Apache DolphinScheduler:深入了解大数据调度工具
一、海豚调度介绍
Apache DolphinScheduler 是一个分布式易扩展的可视化DAG工作流任务调度开源系统。适用于企业级场景,提供了一个可视化操作任务、工作流和全生命周期数据处理过程的解决方案。
Apache DolphinScheduler 旨在解决复杂的大数据任务依赖关系,并为应用程序提供数据和各种 OPS 编排中的关系。解决数据研发ETL依赖错综复杂,无法监控任务健康状态的问题。DolphinScheduler 以 DAG(Directed Acyclic Graph,DAG)流式方式组装任务,可以及时监控任务的执行状态,支持重试、指定节点恢复失败、暂停、恢复、终止任务等操作。

二、海豚调度特性
简单易用:
可视化 DAG: 用户友好的,通过拖拽定义工作流的,运行时控制工具
模块化操作: 模块化有助于轻松定制和维护。模块化操作: 模块化有助于轻松定制和维护。
丰富的使用场景:
支持多种任务类型: 支持Shell、MR、Spark、SQL等10余种任务类型,支持跨语言,易于扩展
丰富的工作流操作: 工作流程可以定时、暂停、恢复和停止,便于维护和控制全局和本地参数。
High Reliability:
- 高可靠性: 去中心化设计,确保稳定性。原生 HA 任务队列支持,提供过载容错能力。DolphinScheduler 能提供高度稳健的环境。
High Scalability:
- 高扩展性: 支持多租户和在线资源管理。支持每天10万个数据任务的稳定运行。
三、建议配置
操作系统版本要求 服务器建议配置
服务器建议配置 网络要求
网络要求
Apache DolphinScheduler正常运行提供如下的网络端口配置:

客户端Web浏览器要求
Apache DolphinScheduler 推荐 Chrome 以及使用 Chromium 内核的较新版本浏览器访问前端可视化操作界面
四、名词解释
DAG:全称 Directed Acyclic Graph,简称 DAG。工作流中的 Task 任务以有向无环图的形式组装起来,从入度为零的节点进行拓扑遍历,直到无后继节点为止。举例如下图:

流程定义:通过拖拽任务节点并建立任务节点的关联所形成的可视化DAG
流程实例:流程实例是流程定义的实例化,可以通过手动启动或定时调度生成。每运行一次流程定义,产生一个流程实例
任务实例:任务实例是流程定义中任务节点的实例化,标识着某个具体的任务
任务类型:目前支持有 SHELL、SQL、SUB_PROCESS(子流程)、PROCEDURE、MR、SPARK、PYTHON、DEPENDENT(依赖),同时计划支持动态插件扩展,注意:其中 SUB_PROCESS类型的任务需要关联另外一个流程定义,被关联的流程定义是可以单独启动执行的
调度方式:系统支持基于 cron 表达式的定时调度和手动调度。命令类型支持:启动工作流、从当前节点开始执行、恢复被容错的工作流、恢复暂停流程、从失败节点开始执行、补数、定时、重跑、暂停、停止、恢复等待线程。其中 恢复被容错的工作流 和 恢复等待线程 两种命令类型是由调度内部控制使用,外部无法调用
定时调度:系统采用 quartz 分布式调度器,并同时支持cron表达式可视化的生成
依赖:系统不单单支持 DAG 简单的前驱和后继节点之间的依赖,同时还提供任务依赖节点,支持流程间的自定义任务依赖
优先级:支持流程实例和任务实例的优先级,如果流程实例和任务实例的优先级不设置,则默认是先进先出
邮件告警:支持 SQL任务 查询结果邮件发送,流程实例运行结果邮件告警及容错告警通知
失败策略:对于并行运行的任务,如果有任务失败,提供两种失败策略处理方式,继续是指不管并行运行任务的状态,直到流程失败结束。结束是指一旦发现失败任务,则同时Kill掉正在运行的并行任务,流程失败结束
补数:补历史数据,支持区间并行和串行两种补数方式,其日期选择方式包括日期范围和日期枚举两种
五、模块介绍
dolphinscheduler-master master模块,提供工作流管理和编排服务。
dolphinscheduler-worker worker模块,提供任务执行管理服务。
dolphinscheduler-alert 告警模块,提供 AlertServer 服务。
dolphinscheduler-api web应用模块,提供 ApiServer 服务。
dolphinscheduler-common 通用的常量枚举、工具类、数据结构或者基类
dolphinscheduler-dao 提供数据库访问等操作。
dolphinscheduler-remote 基于 netty 的客户端、服务端
dolphinscheduler-service service模块,包含Quartz、Zookeeper、日志客户端访问服务,便于server模块和api模块调用
dolphinscheduler-ui 前端模块
六、功能介绍
1.项目首页
在项目管理页面点击项目名称链接,进入项目首页,如下图所示,项目首页包含该项目的任务状态统计、流程状态统计、工作流定义统计。这几个指标的说明如下
任务状态统计:在指定时间范围内,统计任务实例中状态为提交成功、正在运行、准备暂停、暂停、准备停止、停止、失败、成功、需要容错、kill、等待线程的个数
流程状态统计:在指定时间范围内,统计工作流实例中状态为提交成功、正在运行、准备暂停、暂停、准备停止、停止、失败、成功、需要容错、kill、等待线程的个数
工作流定义统计:统计用户创建的工作流定义及管理员授予该用户的工作流定义

2.工作流定义
创建工作流定义
- 点击项目管理->工作流->工作流定义,进入工作流定义页面,点击“创建工作流”按钮,进入工作流DAG编辑页面,如下图所示:

工具栏中拖拽 到画板中,新增一个Shell任务,如下图所示:

添加Shell任务的参数设置:
填写“节点名称”,“描述”,“脚本”字段;
“运行标志”勾选“正常”,若勾选“禁止执行”,运行工作流不会执行该任务;
选择“任务优先级”:当 worker 线程数不足时,级别高的任务在执行队列中会优先执行,相同优先级的任务按照先进先出的顺序执行;
超时告警(非必选):勾选超时告警、超时失败,填写“超时时长”,当任务执行时间超过超时时长,会发送告警邮件并且任务超时失败;
资源(非必选):资源文件是资源中心->文件管理页面创建或上传的文件,如文件名为 test.sh,脚本中调用资源命令为 sh test.sh。注意调用需要使用资源的全路径;
自定义参数(非必填);
点击"确认添加"按钮,保存任务设置。
配置任务之间的依赖关系:
- 点击任务节点的右侧加号连接任务;如下图所示,任务 Node_B 和任务 Node_C 并行执行,当任务 Node_A 执行完,任务 Node_B、Node_C 会同时执行。

实时任务的依赖关系:
- 若DAG中包含了实时任务的组件,则实时任务的关联关系显示为虚线,在执行工作流实例的时候会跳过实时任务的执行

删除依赖关系:点击右上角"箭头"图标,选中连接线,点击右上角"删除"图标,删除任务间的依赖关系。

保存工作流定义:点击”保存“按钮,弹出"设置DAG图名称"弹框,如下图所示,输入工作流定义名称,工作流定义描述,设置全局参数(选填,参考全局参数),点击"添加"按钮,工作流定义创建成功。

执行策略:
并行:如果对于同一个工作流定义,同时有多个工作流实例,则并行执行工作流实例。
串行等待:如果对于同一个工作流定义,同时有多个工作流实例,则并行执行工作流实例。
串行抛弃:如果对于同一个工作流定义,同时有多个工作流实例,则抛弃后生成的工作流实例并杀掉正在跑的实例。
串行优先:如果对于同一个工作流定义,同时有多个工作流实例,则按照优先级串行执行工作流实例。

工作流定义操作功能
点击项目管理->工作流->工作流定义,进入工作流定义页面,如下图所示:

工作流定义列表的操作功能如下:
编辑:只能编辑"下线"的工作流定义。工作流DAG编辑同创建工作流定义。
上线:工作流状态为"下线"时,上线工作流,只有"上线"状态的工作流能运行,但不能编辑。
下线:工作流状态为"上线"时,下线工作流,下线状态的工作流可以编辑,但不能运行。
运行:只有上线的工作流能运行。运行操作步骤见运行工作流
定时:只有上线的工作流能设置定时,系统自动定时调度工作流运行。创建定时后的状态为"下线",需在定时管理页面上线定时才生效。定时操作步骤见工作流定时
定时管理:定时管理页面可编辑、上线/下线、删除定时。
删除:删除工作流定义。在同一个项目中,只能删除自己创建的工作流定义,其他用户的工作流定义不能进行删除,如果需要删除请联系创建用户或者管理员。
下载:下载工作流定义到本地。
树形图:以树形结构展示任务节点的类型及任务状态,如下图所示:

运**行工作流**:
- 点击项目管理->工作流->工作流定义,进入工作流定义页面,如下图所示,点击"上线"按钮,上线工作流。

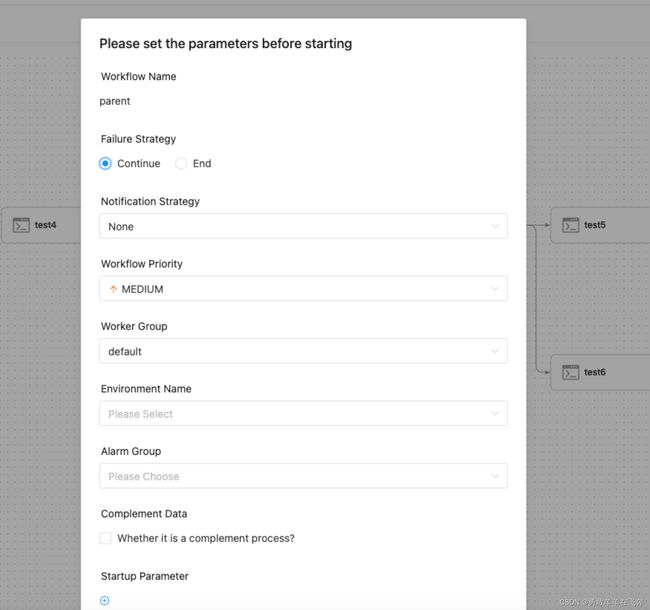
- 点击”运行“按钮,弹出启动参数设置弹框,如下图所示,设置启动参数,点击弹框中的"运行"按钮,工作流开始运行,工作流实例页面生成一条工作流实例。

工作流运行参数说明:
失败策略:当某一个任务节点执行失败时,其他并行的任务节点需要执行的策略。”继续“表示:某一任务失败后,其他任务节点正常执行;”结束“表示:终止所有正在执行的任务,并终止整个流程。
通知策略:当流程结束,根据流程状态发送流程执行信息通知邮件,包含任何状态都不发,成功发,失败发,成功或失败都发。
流程优先级:流程运行的优先级,分五个等级:最高(HIGHEST),高(HIGH),中(MEDIUM),低(LOW),最低(LOWEST)。当 master 线程数不足时,级别高的流程在执行队列中会优先执行,相同优先级的流程按照先进先出的顺序执行。
Worker 分组:该流程只能在指定的 worker 机器组里执行。默认是 Default,可以在任一 worker 上执行。
通知组:选择通知策略||超时报警||发生容错时,会发送流程信息或邮件到通知组里的所有成员。
启动参数: 在启动新的流程实例时,设置或覆盖全局参数的值。
补数:指运行指定日期范围内的工作流定义,根据补数策略生成对应的工作流实例,补数策略包括串行补数、并行补数 2 种模式。
日期可以通过页面选择或者手动输入,日期范围是左关右关区间(startDate <= N <= endDate)
串行补数:指定时间范围内,从开始日期至结束日期依次执行补数,依次生成多条流程实例;点击运行工作流,选择串行补数模式:例如从7月 9号到7月10号依次执行,依次在流程实例页面生成两条流程实例。

并行补数:指定时间范围内,同时进行多天的补数,同时生成多条流程实例。手动输入日期:手动输入以逗号分割日期格式为 yyyy-MM-dd HH:mm:ss 的日期。点击运行工作流,选择并行补数模式:例如同时执行7月9号到7月10号的工作流定义,同时在流程实例页面生成两条流程实例(执行策略为串行时流程实例按照策略执行)。

并行度:是指在并行补数的模式下,最多并行执行的实例数。例如同时执行7月6号到7月10号的工作流定义,并行度为2,那么流程实例为:


依赖模式:是否触发下游依赖节点依赖到当前工作流的工作流实例的补数(要求当前补数的工作流实例的定时状态为已上线,只会触发下游直接依赖到当前工作流的补数)。

日期选择:
通过页面选择日期:

手动输入

补数与定时配置的关系:
未配置定时或已配置定时并定时状态下线:根据所选的时间范围结合定时默认配置(每天0点)进行补数,比如该工作流调度日期为7月7号到7月10号,流程实例为:
已配置定时并定时状态上线:根据所选的时间范围结合定时配置进行补数,比如该工作流调度日期为7月7号到7月10号,配置了定时(每日凌晨5点运行),流程实例为:

 单独运行任务
单独运行任务右键选中任务,点击"启动"按钮(只有已上线的任务才能点击运行)

- 弹出启动参数设置弹框,参数说明同运行工作流
 工作流定时
工作流定时
创建定时:点击项目管理->工作流->工作流定义,进入工作流定义页面,上线工作流,点击"定时"按钮,弹出定时参数设置弹框,如下图所示:

选择起止时间。在起止时间范围内,定时运行工作流;不在起止时间范围内,不再产生定时工作流实例。
添加一个每隔 5 分钟执行一次的定时,如下图所示:

失败策略、通知策略、流程优先级、Worker 分组、通知组、收件人、抄送人同工作流运行参数。
点击"创建"按钮,创建定时成功,此时定时状态为"下线",定时需上线才生效。
定时上线:点击"定时管理"按钮,进入定时管理页面,点击"上线"按钮,定时状态变为"上线",如下图所示,工作流定时生效。

导入工作流
点击项目管理->工作流->工作流定义,进入工作流定义页面,点击"导入工作流"按钮,导入本地工作流文件,工作流定义列表显示导入的工作流,状态为下线。
3.工作流实例
查看工作流实例
点击项目管理->工作流->工作流实例,进入工作流实例页面,如下图所示:

点击工作流名称,进入DAG查看页面,查看任务执行状态,如下图所示。

查看任务日志
进入工作流实例页面,点击工作流名称,进入DAG查看页面,双击任务节点,如下图所示:

点击"查看日志",弹出日志弹框,如下图所示,任务实例页面也可查看任务日志。

查看任务历史记录
点击项目管理->工作流->工作流实例,进入工作流实例页面,点击工作流名称,进入工作流 DAG 页面;
双击任务节点,如下图所示,点击"查看历史",跳转到任务实例页面,并展示该工作流实例运行的任务实例列表

查看运行参数
点击项目管理->工作流->工作流实例,进入工作流实例页面,点击工作流名称,进入工作流 DAG 页面;
点击左上角图标,查看工作流实例的启动参数;点击图标,查看工作流实例的全局参数和局部参数,如下图所示:

工作流实例操作功能*
点击项目管理->工作流->工作流实例,进入工作流实例页面,如下图所示:

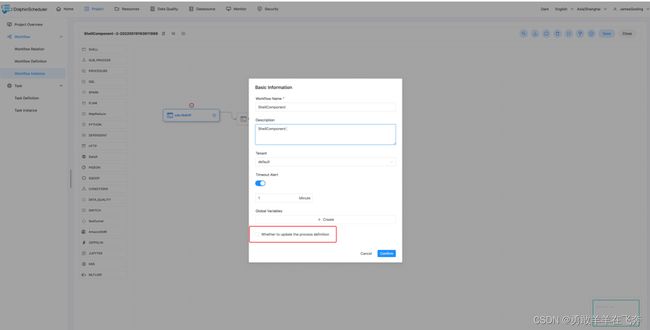
编辑:只能编辑 成功/失败/停止 状态的流程。点击"编辑"按钮或工作流实例名称进入 DAG 编辑页面,编辑后点击"保存"按钮,弹出保存 DAG 弹框,如下图所示,修改流程定义信息,在弹框中勾选"是否更新工作流定义",保存后则将实例修改的信息更新到工作流定义;若不勾选,则不更新工作流定义。
重跑:重新执行已经终止的流程。
恢复失败:针对失败的流程,可以执行恢复失败操作,从失败的节点开始执行。
停止:对正在运行的流程进行停止操作,后台会先 kill worker 进程,再执行 kill -9 操作
暂停:对正在运行的流程进行暂停操作,系统状态变为等待执行,会等待正在执行的任务结束,暂停下一个要执行的任务。
恢复暂停:对暂停的流程恢复,直接从暂停的节点开始运行
删除:删除工作流实例及工作流实例下的任务实例
甘特图:Gantt 图纵轴是某个工作流实例下的任务实例的拓扑排序,横轴是任务实例的运行时间,如图示:

4.任务实例
批量任务实例
- 点击项目管理->工作流->任务实例,进入任务实例页面,如下图所示,点击工作流实例名称,可跳转到工作流实例DAG图查看任务状态。
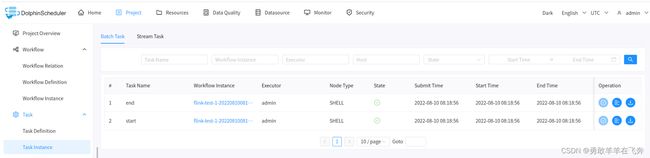
- 查看日志:点击操作列中的“查看日志”按钮,可以查看任务执行的日志情况。

实时任务实例
- 切换到实时任务实例页面,如下图所示:

SavePoint:点击操作列中的SavePoint按钮,可以进行实时任务的SavePoint。
Stop:点击操作列中的Stop按钮,可以停止该实时任务。
5.任务定义
批量任务定**义**
批量任务定义允许您在基于任务级别而不是在工作流中操作修改任务。再此之前,我们已经有了工作流级别的任务编辑器,你可以在工作流定义 单击特定的工作流,然后编辑任务的定义。当您想编辑特定的任务定义但不记得它属于哪个工作流时,这是令人沮丧的。所以我们决定在 任务 菜单下添加 任务定义视图。

在该视图中,您可以通过单击 操作 列中的相关按钮来进行创建、查询、更新、删除任务定义。最令人兴奋的是您可以通过通配符进行全部任务查询,当您只 记得任务名称但忘记它属于哪个工作流时是非常有用的。也支持通过任务名称结合使用 任务类型 或 工作流程名称 进行查询。
实时任务定义
- 实时任务定义在工作流定义中创建,在任务定义页面可以进行修改和执行。
 点击实时任务执行,检查执行参数后点击确认,即可提交实时任务。
点击实时任务执行,检查执行参数后点击确认,即可提交实时任务。

七、任务类型
1.SQL
SQL任务类型,用于连接数据库并执行相应SQL。
创建数据源:
数据源中心支持MySQL、POSTGRESQL、HIVE/IMPALA、SPARK、CLICKHOUSE、ORACLE、SQLSERVER等数据源。
点击"数据源中心->创建数据源",根据需求创建不同类型的数据源
点击"测试连接",测试数据源是否可以连接成功(只有当数据源通过连接性测试后才能保存数据源)。
创建任务:
点击项目管理-项目名称-工作流定义,点击"创建工作流"按钮,进入DAG编辑页面。
工具栏中拖动 到画板中,选择需要连接的数据源,即可完成创建。
任务参数:
sql类型:支持查询和非查询两种。
查询:支持 DML select 类型的命令,是有结果集返回的,可以指定邮件通知为表格、附件或表格附件三种模板;
非查询:支持 DDL全部命令 和 DML update、delete、insert 三种类型的命令;
分段执行符号:提供在数据源不支持一次执行多段SQL语句时,拆分SQL语句的符号来进行多次调用数据源执行方法。例子:1.当数据源选择Hive数据源时,不需要填写此参数。因为Hive数据源本身支持一次执行多段SQL语句;2.当数据源选择MySQL数据源时,并且要执行多段SQL语句时,需要填写此参数为分号 ;。因为MySQL数据源不支持一次执行多段SQL语句;sql参数:输入参数格式为key1=value1;key2=value2…
sql语句:SQL语句
UDF函数:对于HIVE类型的数据源,可以引用资源中心中创建的UDF函数,其他类型的数据源暂不支持UDF函数。
自定义参数:SQL任务类型,而存储过程是自定义参数顺序,给方法设置值自定义参数类型和数据类型,同存储过程任务类型一样。区别在于SQL任务类型自定义参数会替换sql语句中${变量}。
前置sql:前置sql在sql语句之前执行。
后置sql:后置sql在sql语句之后执行。
任务样例
Hive表创建示例
在hive中创建临时表并写入数据
该样例向hive中创建临时表tmp_hello_world并写入一行数据。选择SQL类型为非查询,在创建临时表之前需要确保该表不存在,所以我们使用自定义参数,在每次运行时获取当天时间作为表名后缀,这样这个任务就可以每天运行。创建的表名格式为:tmp_hello_world_{yyyyMMdd}。
 运行该任务成功之后在hive中查询结果
运行该任务成功之后在hive中查询结果
登录集群使用hive命令或使用beeline、JDBC等方式连接apache hive进行查询,查询SQL为select * from tmp_hello_world_{yyyyMMdd},请将{yyyyMMdd}替换为运行当天的日期,查询截图如下:
 使用前置sql和后置sql示例
使用前置sql和后置sql示例
在前置sql中执行建表操作,在sql语句中执行操作,在后置sql中执行清理操作
2.SPARK节点
Spark 任务类型用于执行 Spark 应用。对于 Spark 节点,worker 支持两个不同类型的 spark 命令提交任务:
(1) spark submit 方式提交任务。
(2) spark sql 方式提交任务。
创建任务:
点击项目管理 -> 项目名称 -> 工作流定义,点击”创建工作流”按钮,进入 DAG 编辑页面:
拖动工具栏的 任务节点到画板中。
任务参数:
默认参数说明请参考DolphinScheduler任务参数附录。
程序类型:支持 Java、Scala、Python 和 SQL 四种语言。
Spark 版本:支持 Spark1 和 Spark2。
主函数的 Class:Spark 程序的入口 Main class 的全路径。
主程序包:执行 Spark 程序的 jar 包(通过资源中心上传)。
SQL脚本:Spark sql 运行的 .sql 文件中的 SQL 语句。
部署方式:(1) spark submit 支持 yarn-clusetr、yarn-client 和 local 三种模式。(2) spark sql 支持 yarn-client 和 local 两种模式。
任务名称(可选):Spark 程序的名称。
Driver 核心数:用于设置 Driver 内核数,可根据实际生产环境设置对应的核心数。
Driver 内存数:用于设置 Driver 内存数,可根据实际生产环境设置对应的内存数。
Executor 数量:用于设置 Executor 的数量,可根据实际生产环境设置对应的内存数。
Executor 内存数:用于设置 Executor 内存数,可根据实际生产环境设置对应的内存数。
主程序参数:设置 Spark 程序的输入参数,支持自定义参数变量的替换。
选项参数:支持 --jar、–files、–archives、–conf 格式。
资源:如果其他参数中引用了资源文件,需要在资源中选择指定。
自定义参数:是 Spark 局部的用户自定义参数,会替换脚本中以 ${变量} 的内容。
任务样例
spark submit
执行 WordCount 程序
本案例为大数据生态中常见的入门案例,常应用于 MapReduce、Flink、Spark 等计算框架。主要为统计输入的文本中,相同的单词的数量有多少。
在 DolphinScheduler 中配置 Spark 环境
若生产环境中要是使用到 Spark 任务类型,则需要先配置好所需的环境。配置文件如下:bin/env/dolphinscheduler_env.sh。
 上传主程序包
上传主程序包
在使用 Spark 任务节点时,需要利用资源中心上传执行程序的 jar 包。
当配置完成资源中心之后,直接使用拖拽的方式,即可上传所需目标文件。
 配置 Spark 节点
配置 Spark 节点
根据上述参数说明,配置所需的内容即可。 spark sql
spark sql
执行 DDL 和 DML 语句
本案例为创建一个视图表 terms 并写入三行数据和一个格式为 parquet 的表 wc 并判断该表是否存在。程序类型为 SQL。将视图表 terms 的数据插入到格式为 parquet 的表 wc。
注意:
JAVA 和 Scala 只用于标识,使用 Spark 任务时没有区别。如果应用程序是由 Python 开发的,那么可以忽略表单中的参数Main Class。参数SQL脚本仅适用于 SQL 类型,在 JAVA、Scala 和 Python 中可以忽略。
SQL 目前不支持 cluster 模式。
3.Apache Zeppelin
Zeppelin任务类型,用于创建并执行Zeppelin类型任务。worker 执行该任务的时候,会通过Zeppelin Cient API触发Zeppelin Notebook Paragraph。
创建任务
点击项目管理-项目名称-工作流定义,点击"创建工作流"按钮,进入DAG编辑页面。
工具栏中拖动 到画板中,即可完成创建。
任务参数
 生产(克隆)模式
生产(克隆)模式
填上Zeppelin Production Note Directory参数以启动生产模式。
在生产模式下,目标note会被克隆到您所填的Zeppelin Production Note Directory目录下。Zeppelin任务插件将会执行克隆出来的note并在执行成功后自动清除它。因为在此模式下,如果您不小心修改了正在被Dolphin Scheduler调度的note,也不会影响到生产任务的执行, 从而提高了稳定性。
如果您选择不填Zeppelin Production Note Directory这个参数,Zeppelin任务插件将会执行您的原始note。'Zeppelin Production Note Directory’参数在格式上应该以斜杠开头和结尾,例如 /production_note_directory/。
任务样例
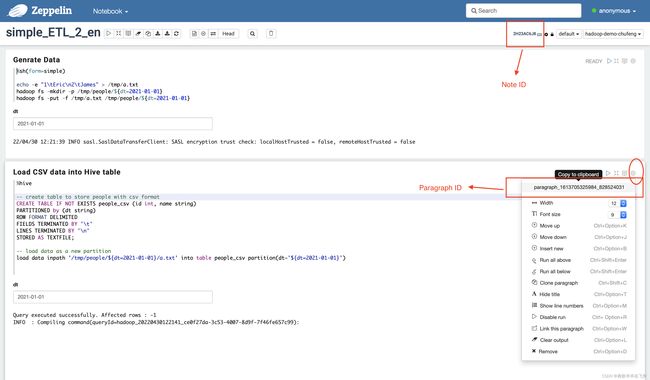
Zeppelin Paragraph 任务样例
这个示例展示了如何创建Zeppelin Paragraph任务节点:
八、集群部署
集群部署目的是在多台机器部署 DolphinScheduler 服务,用于运行大量任务情况。
集群部署(Cluster)使用的脚本和配置文件与伪集群部署中的配置一样,所以所需要的步骤也与伪集群部署大致一样。区别就是伪集群部署针对的是一台机器,而集群部署(Cluster)需要针对多台机器,且两者“修改相关配置”步骤区别较大
1.前置准备工作
JDK:下载JDK (1.8+),安装并配置 JAVA_HOME 环境变量,并将其下的 bin 目录追加到 PATH 环境变量中。如果你的环境中已存在,可以跳过这步。
二进制包:在下载页面下载 DolphinScheduler 二进制包
数据库:PostgreSQL (8.2.15+) 或者 MySQL (5.7+),两者任选其一即可,如 MySQL 则需要 JDBC Driver 8.0.16
注册中心:ZooKeeper (3.4.6+),下载地址
进程树分析
macOS安装pstree
Fedora/Red/Hat/CentOS/Ubuntu/Debian安装psmisc
注意: DolphinScheduler 本身不依赖 Hadoop、Hive、Spark,但如果你运行的任务需要依赖他们,就需要有对应的环境支持
2.准备 DolphinScheduler 启动环境
配置用户免密及权限
创建部署用户,并且一定要配置 sudo 免密。以创建 dolphinscheduler 用户为例
# 创建用户需使用 root 登录配置机器SSH免密登陆
由于安装的时候需要向不同机器发送资源,所以要求各台机器间能实现SSH免密登陆。配置免密登陆的步骤如下
su dolphinscheduler注意: 配置完成后,可以通过运行命令 ssh localhost 判断是否成功,如果不需要输入密码就能ssh登陆则证明成功
启动zookeeper
进入 zookeeper 的安装目录,将 zoo_sample.cfg 配置文件复制到 conf/zoo.cfg,并将 conf/zoo.cfg 中 dataDir 中的值改成 dataDir=./tmp/zookeeper
# 启动 zookeeper3.修改相关配置
完成基础环境的准备后,需要根据你的机器环境修改配置文件。配置文件可以在目录 bin/env 中找到,他们分别是 并命名为 install_env.sh 和 dolphinscheduler_env.sh。
修改 install_env.sh 文件
文件 install_env.sh 描述了哪些机器将被安装 DolphinScheduler 以及每台机器对应安装哪些服务。您可以在路径 bin/env/install_env.sh 中找到此文件,可通过以下方式更改env变量,export =,配置详情如下。
# ---------------------------------------------------------修改 dolphinscheduler_env.sh 文件
文件 ./bin/env/dolphinscheduler_env.sh 描述了下列配置:
DolphinScheduler 的数据库配置,详细配置方法见初始化数据库
一些任务类型外部依赖路径或库文件,如 JAVA_HOME 和 SPARK_HOME都是在这里定义的
注册中心zookeeper
服务端相关配置,比如缓存,时区设置等
如果您不使用某些任务类型,您可以忽略任务外部依赖项,但您必须根据您的环境更改 JAVA_HOME、注册中心和数据库相关配置。
# JAVA_HOME, will use it to start DolphinScheduler server这个是与伪集群部署差异较大的一步,因为部署脚本会通过 scp 的方式将安装需要的资源传输到各个机器上,所以这一步我们仅需要修改运行install.sh脚本的所在机器的配置即可。配置文件在路径在bin/env/install_env.sh下,此处我们仅需修改INSTALL MACHINE,DolphinScheduler ENV、Database、Registry Server与伪集群部署保持一致,下面对必须修改参数进行说明
# ---------------------------------------------------------4.初始化数据库
启动 DolphinScheduler
使用上面创建的部署用户运行以下命令完成部署,部署后的运行日志将存放在 logs 文件夹内
bash ./bin/install.sh5.登陆DolphinScheduler
启停服务
# 一键停止集群所有服务注意1:: 每个服务在路径 /conf/dolphinscheduler\_env.sh 中都有 dolphinscheduler\_env.sh 文件,这是可以为微 服务需求提供便利。意味着您可以基于不同的环境变量来启动各个服务,只需要在对应服务中配置 /conf/dolphinscheduler\_env.sh 然后通过 /bin/start.sh 命令启动即可。但是如果您使用命令 /bin/dolphinscheduler-daemon.sh start 启动服务器,它将会用文件 bin/env/dolphinscheduler\_env.sh 覆盖 /conf/dolphinscheduler_env.sh 然后启动服务,目的是为了减少用户修改配置的成本.
注意2::服务用途请具体参见《系统架构设计》小节。Python gateway service 默认与 api-server 一起启动,如果您不想启动 Python gateway service 请通过更改 api-server 配置文件 api-server/conf/application.yaml 中的 python-gateway.enabled : false 来禁用它。
九、架构设计
1.DolphinScheduler 元数据文档
一个租户下可以有多个用户;
一个用户可以有多个项目
一个项目可以有多个工作流定义,每个工作流定义只属于一个项目;
一个租户可以被多个工作流定义使用,每个工作流定义必须且只能选择一个租户;
一个工作流定义可以有一个或多个定时的配置;
一个工作流定义对应多个任务定义
一个工作流定义可以有多个工作流实例,一个工作流实例对应一个或多个任务实例
2.架构设计
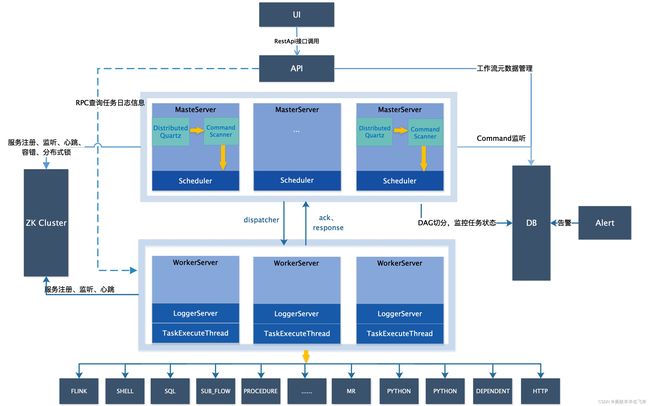
架构说明
MasterServer
- MasterServer采用分布式无中心设计理念,MasterServer主要负责 DAG 任务切分、任务提交监控,并同时监听其它MasterServer和WorkerServer的健康状态。MasterServer服务启动时向Zookeeper注册临时节点,通过监听Zookeeper临时节点变化来进行容错处理。MasterServer基于netty提供监听服务。
该服务内主要包含:
DistributedQuartz分布式调度组件,主要负责定时任务的启停操作,当quartz调起任务后,Master内部会有线程池具体负责处理任务的后续操作;
MasterSchedulerService是一个扫描线程,定时扫描数据库中的t\_ds\_command表,根据不同的命令类型进行不同的业务操作;
WorkflowExecuteRunnable主要是负责DAG任务切分、任务提交监控、各种不同事件类型的逻辑处理;
TaskExecuteRunnable主要负责任务的处理和持久化,并生成任务事件提交到工作流的事件队列;
EventExecuteService主要负责工作流实例的事件队列的轮询;
StateWheelExecuteThread主要负责工作流和任务超时、任务重试、任务依赖的轮询,并生成对应的工作流或任务事件提交到工作流的事件队列;
FailoverExecuteThread主要负责Master容错和Worker容错的相关逻辑;
WorkerServer:
WorkerServer也采用分布式无中心设计理念,WorkerServer主要负责任务的执行和提供日志服务。WorkerServer服务启动时向Zookeeper注册临时节点,并维持心跳。WorkerServer基于netty提供监听服务。
该服务包含:
WorkerManagerThread主要负责任务队列的提交,不断从任务队列中领取任务,提交到线程池处理;
TaskExecuteThread主要负责任务执行的流程,根据不同的任务类型进行任务的实际处理;
RetryReportTaskStatusThread主要负责定时轮询向Master汇报任务的状态,直到Master回复状态的ack,避免任务状态丢失;
ZooKeeper:
- ZooKeeper服务,系统中的MasterServer和WorkerServer节点都通过ZooKeeper来进行集群管理和容错。另外系统还基于ZooKeeper进行事件监听和分布式锁。我们也曾经基于Redis实现过队列,不过我们希望DolphinScheduler依赖到的组件尽量地少,所以最后还是去掉了Redis实现。
AlertServer:
- 提供告警服务,通过告警插件的方式实现丰富的告警手段。
ApiServer:
- API接口层,主要负责处理前端UI层的请求。该服务统一提供RESTful api向外部提供请求服务。
UI:
- 系统的前端页面,提供系统的各种可视化操作界面。
3.架构设计思想
去中心化vs中心化
中心化思想
中心化的设计理念比较简单,分布式集群中的节点按照角色分工,大体上分为两种角色:

Master的角色主要负责任务分发并监督Slave的健康状态,可以动态的将任务均衡到Slave上,以致Slave节点不至于“忙死”或”闲死”的状态。
Worker的角色主要负责任务的执行工作并维护和Master的心跳,以便Master可以分配任务给Slave。
中心化思想设计存在的问题:
一旦Master出现了问题,则群龙无首,整个集群就会崩溃。为了解决这个问题,大多数Master/Slave架构模式都采用了主备Master的设计方案,可以是热备或者冷备,也可以是自动切换或手动切换,而且越来越多的新系统都开始具备自动选举切换Master的能力,以提升系统的可用性。
另外一个问题是如果Scheduler在Master上,虽然可以支持一个DAG中不同的任务运行在不同的机器上,但是会产生Master的过负载。如果Scheduler在Slave上,则一个DAG中所有的任务都只能在某一台机器上进行作业提交,则并行任务比较多的时候,Slave的压力可能会比较大。
去中心化: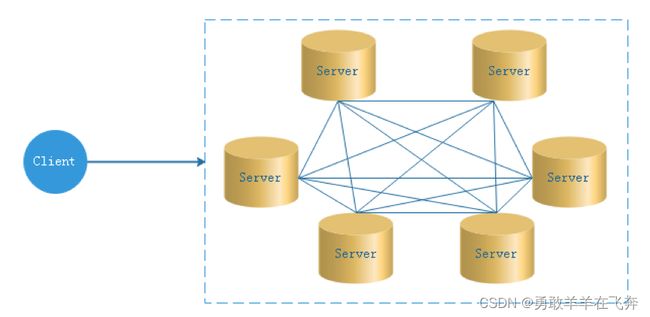
在去中心化设计里,通常没有Master/Slave的概念,所有的角色都是一样的,地位是平等的,全球互联网就是一个典型的去中心化的分布式系统,联网的任意节点设备down机,都只会影响很小范围的功能。
去中心化设计的核心设计在于整个分布式系统中不存在一个区别于其他节点的”管理者”,因此不存在单点故障问题。但由于不存在” 管理者”节点所以每个节点都需要跟其他节点通信才得到必须要的机器信息,而分布式系统通信的不可靠性,则大大增加了上述功能的实现难度。
实际上,真正去中心化的分布式系统并不多见。反而动态中心化分布式系统正在不断涌出。在这种架构下,集群中的管理者是被动态选择出来的,而不是预置的,并且集群在发生故障的时候,集群的节点会自发的举行"会议"来选举新的"管理者"去主持工作。最典型的案例就是ZooKeeper及Go语言实现的Etcd。
DolphinScheduler的去中心化是Master/Worker注册心跳到Zookeeper中,Master基于slot处理各自的Command,通过selector分发任务给worker,实现Master集群和Worker集群无中心。
4.容错设计
容错分为服务宕机容错和任务重试,服务宕机容错又分为Master容错和Worker容错两种情况
宕机容错
服务容错设计依赖于ZooKeeper的Watcher机制,实现原理如图: 其中Master监控其他Master和Worker的目录,如果监听到remove事件,则会根据具体的业务逻辑进行流程实例容错或者任务实例容错。
其中Master监控其他Master和Worker的目录,如果监听到remove事件,则会根据具体的业务逻辑进行流程实例容错或者任务实例容错。
- Master容错流程:
 容错范围:从host的维度来看,Master的容错范围包括:自身host+注册中心上不存在的节点host,容错的整个过程会加锁;
容错范围:从host的维度来看,Master的容错范围包括:自身host+注册中心上不存在的节点host,容错的整个过程会加锁;
容错内容:Master的容错内容包括:容错工作流实例和任务实例,在容错前会比较实例的开始时间和服务节点的启动时间,在服务启动时间之后的则跳过容错;
容错后处理:ZooKeeper Master容错完成之后则重新由DolphinScheduler中Scheduler线程调度,遍历 DAG 找到”正在运行”和“提交成功”的任务,对”正在运行”的任务监控其任务实例的状态,对”提交成功”的任务需要判断Task Queue中是否已经存在,如果存在则同样监控任务实例的状态,如果不存在则重新提交任务实例。
Worker容错流程:
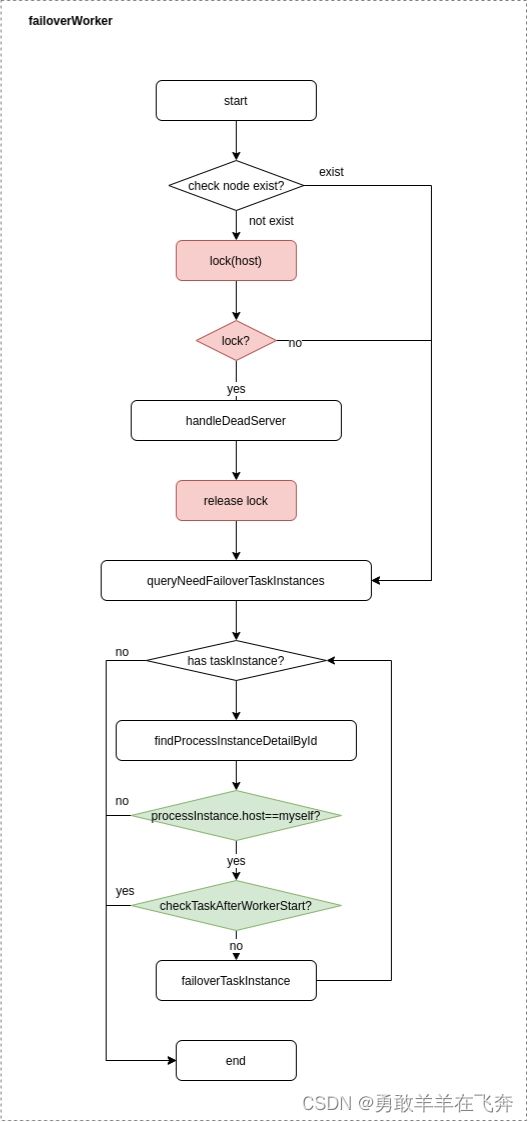
容错范围:从工作流实例的维度看,每个Master只负责容错自己的工作流实例;只有在handleDeadServer时会加锁;
容错内容:当发送Worker节点的remove事件时,Master只容错任务实例,在容错前会比较实例的开始时间和服务节点的启动时间,在服务启动时间之后的则跳过容错;
容错后处理:Master Scheduler线程一旦发现任务实例为” 需要容错”状态,则接管任务并进行重新提交。
注意:由于” 网络抖动”可能会使得节点短时间内失去和ZooKeeper的心跳,从而发生节点的remove事件。对于这种情况,我们使用最简单的方式,那就是节点一旦和ZooKeeper发生超时连接,则直接将Master或Worker服务停掉。
5.任务失败重试
这里首先要区分任务失败重试、流程失败恢复、流程失败重跑的概念:
任务失败重试是任务级别的,是调度系统自动进行的,比如一个Shell任务设置重试次数为3次,那么在Shell任务运行失败后会自己再最多尝试运行3次
流程失败恢复是流程级别的,是手动进行的,恢复是从只能从失败的节点开始执行或从当前节点开始执行
流程失败重跑也是流程级别的,是手动进行的,重跑是从开始节点进行
接下来说正题,我们将工作流中的任务节点分了两种类型。
一种是业务节点,这种节点都对应一个实际的脚本或者处理语句,比如Shell节点、SQL节点、Spark节点等。
还有一种是逻辑节点,这种节点不做实际的脚本或语句处理,只是整个流程流转的逻辑处理,比如依赖节点、子流程节点等。
业务节点都可以配置失败重试的次数,当该任务节点失败,会自动重试,直到成功或者超过配置的重试次数。逻辑节点不支持失败重试。
如果工作流中有任务失败达到最大重试次数,工作流就会失败停止,失败的工作流可以手动进行重跑操作或者流程恢复操作。
6.任务优先级设计
在早期调度设计中,如果没有优先级设计,采用公平调度设计的话,会遇到先行提交的任务可能会和后继提交的任务同时完成的情况,而不能做到设置流程或者任务的优先级,因此我们对此进行了重新设计,目前我们设计如下:
按照不同流程实例优先级优先于同一个流程实例优先级优先于同一流程内任务优先级优先于同一流程内任务提交顺序依次从高到低进行任务处理。
具体实现是根据任务实例的json解析优先级,然后把流程实例优先级_流程实例id_任务优先级_任务id信息保存在ZooKeeper任务队列中,当从任务队列获取的时候,通过字符串比较即可得出最需要优先执行的任务
其中流程定义的优先级是考虑到有些流程需要先于其他流程进行处理,这个可以在流程启动或者定时启动时配置,共有5级,依次为HIGHEST、HIGH、MEDIUM、LOW、LOWEST。如下图

任务的优先级也分为5级,依次为HIGHEST、HIGH、MEDIUM、LOW、LOWEST。如下图

7.Logback和netty实现日志访问
由于Web(UI)和Worker不一定在同一台机器上,所以查看日志不能像查询本地文件那样。有两种方案:
将日志放到ES搜索引擎上
通过netty通信获取远程日志信息
介于考虑到尽可能的DolphinScheduler的轻量级性,所以选择了gRPC实现远程访问日志信息。

详情可参考Master和Worker的logback配置,如下示例:
8.配置文件详解
dolphinscheduler-daemon.sh \[启动/关闭DolphinScheduler服务脚本\]
dolphinscheduler-daemon.sh脚本负责DolphinScheduler的启动&关闭. start-all.sh/stop-all.sh最终也是通过dolphinscheduler-daemon.sh对集群进行启动/关闭操作. 目前DolphinScheduler只是做了一个基本的设置,JVM参数请根据各自资源的实际情况自行设置。
默认简化参数如下:
export DOLPHINSCHEDULER_OPTS="9.负载均衡
负载均衡即通过路由算法(通常是集群环境),合理的分摊服务器压力,达到服务器性能的最大优化。
DolphinScheduler-Worker 负载均衡算法
DolphinScheduler-Master 分配任务至 worker,默认提供了三种算法:
加权随机(random)
平滑轮询(roundrobin)
线性负载(lowerweight)
默认配置为线性加权负载。
由于路由是在客户端做的,即 master 服务,因此你可以更改 master.properties 中的 master.host.selector 来配置你所想要的算法。
eg:master.host.selector=random(不区分大小写)
Worker 负载均衡配置
配置文件 worker.properties
权重
上述所有的负载算法都是基于权重来进行加权分配的,权重影响分流结果。你可以在 修改 worker.weight 的值来给不同的机器设置不同的权重。
预热
考虑到 JIT 优化,我们会让 worker 在启动后低功率的运行一段时间,使其逐渐达到最佳状态,这段过程我们称之为预热。感兴趣的同学可以去阅读 JIT 相关的文章。
因此 worker 在启动后,他的权重会随着时间逐渐达到最大(默认十分钟)。
负载均衡算法细述
随机(加权)
- 该算法比较简单,即在符合的 worker 中随机选取一台(权重会影响他的比重)。
平滑轮询(加权)
- 加权轮询算法一个明显的缺陷。即在某些特殊的权重下,加权轮询调度会生成不均匀的实例序列,这种不平滑的负载可能会使某些实例出现瞬时高负载的现象,导致系统存在宕机的风险。为了解决这个调度缺陷,我们提供了平滑加权轮询算法。
每台 worker 都有两个权重,即 weight(预热完成后保持不变),current\_weight(动态变化),每次路由。都会遍历所有的 worker,使其 current\_weight+weight,同时累加所有 worker 的 weight,计为 total\_weight,然后挑选 current\_weight 最大的作为本次执行任务的 worker,与此同时,将这台 worker 的 current\_weight-total\_weight。
线性加权(默认算法)
该算法每隔一段时间会向注册中心上报自己的负载信息。我们主要根据两个信息来进行判断
load 平均值(默认是 CPU 核数 *2)
可用物理内存(默认是 0.3,单位是 G)
如果两者任何一个低于配置项,那么这台 worker 将不参与负载。(即不分配流量)
你可以在 worker.properties 修改下面的属性来自定义配置:
worker.max.cpuload.avg=-1 (worker最大cpuload均值,只有高于系统cpuload均值时,worker服务才能被派发任务. 默认值为-1: cpu cores * 2)
worker.reserved.memory=0.3 (worker预留内存,只有低于系统可用内存时,worker服务才能被派发任务,单位为G)
10.缓存
缓存目的
由于在master-server调度过程中,会产生大量的数据库读取操作,如tenant,user,processDefinition等,一方面对DB产生很大的读压力,另一方面则会使整个核心调度流程变得缓慢;
考虑到这部分业务数据是读多写少的场景,故引入了缓存模块,以减少DB读压力,加快核心调度流程;
缓存设置
spring:缓存模块采用spring-cache机制,可直接在spring配置文件中配置是否开启缓存(默认none关闭), 缓存类型;
目前采用caffeine进行缓存管理,可自由设置缓存相关配置,如缓存大小、过期时间等;
缓存读取
缓存采用spring-cache的注解,配置在相关的mapper层,可参考如:TenantMapper.
缓存更新
业务数据的更新来自于api-server, 而缓存端在master-server, 故需要对api-server的数据更新做监听(aspect切面拦截@CacheEvict),当需要进行缓存驱逐时会通知master-server,master-server接收到cacheEvictCommand后进行缓存驱逐;
十、API调用
一般都是通过页面来创建项目、流程等,但是与第三方系统集成就需要通过调用 API 来管理项目、流程。
创建 token
- 登录调度系统,点击 “安全中心”,再点击左侧的 “令牌管理”,点击 “令牌管理” 创建令牌。

- 选择 “失效时间” (Token 有效期),选择 “用户” (以指定的用户执行接口操作),点击 “生成令牌” ,拷贝 Token 字符串,然后点击 “提交” 。

使用案例
查询项目列表信息
- 打开 API 文档页面
地址:http://{api server ip}:12345/dolphinscheduler/swagger-ui/index.html?language=zh_CN&lang=cn
- 选一个测试的接口,本次测试选取的接口是:查询所有项目
projects/list- 打开 Postman,填写接口地址,并在 Headers 中填写 Token,发送请求后即可查看结果
token: 刚刚生成的 Token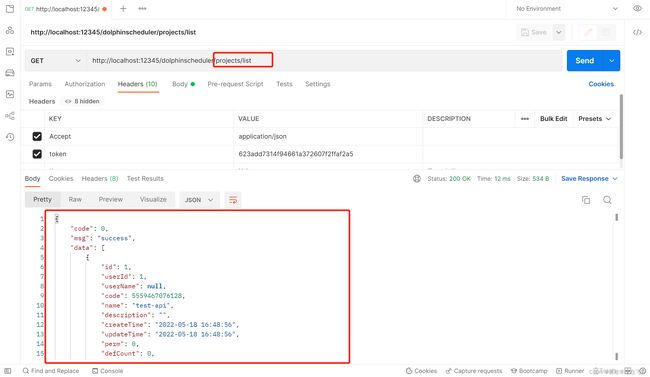
创建项目
这里演示如何使用调用 api 来创建对应的项目。
通过查阅 api 文档,在 Postman 的 Headers 中配置 KEY 为 Accept,VALUE 为 application/json 的参数。

然后再 Body 中配置所需的 projectName 和 description 参数。

检查 post 请求结果。
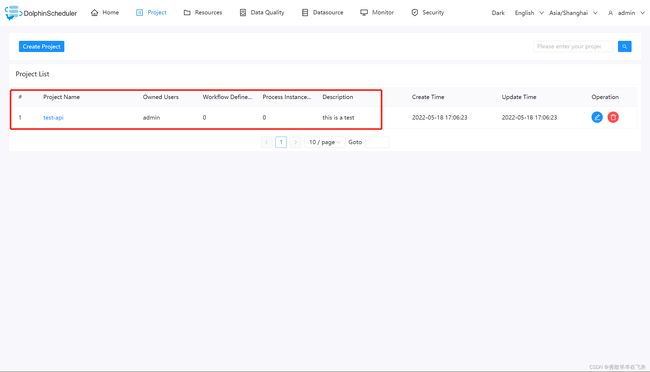
返回 msg 信息为 “success”,说明我们已经成功通过 API 的方式创建了项目。
本文由 白鲸开源科技 提供发布支持!