c语言汉诺塔编码,汉诺塔的非递归实现(C语言版)从栈模拟递归(超详细原理讲解)到格雷码式编码改进(效率极高版)...
7-17 汉诺塔的非递归实现 (25分)
(点击标题自动跳转OJ平台链接)
本文默认读者知道汉诺塔的规则和基本解法,掌握C语言基本语法及编程基础,如有不明白可以留言,欢迎大神提意见。
目录
递归解法(C语言) 执行时间约140ms
模拟递归解法,不使用递归函数(C语言,兼容C++) 执行时间约180ms
非递归解法,栈思想 (C语言,兼容C++) 执行时间约150ms
非递归——压缩编码版本(执行效率是系统递归版的3倍!)执行时间曾快达32ms
汉诺塔的递归思想无非就是将盘子的移动分解成三步规模较小的任务(具体移法在注释中已详细说明)。为了深入浅出,先展示一个递归版本(当然这与题目要求不符,但递归版容易理解)。
递归解法(C语言)
//汉诺塔递归版
#include//解决n个盘从a移到c,其中b为辅助的递归函数
void Hanoi(int n,int a,int b,int c){
if(1==n){ //可以直接移动
printf("%c -> %c\n",a,c);
}else{
Hanoi(n-1,a,c,b); //第一步 1~n-1号盘,从a柱移到b柱上
Hanoi( 1 ,a,b,c); //第二步 直接将n号盘,从a柱移到c柱上
Hanoi(n-1,b,a,c); //第三步 1~n-1号盘,从b柱移到c柱的n号盘上
}
} //其实也可以第二步替换为 printf("%c -> %c\n",a,c); 只是为了描述原理,统一更方便
int main() {
int N;
scanf("%d",&N);
Hanoi(N,'a','b','c');
return 0;
}
若读者学过数据结构,自然知道递归函数的原理是将主函数的所有变量以及断点地址压入系统的递归工作栈中,而关键的变量无非就是Hanoi函数中的n,a,b,c,由于断点地址只能是指向调用子函数的下一条指令用一个step标记断点的代号即可。
系统递归版在PTA的OJ平台上,N=20时的执行时间大约为140ms。
模拟递归解法,不使用递归函数(C语言,兼容C++)
//7-17 汉诺塔的非递归实现 (25分)
#include#include#define MAX_N 20 //测试点3 的N最大,达到20
#define MAX_SIZE MAX_N
typedef struct{
int n,a,b,c;//除了这些函数中的局部变量,系统递归还保存了很多寄存器的值,因为系统不知道那些数据才是关键的,所以只能全部打包保存。
int step; //完成第几步(与系统递归的差别在于,系统保存的是断点地址(下一个要执行的指令地址),由于只可能在递归子函数之后产生,故在模拟中只需设0~3四种状态来模拟断点)
}INFO;
INFO S[MAX_SIZE]; //栈
int top=-1; //栈顶指针
void push(int n,int a,int b,int c,int step){
++top; //保存子函数状态要新开一格栈
#define PUSH_S(x) S[top].x=(x)
PUSH_S(n);
PUSH_S(a);
PUSH_S(b);
PUSH_S(c);
PUSH_S(step);
}
//模拟系统的递归函数。
void Hanoi_Simulation(){
#define SET(x) x=(S[top].x)
int SET(n),SET(a),SET(b),SET(c),SET(step),i=top;
switch(step){ //系统的递归函数是用断点地址直接跳到要执行的那一步,这里用switch模拟。
case 0: //最开始(一步都没完成)
if(1==n){ //可以直接移动
printf("%c -> %c\n",a,c);
break; //正常结束本函数(要--top)
}else{
push(n-1, a,c,b,0); //调用子函数执行第一步
S[i].step++; //记录主函数完成哪一步
return; //注意不能用break; 本函数只是在栈中"休眠"了,跳出去执行子函数罢了。
}
case 1: //完成了第一步
push(1, a,b,c,0); //调用子函数执行第二步
S[i].step++; //记录主函数完成哪一步
return; //跳出去执行子函数
case 2: //完成了第二步
Hanoi(n-1,b,a,c,0); //调用子函数执行第三步
S[i].step++; //记录主函数完成哪一步
return; //跳出去执行子函数
case 3: //看似没啥用,但实际上系统的递归是有这一步的,用于回收本函数占用的资源(--top)
break; //正常结束本函数(要--top)
}
--top; //函数结束,要释放函数占用堆栈中的空间
