Python爬虫--3
1、requests.session()使用
requests模块中的session类能够自动处理发送请求获取响应过程中产生的cookie,进而达到状态保持的目的。
(1)requests.session的作用
自动处理cookie,即下一次请求会带上前一次的cookie。
(2)requests.session的应用场景
自动处理连续的多次请求(get、post等)过程中产生的cookie。
(3)requests.session使用方法
session实例在请求了一个网站后,对方服务器设置在本地的cookie会保存在session中,下一次再使用session请求对方服务器的时候,会带上前一次的cookie;
session = requests.session() # 实例化session对象
url = 'xxxxxxxxxx' # 赋值url
header = {'User-Agent': 'xxxxxxxxxxxx'} # UA伪装
response = session.get(url, headers, ...) # get请求,去得到验证码图片
xxxxx # 解析图片
xxxxx # 构造post携带的数据
response = session.post(url, data, ...) # 登录操作,post账户密码session对象发送get或post请求的参数,与requests模块发送请求的参数完全一致。
2、登录“古诗词网站”、并爬取基于用户的网页数据
模拟登录:
- 爬取基于某些用户的用户信息。
需求:对网站进行模拟登录。
- 点击登录按钮之后会发起一个post请求;post请求中会携带登录之前录入的相关的登录信息 (用户名,密码,验证码......);
- 验证码: 每次请求都会变化;
编码流程:
- 验证码的识别,获取验证码图片的文字数据;
- 对post请求进行发送(处理请求参数);
- 对响应数据进行持久化存储;
(1)网页分析:下面以登录“古诗词网站”为例:
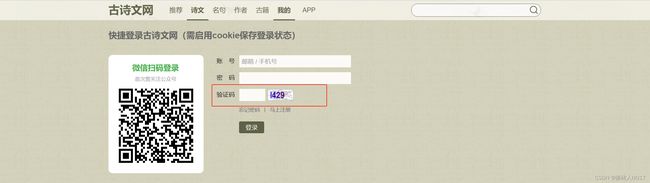
随意输入一个账号、密码、验证码;会出现登录错误。先不要点击“确定”按钮,这时候查看网页源码,发现发起了一个post请求。
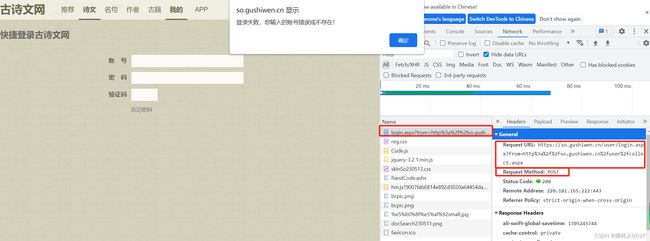
且这个post请求,携带了一批参数数据作为验证使用,
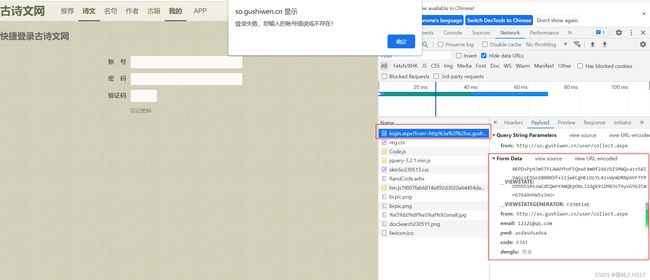
分析post请求携带的参数,如果成功登录的话,form、email、pwd、denglu这些参数都是固定的,只有__VIEWSTATE,__VIEWSTATEGENERATOR和code是三个变量。
参数code(即验证码图片上的数据)的取值为:
参数__VIEWSTATE,__VIEWSTATEGENERATOR的取值为:
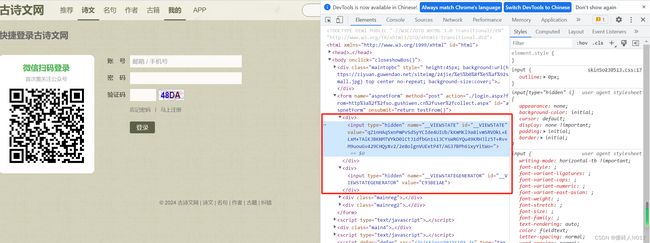
‘__VIEWSTATE’和‘__VIEWSTATEGENERATOR’是在ASP.NET网页中使用的隐藏字段。它们用于在网页间传递状态信息,以便在进行POST请求时保持页面的状态。具体解释如下:
‘__VIEWSTATE’:是一个加密的字符串,用于存储页面的状态信息。它包含了页面上各个控件的值以及其他与页面状态相关的信息。当页面进行POST请求时,服务器会根据该字段的值来还原页面的状态。
‘__VIEWSTATEGENERATOR’:是一个用于生成‘__VIEWSTATE’字段值的标识符。每次页面加载时,服务器会生成一个新的‘__VIEWSTATEGENERATOR’值,并将其与‘__VIEWSTATE’一起返回给客户端。客户端在下次请求时需要将该值一同提交给服务器,以确保服务器能正确解析‘__VIEWSTATE’字段。
在爬虫中,如果要模拟用户进行POST请求,通常需要获取并解析网页中的‘__VIEWSTATE’和‘__VIEWSTATEGENERATOR’字段值,并在后续的请求中将其作为参数传递给服务器,以保持页面的状态。这样可以确保爬虫能够正确地获取到需要的数据。
注意:
我们在获取验证码图片时,用到了一次get请求,最后模拟登陆时,又进行了一次post请求。问题:每一次不同的请求都会导致验证码刷新!!
