快速排序(四)——挖坑法,前后指针法与非递归
目录
一.前言
二.挖坑法
三.前后指针法
四.递归优化
五.非递归
六.结语
一.前言
本文我们接着上篇文章的重点快排,现在继续讲解对快排优化的挖坑法,前后指针法以及非递归方法,下面是上篇文章快排链接:https://mp.csdn.net/mp_blog/creation/editor/135719674。
码字不易,希望大家多多支持我呀!(三连+关注,你是我滴神!)
二.挖坑法
其实挖坑法很简单,因为它只是在hoare的基础上优化了一部分,就比如不用去纠结为什么key在右边时,右边先走。这里因为坑设定在第一位,所以自然要从右边找数去填坑。
因此这里面的循环逻辑就变得很简单,右找小(填左边坑),自己变成新坑,左找大(填右边坑),自己变新坑,就这样以此类推最后一定会相遇,而这个相遇的位置一般就是我们的居中值(三数取中法),最后把key放入即可。
int PartSort2(int* a, int left, int right) { int midi = GetMidi(a, left, right); Swap(&a[left], &a[midi]); //通过三数取中把位于最左边的居中数给key int key = a[left]; //保存key值后,左边形成第一个坑位 int hotel = left; //left与right不断相遇 while (left < right) { //右边先走,找小;找到后把值放到左边坑位中,右边形成新的坑位 while (left < right && a[right] >= key) { right--; } a[hotel] = a[right]; hotel = right; //左边开始走,找大;找到后把值放到右边坑位中,左边形成新的坑位 while (left < right && a[left] <= key) { left++; } a[hotel] = a[left]; hotel = left; } //最后二者相遇,并且其中一个必定是坑位 //将key放入坑位中 a[hotel] = key; return hotel; }挖坑法由于有了前面hoare的铺垫,所以我们可以更简洁明了地写出代码,也更通俗易懂,但这些前提都是要理解hoare的核心,这样才能写出优化的挖坑法。
三.前后指针法
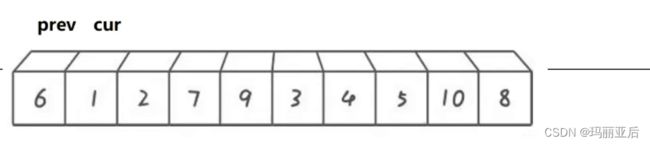
前后指针法写起来甚至比挖坑法更简单,因为它就只有一个核心点:
cur找比key小的数,prev++,交换prev与cur的值
而prev只有两者情况:
- 在cur没遇到比key大的值的时候,prev紧紧跟着cur(重合)
- 在cur遇到比key大的值的时候,prev在比key大的一组值的前面
这样就会出现一种情况,比key大的值会阻扰prev的前进,但只要cur再次找到比key小的值两者就会交换,prev就像是不断地推着比key大的值往后排。
3与7交换
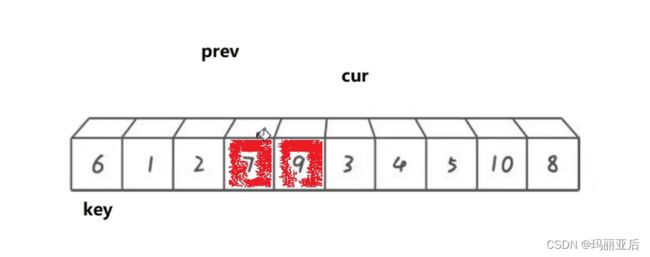
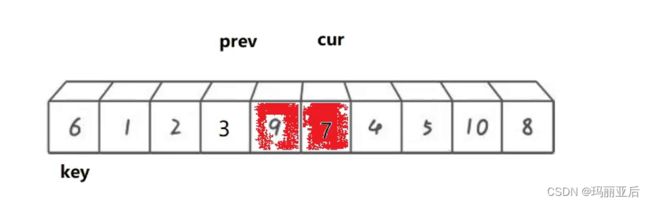
9与4交换
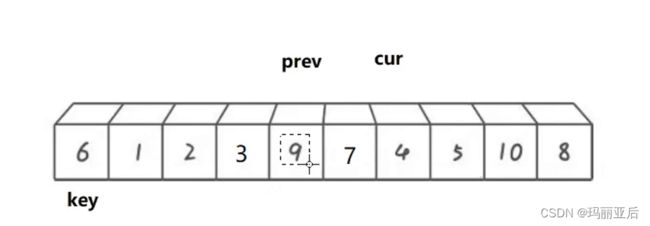
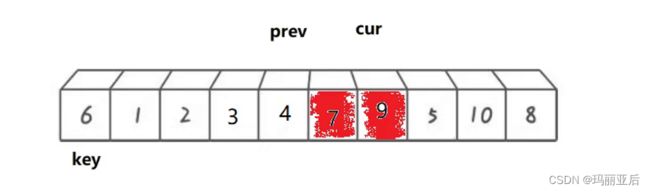
就这样持续到cur走出数组,这时可以看到prev的指向数是比key小的,最后prev与key进行交换。

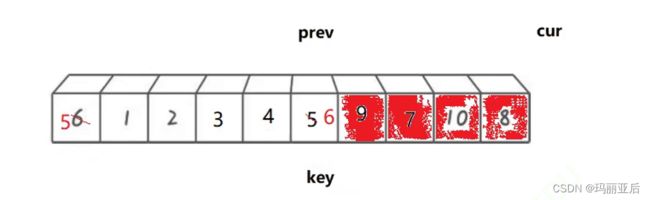
写代码我们要注意一个地方,就是记得要在cur找小的时候添加一个条件,如果该趟找不到小的已经越界了就及时退出,否则prev就会继续++,打乱了key的正确位置。
int PartSort3(int* a, int left, int right)
{
int midi = GetMidi(a, left, right);
Swap(&a[left], &a[midi]);
int key = left;
int prev = left;
int cur = prev + 1;
while (cur <= right)
{
//找小
while (cur<=right&&a[cur] >= a[key])
{
cur++;
}
//当找不到小时
if (cur > right)
{
break;
}
else
{
prev++;
Swap(&a[prev], &a[cur]);
}
}
Swap(&a[key], &a[prev]);
return key;
}还有一种写法,我们可以观察到cur无论是找小还是找不到小都会++,那不妨可以这样写:
int PartSort3(int* a, int left, int right)
{
int midi = GetMidi(a, left, right);
Swap(&a[left], &a[midi]);
int key = left;
int prev = left;
int cur = prev + 1;
while (cur <= right)
{
if (a[cur] < a[key])
{
prev++;
Swap(&a[prev], &a[cur]);
}
cur++;
}
Swap(&a[key], &a[prev]);
return key;
}注意!这两个优化的方法并不能提高快排的算法效率,只是思想上的优化,便于我们更好理解而已。
四.递归优化
我们再来处理优化递归的问题:
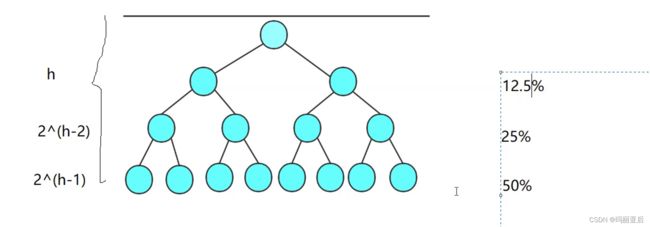
满二叉树最后一层节点会占总节点的50%,因为一共有2^h-1个节点,最后一层有2^(h-1)个
对比到快排的递归而言,为了让这10个数有序而走了那么多次递归有点不划算。
那如果10个数我们不用递归而采用直接插入法的话可以效率可以提高80%-90%,因为递归最后三层的消耗占据很多,在处理数量级小的情况下会很浪费。


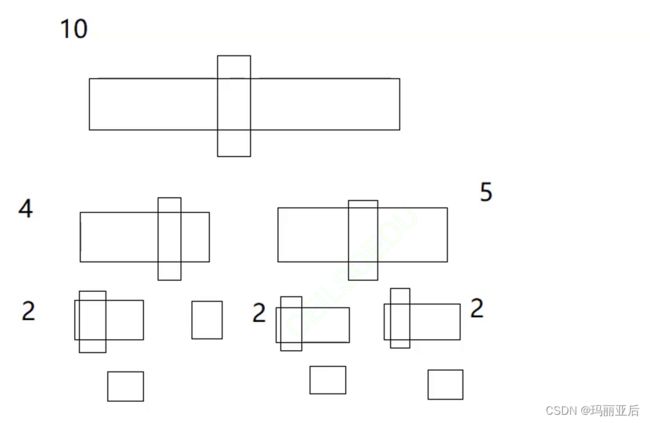
代码部分:
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
{
return;
}
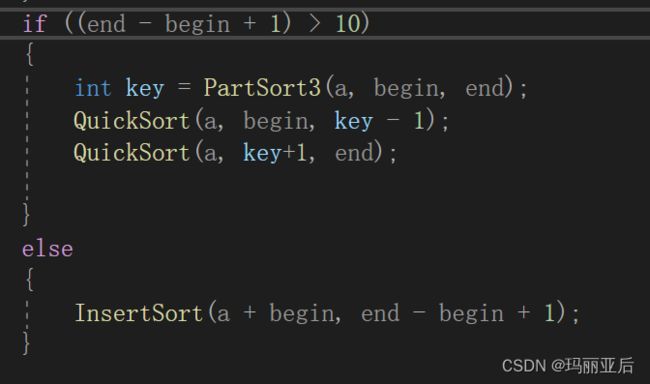
if ((end - begin + 1) > 10)
{
int key = PartSort3(a, begin, end);
QuickSort(a, begin, key - 1);
QuickSort(a, key+1, end);
}
else
{
InsertSort(a + begin, end - begin + 1);
}
}

这是最精妙的一步(小区间优化,小区间不再递归分割排序,降低递归次数),由于我们在不断递归的过程中那些后面被分割的许多个小组序列会占据大多数空间,所以我们统一划定一个标准,只要是小于10个的范围都直接插入法去解决,又因为我们划分的无数个子树都对应原数组不同的位置,那我们就分别用[begin,end]来规定它们,当我们用到直接插入排序时,只要在原数组地址加上begin就可以对应到自己的位置。
五.非递归
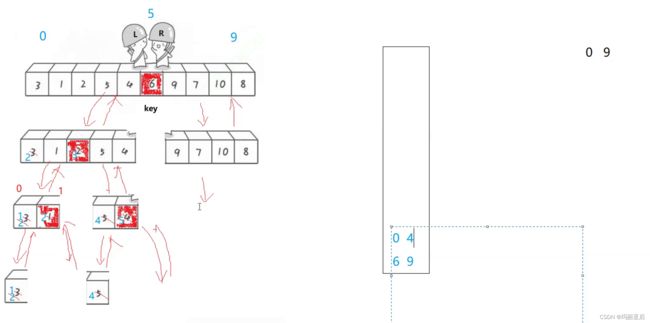
非递归的关键就是能够控制与保存区间——借助栈
我们先把数组的范围录入栈中
找到key的下标后把0-9取出,录入我们的右区间6-9
再把左区间0-4录入
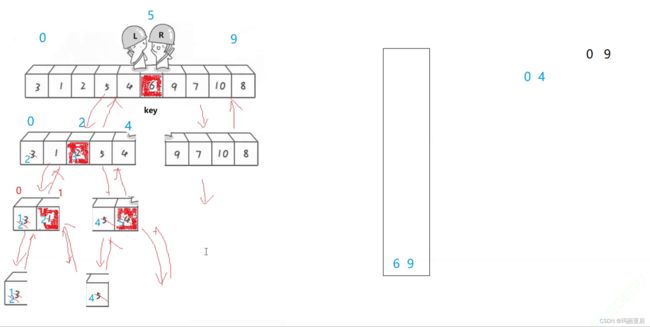
之所以先入右再入左是因为这样可以先把左区间给取出来(栈的特点),然后下一次循环栈不为空则取出左区间走,0-4走完单趟选出key后继续分割
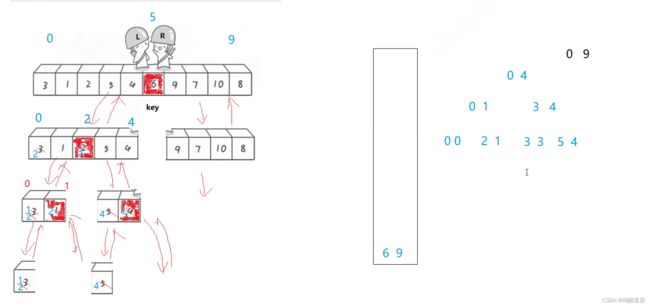
0-4分割成0-1与3-4,我们再把它们分别录入栈中。
再把0-1取出来选出key为1后分割成0-0与2-1(2-1说明这里已经没有数了,也可以参考范围[key+1,end],)而这两个区间也不用继续入栈了(没啥好分的了)。
我们可以发现这就是递归的过程,只不过我们需要用栈以非递归的形式实现
接着我们取出3-4进行分割,然后按照区间规则它分出的两区间不用再入栈了。
就这样以此类推直到栈为空结束。



void QuickSortNonR(int* a, int begin, int end)
{
ST st;
STInit(&st);
//入栈,先入右,如9
STPush(&st, end);
//再入左,如0
STPush(&st, begin);
while (!STEmpty(&st))
{
//准备出栈,获取栈顶元素,如0
int left = STTop(&st);
//出栈,如0
STPop(&st);
//准备出栈,获取栈顶元素,如9
int right = STTop(&st);
//出栈,如9
STPop(&st);
//通过获取的元素构成范围来寻找key,【0-9】
int key = PartSort3(a, left, right);
//[left,key-1]key[key+1,right]
//对范围如【0-9】进行分割,先入栈右区间再入栈左区间