}
//展示对应的递归版本
void Hanoi(int n,int a,int b,int c){
//对应step=0
if(1==n){ //可以直接移动
printf("%c -> %c\n",a,c);
}else{
Hanoi(n-1,a,c,b); //第一步 1~n-1号盘,从a柱移到b柱上
//对应step=1
Hanoi( 1 ,a,b,c); //第二步 直接将n号盘,从a柱移到c柱上
//对应step=2
Hanoi(n-1,b,a,c); //第三步 1~n-1号盘,从b柱移到c柱的n号盘上
//对应step=3
}
}
int main() {
int N;
scanf("%d",&N);
if(N>MAX_N)return 1; //越界返回非零
push(N,'a','b','c',0); //0表示表示还需要判断n==1,而1则是准备执行到第1步了
while(top>=0){ //栈非空则循环
Hanoi_Simulation();
}
return 0;
}
此模拟系统递归的版本毕竟是邯郸学步,保存主函数状态和恢复断点效率低下(系统是在内核态下借助专用硬件完成这个的),所以比系统的递归效率低多了。但实际上自己写非递归,参考递归的思想,某些变量也是没必要的。说的就是step,这时为了模拟递归子函数后,能回到主函数对应哪一步而设计的。那如果不记录step,如何实现类似递归的效果呢?
(模拟递归版在PTA的OJ平台上,N=20时的执行时间大约为180ms。)
既然只是按照递归的思想,用非递归的解法。那么递归解法中的三个子函数,就对应非递归解法的三个步骤。掌握真正非递归解法,就要用到栈的“先入后出”原理,本来是按一、二、三步顺序执行子函数,但若要一次将三步压入栈中去执行子步骤,要反顺序压入,后压入的到执行时反而先执行,先看如下参考代码。(也是本人最初做此题的解法,当然最初没写详细注释)
非递归解法,栈思想 (C语言,兼容C++)
//7-17 汉诺塔的非递归实现 (25分)
//AC耗时 23m29s
#include#include#define MAX_N 20 //测试点3 的N最大,达到20
#define MAX_SIZE (2*(MAX_N)-1) //恰好能够解决问题的栈容量。
//如N=4时, 栈S最满时的INFO.n分别为[3,1,2,1,1,1,1 ] ;以此类推 N=n时为:[n-1,1,n-2,1,n-3,1,...,3,1,2,1,1,1,1]
typedef struct{
char n,a,b,c;
}INFO;
INFO S[MAX_SIZE]; //栈
int top=-1; //栈顶指针
void push(char n,char a,char b,char c){
++top;
#define PUSH_S(x) S[top].x=x
PUSH_S(n);
PUSH_S(a);
PUSH_S(b);
PUSH_S(c);
}
int main() {
int N;
scanf("%d",&N);
if(N>MAX_N)return 1; //越界返回非零
push(N,'a','b','c'); //初始状态
while(top>=0){
INFO TOP=S[top]; --top; //pop
if(1==TOP.n){ //可以直接移动
printf("%c -> %c\n",TOP.a,TOP.c);
}else{ //注意栈是先入后出的,故入栈顺序和实际操作颠倒
push(TOP.n-1, TOP.b ,TOP.a ,TOP.c); //第三步 1~n-1号盘,从b柱移到c柱的n号盘上
push(1 , TOP.a ,TOP.b ,TOP.c); //第二步 直接将n号盘,从a柱移到c柱上
push(TOP.n-1, TOP.a ,TOP.c ,TOP.b); //第一步 1~n-1号盘,从a柱移到b柱上
}
}
return 0;
}
此版本的执行效率已经接近系统递归的版本了,机试时写出此版本就很不错了。
非递归版在PTA的OJ平台上,N=20时的执行时间大约为150ms。
本人总是想着能不能再精简代码,或者加快执行速度,实际上a,b,c三个变量蕴含的信息量非常小,无非就是'a','b','c'的全排列,只有6种状态,完全可以只用一个char型变量记录下来,但问题的关键在于如何分解成3个步骤,转化为子步骤的状态。
此前本人编过求数独的程序,可以将各种转化状态用数组存起来,不过这么搞又要写很多数组,人为地赋初始值,实在不简洁。但汉诺塔多么有规律的操作,应该存在某种编码方式,使得分解为三步的转化变得非常容易。好了不卖关子了,答案尽在代码中。(就此题机试而言,花时间研究这个编码显然得不偿失,只是锻炼自己思维,在某些复杂和计算量很大的问题,包括哈希算法,需要这类编码的经验)
非递归——压缩编码版本(执行效率是系统递归版的3倍!)
