)) //重组map
.keyBy(0) // 相当于groupBy
.sum(1)
result.print()
env.execute()七:Flink配置说明
#jobmanager ip地址
jobmanager.rpc.address: localhost
# jobmanager 端口号
jobmanager.rpc.port: 6123
# JobManager JVM 堆大小
jobmanager.heap.size: 1024m
# TaskManager JVM 堆大小
taskmanager.heap.size: 1024m
# 每个 TaskManager 提供的任务 slots 数量大小
taskmanager.numberOfTaskSlots: 1
# 实际的并行度
parallelism.default: 1
八:环境
(1)下载Flink 注意下载的版本scala版本要和你的代码保持一致
(2)启动Flink : start-cluster.bat
(3)打来Flink的web页面:默认为localhost:8081
(4)准备netcat 启动命令 :nc -L -p 44444
(5)打包项目,上传jar, 添加配置 ,提交 sumit任务
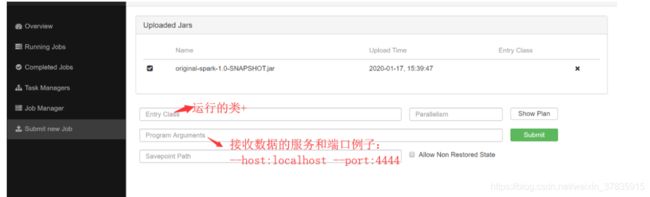
九:运行组件
jobManage
作业管理器,接收要执行的应用程序(job提交的过程)是一个进程
taskManage
任务管理器,也是一个进程,有一个或者多个,每一个taskManage都包含一一定数量的插槽,插槽的数量限制taskManage能够执行的任务数量,启动之后taskmanage 会向资源管理器注册他的插槽,收到资源管理器的指令后,taskmanage就会把一个或者多个插槽提供给jobmanage调用,jobmanage就会向插槽分配任务来执行
resourceManage
资源管理器,负责管理插槽
dispatcher
分发器