//准备入6-9
//判断区间合理性,等于或大于不能放
if (key + 1 < right)
{
STPush(&st, right);//如入9
STPush(&st, key+1);//如入6
}//6-9已经录入
//同理把0-5录入
if (left < key - 1)
{
STPush(&st, key-1);//如入5
STPush(&st, left);//如入0
}
//现在第一层结束后栈顶由上到下就是0 5 6 9
//至此由第一层分割的范围录入结束,后面就是判断栈里是否为空(还有没有范围)
//如果栈不为空则继续执行这个循环,直到为空的时候,非递归也就完成了。
}
}栈相关代码:对于栈功能还不熟悉的友友也可以移步我的这篇文章学习一下:https://mp.csdn.net/mp_blog/creation/editor/133249808
#include "Stack.h"
void STInit(ST* ps)
{
assert(ps);
ps->a = NULL;
ps->capacity = 0;
ps->top = 0;
}
void STDestroy(ST* ps)
{
assert(ps);
free(ps->a);
ps->a = NULL;
ps->top = ps->capacity = 0;
}
void STPush(ST* ps, STDataType x)
{
assert(ps);
// 11:40
if (ps->top == ps->capacity)
{
int newCapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;
STDataType* tmp = (STDataType*)realloc(ps->a, sizeof(STDataType) * newCapacity);
if (tmp == NULL)
{
perror("realloc fail");
exit(-1);
}
ps->a = tmp;
ps->capacity = newCapacity;
}
ps->a[ps->top] = x;
ps->top++;
}
void STPop(ST* ps)
{
assert(ps);
//
assert(ps->top > 0);
--ps->top;
}
STDataType STTop(ST* ps)
{
assert(ps);
//
assert(ps->top > 0);
return ps->a[ps->top - 1];
}
int STSize(ST* ps)
{
assert(ps);
return ps->top;
}
bool STEmpty(ST* ps)
{
assert(ps);
return ps->top == 0;
} 六.结语
六.结语
本文整体上是对快排进行的优化,让它的性能更加强大,另外也帮助我们在掌握好递归的同时也能运用好非递归。最后感谢大家的观看,友友们能够学习到新的知识是额滴荣幸,期待我们下次相见~