//7-17 汉诺塔的非递归实现 (25分)
#include#define MAX_N 20 //测试点3 的N最大,达到20
#define MAX_SIZE (2*(MAX_N)-1) //恰好能够解决问题的栈容量。如N=4时, 栈S最满时的INFO.n分别为[3,1,2,1,1,1,1 ] ;以此类推 N=n时为:[n-1,1,n-2,1,n-3,1,...,3,1,2,1,1,1,1]
typedef char ELE;
typedef struct{
ELE n,id;
}INFO;
const char T[6][8] = { //6种id对应的操作
"a -> c", // abc 000
"a -> b", // acb 001
"b -> a", // bca 010
"b -> c", // bac 011
"c -> b", // cab 100
"c -> a" // cba 101
};//正则:查找目标" (([abc])[abc]([abc]) )",替换为'\"$2 -> $3\\n\", // $1'
/*
分析:每一步都是讲盘子从 a,b,c中的一根柱移到另一根上,所以有3*2=6种(排列数3选2),所以必然可以用6个编码代表6种移动方案。
关键是如何排列才能很方便地计算分解步骤的状态编码!
以初始状态为"a -> c"为例,第一步需要的是"a -> b",第二步不变还是"a -> c",第三步是"b -> c"。
先考虑第一步,起点不变只改变终点,可以将相同起点编码为相邻id,只需改变最低位(异或0x01)即可映射到第一步所需id;
第二步不变直接照抄;
至于第三步,终点不变换起点,同样是两种状态循环,那一共6种状态,不妨试试循环后移3格,abc变为bac则把bac设为id=3,类似格雷码,相邻两个id对应的排列都只交换两个字母(格雷码是改变其中1bit的0或1),很巧妙的发现,其对应id不过是循环后移(前移)3格。
*/
INFO S[MAX_SIZE]; //栈
int top=-1; //栈顶指针
void push(ELE n,ELE id){
S[++top].n=n;
S[top].id=id;
}
int main() {
int N;
scanf("%d",&N);
push(N,0); //abc
while(top>=0){
int n=S[top].n;
int id=S[top].id;
--top; //pop
if(1==n){ //可以直接移动
puts(T[id]);
}else{
push(n-1, (id+3)%6);//第三步 1~n-1号盘,从b柱移到c柱的n号盘上
push(1 , id); //第二步 直接将n号盘,从a柱移到c柱上
push(n-1, (1^id)); //第一步 1~n-1号盘,从a柱移到b柱上
}
}
return 0;
}
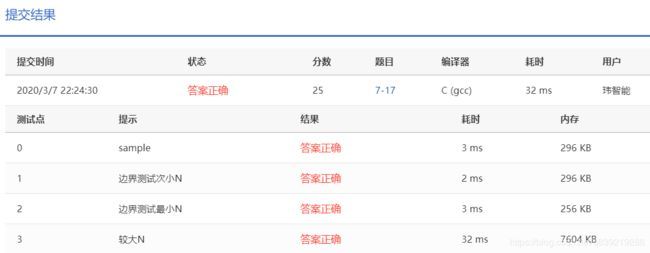
此版本还是得写个6格的字符串数组,代码量肯定没有能胜过系统递归的。但此版本执行速度非常棒!如下图曾经试过32ms!
本文如有不当之处欢迎各位大佬指正或分享经验。若有同学想提问的,可以留言,有空我会给出自己的解释,甚至再增加更丰富的图文解释在文中哦。