我们必须用到session = requests.session()来创建一个对话,然后用这个session来进行get请求和post请求,这样就能确保请求是同一个,验证码不会被刷新。并且之后的requests.get和requests.post要换成session.get和session.post。
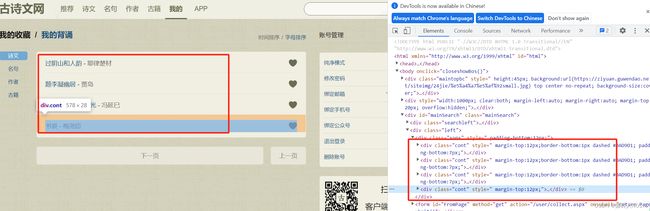
收藏夹中的内容:

代码:
# -*-coding = utf-8-*-
# 数据解析--xpath--验证码登录,并爬取基于用户的数据。
# 网址:https://so.gushiwen.cn
import requests
from lxml import etree
import ddddocr
if __name__ == '__main__' :
# UA伪装
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
# 获得 登录 url
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
# 创建一个session
session = requests.session()
# 爬取页面源码数据
page_text = session.get(url, headers=header).text
# 数据解析, 得到下载界面的页面源码
page_tree = etree.HTML(page_text)
# 解析得到imgcode图片的url
imgcode_url = 'https://so.gushiwen.cn/' + page_tree.xpath('//img[@id="imgCode"]/@src')[0]
print("图片网址:", imgcode_url)
# 用 请求验证码图片 和 模拟登录,避免不同请求的验证码会被刷新
img_bytes = session.get(imgcode_url).content # .content获取二进制
############################################ 对图片处理 ############################################
# 对 ddddocr 进行实例化
ocr = ddddocr.DdddOcr()
# 识别验证码
img_res = ocr.classification(img_bytes)
print("解析出来图片的内容是:", img_res)
############################################ 对图片处理 ############################################
# 获取'__VIEWSTATE'和'__VIEWSTATEGENERATOR'
viewstate = page_tree.xpath('//input[@id="__VIEWSTATE"]/@value')[0]
viewstate_gen = page_tree.xpath('//input[@id="__VIEWSTATEGENERATOR"]/@value')[0]
data = {
'__VIEWSTATE': viewstate,
'__VIEWSTATEGENERATOR': viewstate_gen,
'from': 'http://so.gushiwen.cn/user/collect.aspx',
'email': 'xxxxxx',
'pwd': 'xxxxxx',
'code': img_res,
'denglu': '登录'
}
# 模拟登录
response_post = session.post(url=url, data=data, headers=header)
content_post = response_post.text
print("执行登录后的返回码:", response_post.status_code, "; [200为正确返回值]")
# 保存成功登陆后的页面
with open('temp/yanzhengma-test-1.html', 'w', encoding='utf-8') as f:
f.write(content_post)
# 爬取“我的收藏”中的数据
url = 'https://so.gushiwen.cn/user/collect.aspx'
fp = open('./temp/yanzhengma-test-1.txt', 'wb+')
collect_text = session.get(url=url, headers=header).text
collect_tree = etree.HTML(collect_text)
collects = collect_tree.xpath('//*[@id="mainSearch"]/div[2]/div/div')
for collect in collects :
print(collect)
coll_url = 'https://so.gushiwen.cn' + collect.xpath('./a/@href')[0]
print(coll_url)
coll_text = session.get(url=coll_url, headers=header).text
coll_tree = etree.HTML(coll_text)
coll_name_shi = coll_tree.xpath('//*[@id="sonsyuanwen"]/div[1]/div[2]/h1/text()')[0]
coll_name_ren = coll_tree.xpath('//*[@id="sonsyuanwen"]/div[1]/div[2]/p/a/text()')[1:]
coll_name_txt = coll_tree.xpath('//*[@id="sonsyuanwen"]/div[1]/div[2]/div/text()')
print(coll_name_shi, coll_name_ren, coll_name_txt)
fp.write(coll_name_shi.encode())
for tt in coll_name_ren :
fp.write(tt.encode())
for tt in coll_name_txt :
fp.write(tt.encode())
fp.write(f"\n".encode())
结果为:


