大数据毕业设计:商品评论数据情感分析系统 可视化 snownlp情感分析 机器学习 Django框架(源码) ✅
毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。
1、项目介绍
技术栈:
Python语言、Django框架、Echarts可视化、snownlp情感分析、机器学习、html js css
电商评论数据情感分析可视化系统是基于Python语言和Django框架开发的一款系统。该系统主要用于对电商平台上的用户评论数据进行情感分析,并通过Echarts可视化工具将分析结果以图表形式展示出来。
2、项目界面
(1)评论数据可视化分析
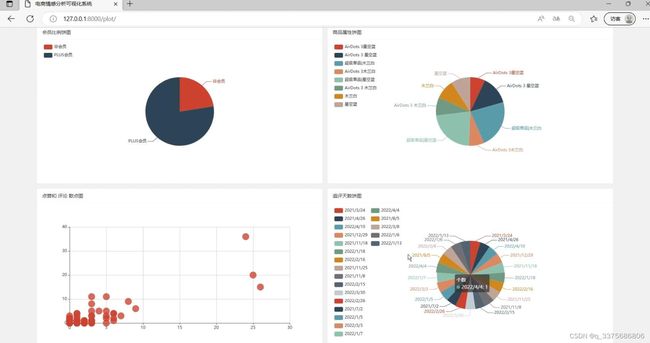
(2)评论数据情感分析
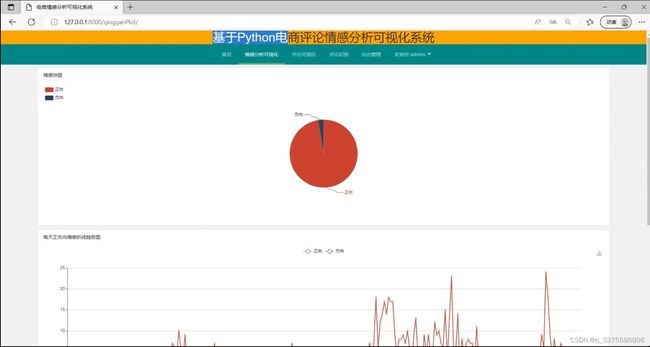
(3)评论数据
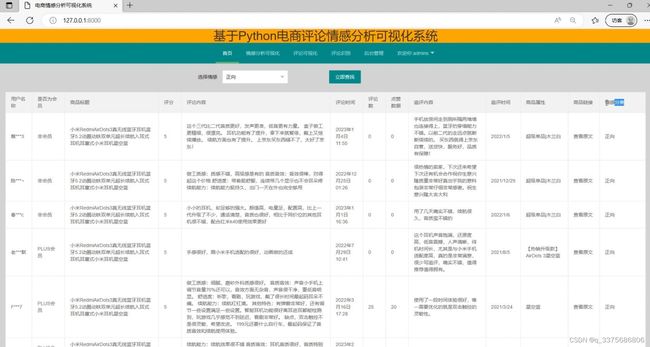
(4)评论数据情感分析

(5)注册登录界面
(6)后台数据管理
3、项目说明
电商评论数据情感分析可视化系统是基于Python语言和Django框架开发的一款系统。该系统主要用于对电商平台上的用户评论数据进行情感分析,并通过Echarts可视化工具将分析结果以图表形式展示出来。
系统的主要功能包括:
- 数据采集:系统可以通过爬虫技术从电商平台上抓取用户评论数据,并进行清洗和预处理。
- 情感分析:系统使用snownlp情感分析库对用户评论数据进行情感分析,判断评论的情绪倾向(积极、中性、消极)。
- 数据可视化:系统利用Echarts可视化工具将情感分析结果以图表形式展示出来,如柱状图、折线图等,便于用户直观地了解评论情感的分布和趋势。
- 机器学习:系统还可以利用机器学习算法对评论数据进行分类和预测,从而更准确地判断评论的情感倾向。
此外,系统还包括用户管理、权限控制、数据存储等基本功能,以保证系统的稳定运行和数据安全。
在前端方面,系统使用html、js、css等技术实现用户界面的设计和交互操作,使用户能够方便地使用系统,并对可视化结果进行自定义和导出。
总体而言,电商评论数据情感分析可视化系统具有数据分析、可视化展示和机器学习等多个功能,可以帮助电商平台对用户评论数据进行深入分析和挖掘,从而提升用户体验和改进产品服务。
4、核心代码
import datetime
import os.path
import jieba
import joblib
import pandas as pd
from django.http import JsonResponse
from django.shortcuts import render, redirect, HttpResponse
from django.utils.decorators import method_decorator
from django.views import View
from snownlp import SnowNLP
from tqdm import tqdm
from app.models import *
# 验证登录
def check_login(func):
def wrapper(request):
# print("装饰器验证登录")
cookie = request.COOKIES.get('uid')
if not cookie:
return redirect('/login/')
else:
return func(request)
return wrapper
# 加载数据到数据库中 并且对数据进行一定的清洗
def data2mysql(request):
raw_json = pd.read_csv(os.path.join('data','小米Redmi耳机.csv'))
raw_json = raw_json.dropna(subset=['评价内容']) # 去空 评论为空的删除
print(raw_json.columns)
for i in tqdm(range(len(raw_json))):
name = raw_json.iloc[i]['会员']
content = raw_json.iloc[i]['评价内容']
goodAttr = raw_json.iloc[i]['商品属性'] #
url = raw_json.iloc[i]['页面网址'] #
title = raw_json.iloc[i]['页面标题'] #
# 需要处理的数据
isvip = raw_json.iloc[i]['级别']
isvip = str(isvip)
isvip = '非会员' if isvip == 'nan' else isvip
star = raw_json.iloc[i]['评价星级']
star = int(star.replace('star',''))
time = raw_json.iloc[i]['时间']
agree = raw_json.iloc[i]['点赞数'] #
agree = int(agree)
comNum = raw_json.iloc[i]['评论数'] #
comNum = int(comNum)
zhuiping = raw_json.iloc[i]['追评内容'] #追评内容
zhuiping = str(zhuiping)
if zhuiping == 'nan':
zhuiping = ''
zhuipingtime = raw_json.iloc[i]['追评时间'] #
zhuipingtime = str(zhuipingtime)
if zhuipingtime != 'nan':
zhuipingtime = zhuipingtime.split('天')[0][3:]
zhuipingtime = int(zhuipingtime)
else:
zhuipingtime = None
if not Comment.objects.filter(name=name,isvip=isvip,star=star,content=content,time=time,
agree=agree,comNum=comNum,
zhuiping=zhuiping,zhuipingtime=zhuipingtime,goodAttr=goodAttr,
url=url,title=title):
Comment.objects.create(name=name, isvip=isvip, star=star, content=content, time=time,
agree=agree, comNum=comNum,
zhuiping=zhuiping, zhuipingtime=zhuipingtime, goodAttr=goodAttr,
url=url, title=title)
return JsonResponse({'status':1,'msg':'操作成功'} )
###首页
@check_login
def index(request):
##进入系统初期,如果数据中存在未识别的 就识别
model_4 = joblib.load('model_4.pkl')
vectorizer = joblib.load('vectorizer.pkl')
for i in Comment.objects.filter(emotion=''): # filter(emotion='')
test_vec = vectorizer.transform([i.content])
emotion = model_4.predict(test_vec)[0]
emotion = '正向' if emotion == 1 else '负向'
s = SnowNLP(i.content).sentiments
emotion = '正向' if s >0.2 else '负向'
Comment.objects.filter(id=i.id).update(emotion=emotion)
raw_data = Comment.objects.all()
# le类别列表
sentiment_list = ['正向','负向']
# yon用户信息
uid = int(request.COOKIES.get('uid', -1))
if uid != -1:
username = User.objects.filter(id=uid)[0].name
# 得到类别
if 'key' not in request.GET:
key = sentiment_list[0]
raw_data = raw_data.filter(emotion=key)
else:
key = request.GET.get('key')
raw_data = raw_data.filter(emotion=key)
# 分页
if 'page' not in request.GET:
page = 1
else:
page = int(request.GET.get('page'))
data_list = raw_data[(page-1)*20 : page*20 ]
return render(request, 'index.html', locals())
# 情感分类
def fenlei(request):
content = request.POST.get('content')
# yon用户信息
uid = int(request.COOKIES.get('uid', -1))
if uid != -1:
username = User.objects.filter(id=uid)[0].name
model_4 = joblib.load('model_4.pkl')
vectorizer = joblib.load('vectorizer.pkl')
test_vec = vectorizer.transform([content])
emotion = model_4.predict(test_vec)[0]
emotion = '正向' if emotion == 1 else '负向'
s = SnowNLP(content).sentiments
emotion = '正向' if s > 0.2 else '负向'
now_time = datetime.datetime.now() # 日期对象
now_str = datetime.datetime.strftime(now_time, '%Y-%m-%d') # 日期字符串
Shibie.objects.create(user_id=uid,content=content,sentiment=emotion,date=now_time)
return JsonResponse({'status':1,'label':emotion} )
#####################################################下面可能是没用的
# 登录
def login(request):
if request.method == "POST":
tel, pwd = request.POST.get('tel'), request.POST.get('pwd')
if User.objects.filter(tel=tel, password=pwd):
obj = redirect('/')
obj.set_cookie('uid', User.objects.filter(tel=tel, password=pwd)[0].id, max_age=60 * 60 * 24)
return obj
else:
msg = "用户信息错误,请重新输入!!"
return render(request, 'login.html', locals())
else:
return render(request, 'login.html', locals())
# 注册
def register(request):
if request.method == "POST":
name, tel, pwd = request.POST.get('name'), request.POST.get('tel'), request.POST.get('pwd')
print(name, tel, pwd)
if User.objects.filter(tel=tel):
msg = "你已经有账号了,请登录"
else:
User.objects.create(name=name, tel=tel, password=pwd)
msg = "注册成功,请登录!"
return render(request, 'login.html', locals())
else:
msg = ""
return render(request, 'register.html', locals())
# 注销
def logout(request):
obj = redirect('index')
obj.delete_cookie('uid')
return obj
# 可视化
@check_login
def plot(request):
"""
"""
uid = int(request.COOKIES.get('uid', -1))
if uid != -1:
username = User.objects.filter(id=uid)[0].name
raw_data = Comment.objects.all()
#1 折线图
main1 = [item.time.strftime('%Y-%m-%d') for item in raw_data]
main1_x = sorted(list(set(main1)))
main1_y = [main1.count(item) for item in main1_x]
###有数据了 把下面注释
# main1_x = [f'2022-03-{i}' for i in range(20, 28)]
# main1_y = [ random.choice(list(range(10,100))) for i in main1_x]
#################
# 2 词频前20
stop = [item.strip() for item in open('hit_stopwords.txt', 'r', encoding='utf-8').readlines()]
stop.extend([item.strip() for item in open('scu_stopwords.txt', 'r', encoding='utf-8').readlines()])
stop.extend([item.strip() for item in open('baidu_stopwords.txt', 'r', encoding='utf-8').readlines()])
stop.extend([item.strip() for item in open('cn_stopwords.txt', 'r', encoding='utf-8').readlines()])
main2_data = Comment.objects.all()
main2_json = {}
for item in main2_data:
text1 = list(jieba.cut(item.content))
for t in text1:
if t in stop or t.strip() == '':
continue
if t not in main2_json.keys():
main2_json[t] = 1
else:
main2_json[t] += 1
result_dict = sorted(main2_json.items(), key=lambda x: x[1], reverse=True) # 最大到最小
main2_x = [item[0] for item in result_dict[:20]]
main2_y = [item[1] for item in result_dict[:20]]
# print(result_dict)
main3_data = [{
"name": item[0],
"value": item[1]
} for item in result_dict]
##### 4 会员比例饼图
main4 = [item.isvip for item in raw_data]
main4_data = [{
'value': main4.count(item),
'name': item
}
for item in set(main4)
]
# 5 商品属性饼图
main5 = [item.goodAttr.split('】')[-1] for item in raw_data]
main5_data = [{
'value': main5.count(item),
'name': item
}
for item in set(main5)
]
# 6 点赞和 评论 散点图
main6_data = [[item.agree,item.comNum] for item in raw_data]
# 7 追评天数饼图
main7 = [item.zhuipingtime for item in raw_data if item.zhuipingtime != None]
main7_data = [{
'value': main7.count(item),
'name': item
} for item in set(main7)
]
return render(request,'plot.html',locals())
####情感分类可视化
@check_login
def qingganPlot(request):
uid = int(request.COOKIES.get('uid', -1))
if uid != -1:
username = User.objects.filter(id=uid)[0].name
# 情感分类饼图
raw_data = Comment.objects.all()
main = [item.emotion for item in raw_data]
main_y = {}
for item in main:
main_y[item] = main_y.get(item, 0) + 1
main = [{
'value': v,
'name': k
} for k, v in main_y.items()]
#1 折线图
raw_data = Comment.objects.all()
# 所有的时间
main1 = [item.time.strftime('%Y-%m-%d') for item in raw_data]
# 时间列表
main1_x = sorted(list(set(main1)))
main1_data = ['正向','负向']
main1_y = []
# 遍历所有的标签
for label in main1_data:
main1_y1 = []
for item in main1_x:
year = int(item.split('-')[0])
month = int(item.split('-')[1])
day = int(item.split('-')[2])
main1_y1.append(raw_data.filter(emotion=label,time__year=year,time__month=month,time__day=day).count())
main1_y.append({
'name': label,
'type': 'line',
'data': main1_y1
})
# print(main1_y)
######
# container2 正向词云图
## 5
stop = [item.strip() for item in open('hit_stopwords.txt', 'r', encoding='utf-8').readlines()]
stop.extend([item.strip() for item in open('scu_stopwords.txt', 'r', encoding='utf-8').readlines()])
stop.extend([item.strip() for item in open('baidu_stopwords.txt', 'r', encoding='utf-8').readlines()])
stop.extend([item.strip() for item in open('cn_stopwords.txt', 'r', encoding='utf-8').readlines()])
main2_data = Comment.objects.filter(emotion='正向')
main2_json = {}
for item in main2_data:
text1 = list(jieba.cut(item.content))
for t in text1:
if t in stop or t.strip() == '':
continue
if t not in main2_json.keys():
main2_json[t] = 1
else:
main2_json[t] += 1
result_dict = sorted(main2_json.items(), key=lambda x: x[1], reverse=True) # 最大到最小
# print(result_dict)
main2_data = [{
"name": item[0],
"value": item[1]
} for item in result_dict]
# 6
main3_data = Comment.objects.filter(emotion='负向')
main3_json = {}
for item in main3_data:
text1 = list(jieba.cut(item.content))
for t in text1:
if t in stop or t.strip() == '':
continue
if t not in main3_json.keys():
main3_json[t] = 1
else:
main3_json[t] += 1
result_dict = sorted(main3_json.items(), key=lambda x: x[1], reverse=True) # 最大到最小
# print(result_dict)
main3_data = [{
"name": item[0],
"value": item[1]
} for item in result_dict]
return render(request,'qingganPlot.html',locals())
# 个人中心
@check_login
def my(request):
uid = int(request.COOKIES.get('uid', -1))
if uid != -1:
username = User.objects.filter(id=uid)[0].name
if request.method == "POST":
name,tel,password = request.POST.get('name'),request.POST.get('tel'),request.POST.get('password1')
User.objects.filter(id=uid).update(name=name,tel=tel,password=password)
return redirect('/')
else:
my_info = User.objects.filter(id=uid)[0]
return render(request,'my.html',locals())
@method_decorator(check_login,name='get') #
class shibieView(View):
def get(self,request):
uid = int(request.COOKIES.get('uid', -1))
if uid != -1:
username = User.objects.filter(id=uid)[0].name
return render(request,'shibie.html',locals())
def post(self,request):
return HttpResponse('post方法')
return JsonResponse({'status':1,'msg':'操作成功'} )
5、源码获取方式
由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看获取联系方式